学习向导
描述本手册的读者对象,TensorFlow 1.15模型开发的全流程,以及使用本手册的一些注意点。
读者对象
本文档适用于AI算法工程师,用于将基于TensorFlow 1.15的Python API开发的训练脚本迁移到昇腾AI处理器上执行训练,并达到训练精度性能最优。当前昇腾AI处理器上支持TensorFlow 1.15的三种API开发的训练脚本迁移:分别是Estimator,Sess.run,Keras。
掌握以下经验和技能可以更好地理解本文档:
- 熟悉CANN软件基本架构以及特性。
- 熟练的Python语言编程能力。
- 熟悉TensorFlow 1.15的API。
- 对机器学习、深度学习有一定的了解,熟悉训练网络的基本知识与流程。
支持的产品型号
Atlas 训练系列产品
Atlas A2 训练系列产品
Atlas 推理系列产品(仅支持TensorFlow 1.15在线推理特性)
使用前须知
- 在昇腾AI处理器进行模型迁移之前,建议用户事先准备好基于TensorFlow 1.15开发的训练模型以及配套的数据集,并要求在GPU或CPU上跑通,精度收敛,且达到预期精度和性能要求。同时记录相关精度和性能指标,用于后续在昇腾AI处理器进行精度和性能对比。
- 本文中的代码片段仅为示例,请用户使用时注意修改适配。
模型开发向导
模型开发的主要工作就是将TensorFlow原始模型迁移到昇腾AI处理器上并执行训练,主要流程如下图所示。
图1 TensorFlow模型开发流程
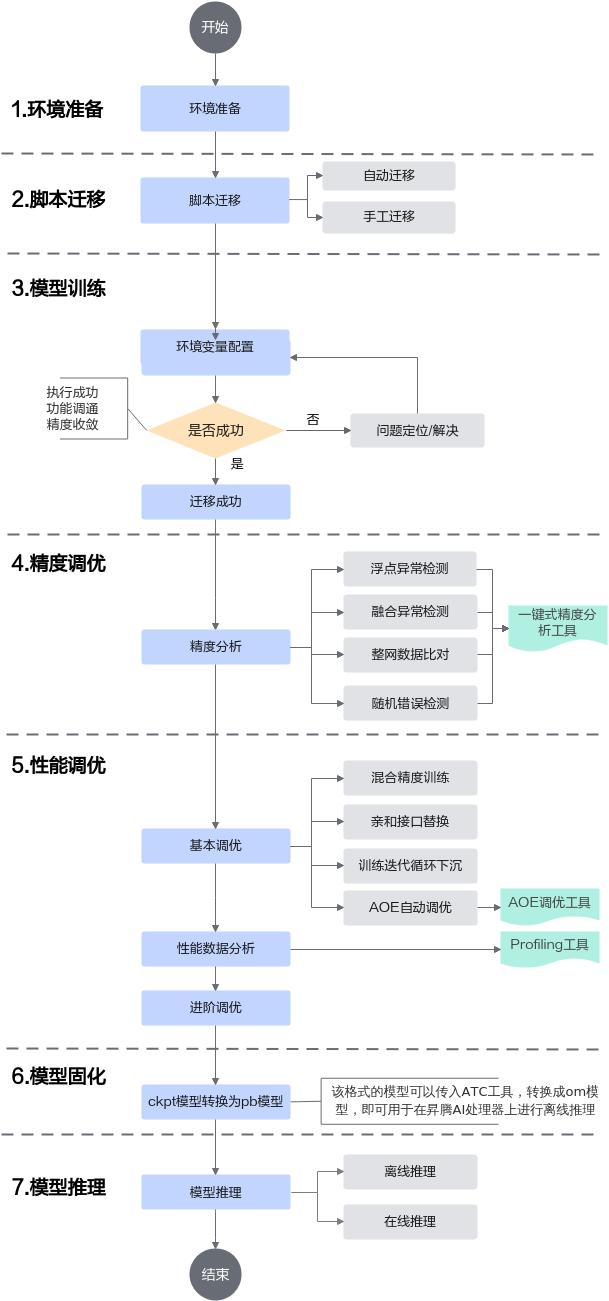
迁移方式比较
将基于TensorFlow的Python API开发的训练脚本迁移到昇腾AI处理器上执行训练,目前有两种迁移方式,用户可任选其一: