整网数据比对
使用场景
排除以上问题后,在训练网络精度仍未达预期时,通过采集训练过程中各算子的运算结果(即Dump数据),然后和业界标准算子(如TensorFlow)运算结果进行数据偏差对比,快速定位到具体算子的精度问题。主要过程为:
前提条件
基于GPU/CPU Dump标杆数据
利用TensorFlow官方提供的debug工具tfdbg,在CPU/GPU训练脚本中添加tf_debug代码,并使用precision_tool中提供的辅助命令行工具生成npy文件。
以下操作在GPU/CPU训练环境执行。
- 在GPU/CPU训练环境安装python3三方依赖。
pip3 install gnureadline pexpect
- 修改原始训练脚本,使能标杆数据采集。Dump标杆数据的原理是使用tf_debug的print_tensor(pt)命令实现的,由于训练代码提供了非常灵活的run()接口,脚本无法感知用户需要dump的tensor在哪个run阶段,因此需要用户修改训练代码,在执行完一个step后立即退出,否则可能会导致后续精度比对异常。
# 引用precision_tool/tf_config.py import precision_tool.tf_config as npu_tf_config # 如果使用的是Estimator,EstimatorSpec加入training_hooks # 等价于:estim_specs = tf_debug.DumpingDebugHook("precision_data/tf/tf_debug") estim_specs = tf.estimator.EstimatorSpec(training_hooks=[npu_tf_config.estimator_dump()]) # 如果使用的session.run,以下代码为sess加上了tf_debug的wrapper # 等价于:sess = tf_debug.DumpingDebugWrapperSession(sess, "precision_data/tf/tf_debug") sess = npu_tf_config.sess_dump(sess=sess) - 执行GPU/CPU训练。
根据代码中run的次数,会在precision_data/tf/tf_debug/目录生成1~N个离线tf_debug的dump目录。
- 使用precision_tool中提供的辅助命令行自动解析tf debug的Dump文件,生成算子输出tensor文件。
python3 precision_tool/cli.py tf_dump
- 在precision_data/tf/dump/目录下会生成提取的tensor。
如果需要重新生成dump数据,可执行以下命令:
rm -rf precision_data/tf/dump/* && python3 precision_tool/cli.py tf_dump
基于NPU Dump精度数据
以下操作在NPU训练环境执行,Dump数据前需要注意:
一般情况下,dump首个step的数据用作后续比对分析即可,为了避免随机权重导致比对不准确的问题,可以在训练开始前保存ckpt,并在训练时加载。如果确定是某个step的精度问题,则建议加载最靠近异常step的ckpt文件。
- 修改工具precision_tool/lib/config目录下的config.py,指定需要dump数据的step。
# dump特定step的数据,一般对比分析dump首层即可,即保持默认值,如需指定特定step可以修改,例如 '0|5|10' TF_DUMP_STEP = '0'
- 修改训练脚本,使能Dump数据采集。以下修改会同时生成Dump数据和Dump图,用于精度数据比对。
# 引用precision_tool/tf_config.py import precision_tool.tf_config as npu_tf_config # 1. 手工迁移网络 # 1.1 Estimator方式 dump_config=npu_tf_config.estimator_dump_config(action='dump') npu_config = NPURunConfig(dump_config=dump_config) # 1.2 Session run方式 config = npu_tf_config.session_dump_config(config, action='dump') sess = tf.Session(config) # 2. 自动迁移网络 # 若脚本中未配置custom_op,则在脚本中新增如下粗体语句 session_config = npu_tf_config.session_dump_config(session_config, action='dump') # 若脚本中已配置custom_op,如下所示,则在脚本中新增下列粗体语句更新custom_op custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = 'NpuOptimizer' custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision") custom_op = npu_tf_config.update_custom_op(custom_op, action='dump') # 2.1 Estimator方式 run_config = tf.estimator.RunConfig(session_config=session_config,...) # 2.2 Session run方式 with tf.Session(config=npu_config_proto(session_config)): .... # 2.3 tf.keras方式 npu_keras_sess = set_keras_session_npu_config(config=session_config) - 执行训练,会在precision_data/npu/debug_0目录下分别保存GE的Dump图和Dump数据文件。
精度数据比对
精度数据分析依赖CANN Toolkit软件包中的atc工具和msaccucmp.py工具,以下操作需要在CANN开发环境,即Toolkit安装环境进行。
- 将precision_tool和precision_data(包括标杆数据和NPU的精度数据)文件夹上传到Toolkit安装环境的任意目录下,目录结构示例:
├── precision_tool │ ├── cli.py │ ├── ... ├── precision_data │ ├── npu │ │ ├── debug_0 // 存放npu dump数据 │ ├── tf │ │ ├── dump // 存放标杆dump数据
- 安装python3三方依赖。
# graphviz为可选依赖,只有当需要绘制算子子图时才需要安装 pip3 install rich graphviz # ubuntu/Debian sudo apt-get install graphviz # fedora/CentOS sudo yum install graphviz
- 修改工具precision_tool/lib/config目录下的config.py。
# 依赖Toolkit包中的atc和msaccucmp.py工具,配置为Toolkit包安装目录 # 默认Toolkit包安装在/usr/local/Ascend,可以不用修改,指定目录安装则需要修改 CMD_ROOT_PATH = '/usr/local/Ascend'
- 启动PrecisionTool交互命令行。
python3 ./precision_tool/cli.py
进入交互命令行界面:
PrecisionTool >

如需退出,可执行ctrl + c。
- 执行ac -l [limit_num] (-c)命令进行整网精度比对。
PrecisionTool > ac -c
根据数据量大小,比对过程需要时间不同。
对比结果会以csv的格式存放在precision_data/temp/vector_compare目录中:
您可以直接打开csv文件进行分析,具体请参考整网精度比对结果文件说明。
- 除了直接打开csv文件进行精度分析外,您也可以使用vcs -f [file_name] -c [cos_sim_threshold] -l [limit]命令筛选比对结果。
vcs命令默认筛选余弦相似度小于0.98的结果,您也可以通过-c参数自定义阈值:
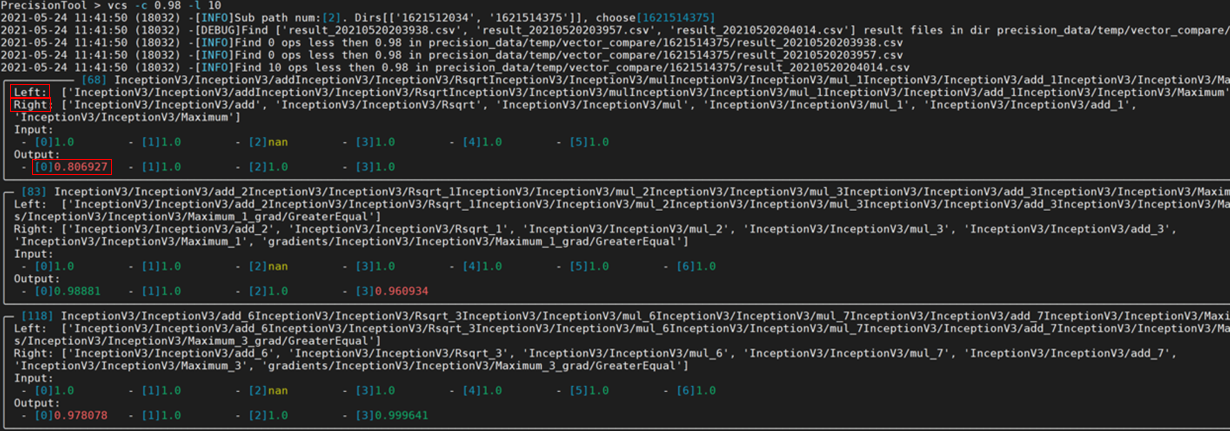
- Left:表示基于NPU运行生成的dump数据的算子名。
- Right:表示基于GPU/CPU运行生成的npy或dump数据的算子名。
- Input和Output:表示该算子各输入输出的余弦相似度算法比对结果,范围是[-1,1],比对的结果如果越接近1,表示两者的值越相近,越接近-1意味着两者的值越相反。
从上图的比对结果可以看到,算子的输入基本一致,但第一个输出与标杆存在明显差异(余弦相似度为0.806927,小于0.98),说明该算子可能存在精度问题。
当出现多个算子精度问题时,会出现N个异常算子信息,默认按照算子执行顺序排序,由于后面算子精度问题可能是因为前一个算子精度问题导致,建议用户优先分析第一个异常算子。
- 执行ni (-n) [op_name] -g [graph] -a [attr] -s [save sub graph deep]命令,可以查询异常算子的节点信息。

ni命令可以根据传入的算子名称,得到如下关键信息:
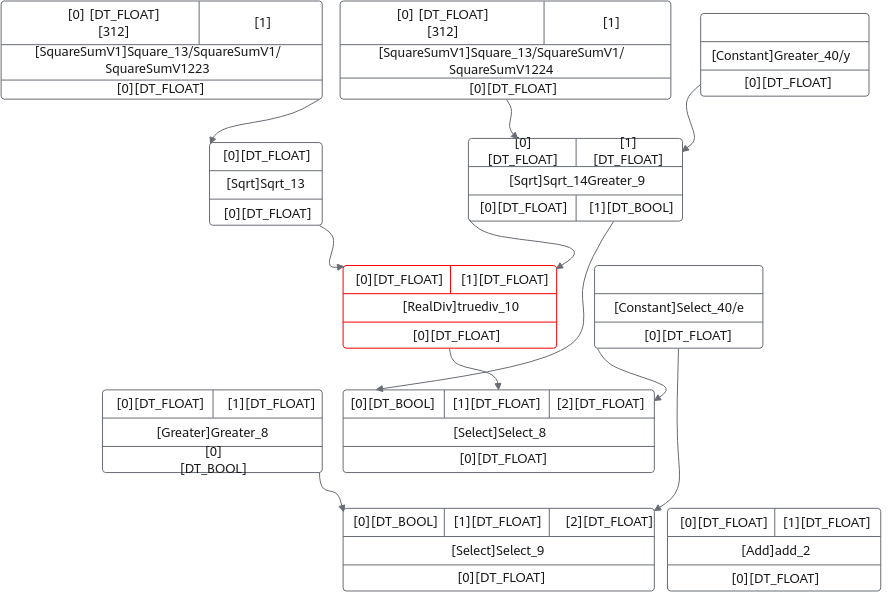
- 算子类型,以上图为例,算子类型为Add。
另外,PassName表示该算子为融合算子,对应值表示融合规则名称,OriginOp为融合前的算子,表明是由于算子融合导致精度问题。正常情况下,融合问题应该在融合异常检测阶段解决。
- 自动解析Dump数据,打印Dump数据的基础信息(max/min/mean)。
- 如果传入-s,则会保存一个以当前算子为中心,指定深度的子图结构,例如:
- 算子类型,以上图为例,算子类型为Add。
分析思路参考
整网数据比对提供了一个全网Dump数据与TensorFlow标杆数据的逐层累计比对报表,由于整网数据由于硬件差异本身是存在一定给误差的,且误差会随着层数增多而累计,即便精度正常的网络数值上也会存在细微误差,一般采用余弦相似度做初步的可疑算子筛选(注意:余弦相似度较高也不一定说明没有问题,但较低一般代表可能存在问题),精度对比结果可以给出一个大致的分析方向。
- 根据算子类型,可以判断该算子是否为用户自定义算子:
- 对于自定义算子,一般由用户自行分析算子的实现逻辑是否与标杆一致,可以根据ni (-n) [op_name] -g [graph] -a [attr] -s [save sub graph deep]命令提供的算子参数信息,以及dump数据进行单算子分析。
- 对于CANN内置算子,如果算子输入或输出类型为float16,则可以切换算子类型至float32计算,用户可以尝试以下两种方法:
- (推荐)方法一:修改混合精度模式算子黑白灰名单,调整算子精度模式,请参考修改混合精度黑白灰名单。
- 方法二:通过keep_dtype_scope接口,指定哪些算子保持原有精度。
from npu_bridge.npu_init import * with npu_scope.keep_dtype_scope(): y = tf.mul(x1,x2)
- 如果依旧无法解决,欢迎到昇腾社区提issue求助。