Loss Scale
概述
在混合精度计算中,使用float16数据格式时数据的动态范围会降低,造成梯度计算出现浮点溢出,从而导致部分参数更新失败。为了保证部分模型训练在混合精度训练过程中收敛,需要配置loss scale的方法。
Loss scale方法通过在前向计算所得的loss乘以loss scale系数S,起到在反向梯度计算过程中达到放大梯度的作用,从而最大程度规避浮点计算中较小梯度值无法用FP16表达而出现的溢出问题。在参数梯度聚合之后以及优化器更新参数之前,将聚合后的参数梯度值除以loss scale系数S还原。
动态Loss scale通过在训练过程中检查梯度中浮点计算异常状态,自动动态选取loss scale系数S以适应训练过程中梯度变化,从而解决人工选取loss scale系数S和训练过程中自适应调整的问题。
在具体实现中:
针对Atlas 训练系列产品,浮点计算溢出模式默认为“饱和模式”且仅支持“饱和模式”(即计算出现溢出时,计算结果会饱和为浮点数极值(+-MAX)。
针对Atlas A2 训练系列产品,浮点计算溢出模式支持饱和模式与INF/NAN模式,请保持默认值INF/NAN模式。饱和模式仅用于兼容旧版本,后续不再演进,且此模式下计算精度可能存在误差。
- 浮点计算的溢出模式为“饱和模式”的场景下,昇腾AI处理器由于浮点计算特性不同,在计算过程中的浮点异常检查等部分与GPU存在差异,此种场景下,开发者需要参考本章节开启loss scale功能或者基于原有loss scale功能迁移脚本。
- 浮点计算的溢出模式为“INF/NAN模式”的场景下,开发者使用TensorFlow原生的loss scale功能即可,无需参考本节做功能迁移。当然,若您参考已参考本节进行了loss scale功能的迁移,您的网络脚本仍可正常运行。
实现原理
- 动态loss scale的主要计算流程。
- 维护一个float32的主参数版本。
- 将loss scale系数S初始化为一个较大值。
- 在每次迭代中:
- 从float32的主参数版本中通过精度转换cast出一份float16的参数版本供本次迭代计算使用。
- 前向计算获得loss。
- 将loss乘以当前loss scale系数S。
- 反向计算获得梯度。
- 分布式训练场景下进行梯度聚合操作。
- 检查梯度,当存在inf/nan时,减小loss scale系数S,不进行参数更新结束本次迭代。
- 将梯度乘以1/S还原。
- 通过优化器更新参数。
- 如果在最近N次迭代未发现inf/nan,则增加loss scale系数S。N为可配置项。
图1 动态Loss Scale的主要计算流程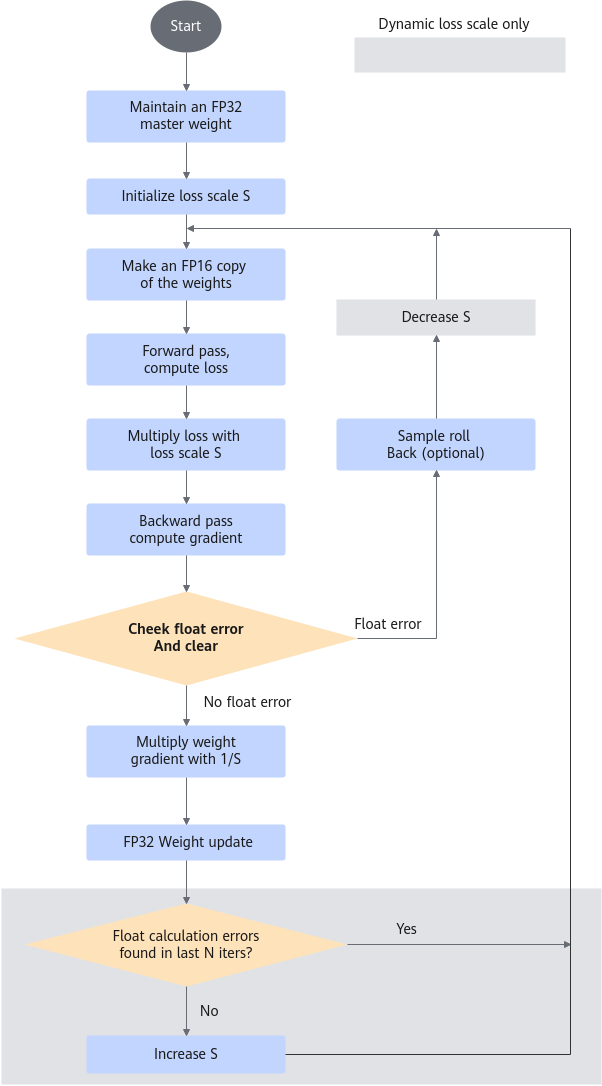
使用Loss Scale
- 自动迁移场景
如果原始网络中使用了loss scale功能,使用工具自动迁移的场景下,工具会自动将TensorFlow的LossScaleManager迁移为NPU的ExponentialUpdateLossScaleManager或FixedLossScaleManager。如果原始网络中没有使用loss scale功能,用户可以根据需要参考本节自行添加。
- 手工迁移场景
如果原始网络中使用了loss scale功能,需要将LossScaleOptimizer迁移为NPULossScaleOptimizer或NPUOptimizer构造函数,下面仅以NPULossScaleOptimizer举例说明。
- 静态loss scale:用户可定义在混合精度训练过程中使用固定的loss scale系数。
具体做法是,在创建NPULossScaleOptimizer之前,实例化一个FixedLossScaleManager类进行指定loss scale的值。
- 动态loss scale:用户可定义在混合精度训练过程中根据浮点计算异常状态调整loss scale系数。
具体做法是,在创建NPULossScaleOptimizer之前,实例化一个ExponentialUpdateLossScaleManager类进行动态loss scale的配置。

ExponentialUpdateLossScaleManager类对象的构造不能在tf.control_dependencies()接口的作用域内,否则可能会造成图结构执行顺序与预期不一致,详细可参见NPULossScaleOptimizer优化器使用常见问题。
另外,分布式训练场景下,如果使用了NPULossScaleOptimizer,必须将is_distributed配置为True,以支持分布式训练场景下loss scale功能。单卡场景下,NPULossScaleOptimizer的is_distributed必须保持默认值False,否则会导致训练异常。
TensorFlow原始代码:
1 2 3 4 5 6 7 8 9
if FLAGS.use_fp16 and (FLAGS.bert_loss_scale not in [None, -1]): opt_tmp = opt if FLAGS.bert_loss_scale == 0: loss_scale_manager = tf.contrib.mixed_precision.ExponentialUpdateLossScaleManager(init_loss_scale=2**32, incr_every_n_steps=1000, decr_every_n_nan_or_inf=2, decr_ratio=0.5) elif FLAGS.bert_loss_scale >= 1: loss_scale_manager = tf.contrib.mixed_precision.FixedLossScaleManager(loss_scale=FLAGS.bert_loss_scale) else: raise ValueError("Invalid loss scale: %d" % FLAGS.bert_loss_scale) opt = tf.contrib.mixed_precision.LossScaleOptimizer(opt_tmp, loss_scale_manager)
迁移后的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from npu_bridge.npu_init import * if FLAGS.use_fp16 and (FLAGS.bert_loss_scale not in [None, -1]): opt_tmp = opt if FLAGS.bert_loss_scale == 0: loss_scale_manager = ExponentialUpdateLossScaleManager(init_loss_scale=2**32, incr_every_n_steps=1000, decr_every_n_nan_or_inf=2, decr_ratio=0.5) elif FLAGS.bert_loss_scale >= 1: loss_scale_manager = FixedLossScaleManager(loss_scale=FLAGS.bert_loss_scale) else: raise ValueError("Invalid loss scale: %d" % FLAGS.bert_loss_scale) #device数是否大于1,如果大于1,进行分布式训练 if ops_adapter.size() > 1: opt_tmp = npu_distributed_optimizer_wrapper(opt_tmp) opt = NPULossScaleOptimizer(opt_tmp, loss_scale_manager, is_distributed=True) else: opt = NPULossScaleOptimizer(opt_tmp, loss_scale_manager)
另外,如果原始代码中没有使用loss scale,可以找到优化器名称后补充如下代码(以使用静态loss scale为例):
1 2 3
loss_scale_manager = FixedLossScaleManager(loss_scale=1024) optimizer=NPULossScaleOptimizer(optimizer,loss_scale_manager) optimizer=optimizer.minimize(self.loss)
- 静态loss scale:用户可定义在混合精度训练过程中使用固定的loss scale系数。
由于NPU计算特性与GPU混合精度计算特性存在差异,LossScaleManager超参也往往需要进行适当的调整以保证精度。当用户模型基于默认loss scale参数训练产生溢出的迭代过多,影响最终精度时,需要对loss scale参数进行适当调整,减少发生浮点异常的次数。
具体方法为:参考打印loss scale值打印loss scale值,根据loss scale值观察溢出次数,调整LossScaleManager参数。
更新global step
在开启loss scale后,需要丢弃loss scale溢出的step,具体需要看使用的优化器的更新step逻辑:
- 大多数情况下,比如resnet50HC网络中本来用的tf.train.MomentumOptimizer优化器,它更新global step就是在apply_gradients中处理的,此时能保证溢出时不更新step,因此不需要进行脚本改造。
- 但是,比如Bert网络,更新global step是在create_optimizer里面实现的,包括判断逻辑,此时需要将更新global step放在优化器进行。具体迁移示例如下:
TensorFlow原始代码中,更新global step是在create_optimizer里面实现的,包括判断逻辑:
1 2 3 4 5 6 7 8 9 10 |
def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, hvd=None, manual_fp16=False, use_fp16=False, num_accumulation_steps=1, optimizer_type="adam", allreduce_post_accumulation=False): ... if tf.flags.FLAGS.npu_bert_clip_by_global_norm: new_global_step = tf.cond(all_are_finite, lambda: global_step + 1, lambda: global_step) else: new_global_step = global_step + 1 new_global_step = tf.identity(new_global_step, name='step_update') train_op = tf.group(train_op, [global_step.assign(new_global_step)]) return train_op |
迁移到Ascend平台时,需要将更新global step放在优化器进行:
- 将脚本中create_optimizer里面实现的global step更新逻辑注释掉:
1 2 3 4 5 6 7 8 9 10
def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, hvd=None, manual_fp16=False, use_fp16=False, num_accumulation_steps=1, optimizer_type="adam", allreduce_post_accumulation=False): ... #if tf.flags.FLAGS.npu_bert_clip_by_global_norm: # new_global_step = tf.cond(all_are_finite, lambda: global_step + 1, lambda: global_step) #else: # new_global_step = global_step + 1 #new_global_step = tf.identity(new_global_step, name='step_update') #train_op = tf.group(train_op, [global_step.assign(new_global_step)]) return train_op
- 分别在AdamWeightDecayOptimizer和LAMBOptimizer类的apply_gradients函数最后return之前增加更新global step的逻辑,LossScale只有状态检查未溢出时才会调用apply_gradients:
1 2 3 4 5 6 7 8 9
def apply_gradients(self, grads_and_vars, global_step=None, name=None, manual_fp16=False): assignments = [] for (grad, param) in grads_and_vars: ... new_global_step = global_step + 1 new_global_step = tf.identity(new_global_step, name='step_update') assignments.extend([global_step.assign(new_global_step)]) return tf.group(*assignments, name=name)
打印loss scale值
Estimator模式下,可以通过添加hook的方式实现对loss scale值进行打印:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
class _LogSessionRunHook(tf.train.SessionRunHook): def before_run(self, run_context): return tf.estimator.SessionRunArgs( fetches=['loss_scale:0']) def after_run(self, run_context, run_values): print('loss scale value=%d' % run_values.results[0], flush=True) ... if 'train' in params.exec_mode: training_hooks = get_hooks(params, logger) training_hooks.append(_LogSessionRunHook()) estimator.train( input_fn = dataset.train_fn, steps = max_steps, hooks = training_hooks) |
需要注意的是,以上hook无法适用所有网络,原因是loss scale值是根据算子名称打印的,如果用户使用了scope等指定网络中部分算子的名称,则该hook需要相应更改为需要获取的算子名称。
sess.run模式下,可以通过调用get_loss_scale接口从NPU的lossscale优化器获取loss scale的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 原始代码示例 for step in range(restore_step, FLAGS.max_steps): data = next(data_generator) inputs_padded = data[0] bbox_padded = pad_bbox(data[1],FLAGS.num_bbox) input_image_np = inputs_padded input_bbox_np = bbox_padded ml, tl,ce_loss, bbox_loss, _, summary_str = sess.run([ model_loss, total_loss, rpn_cross_entropy, rpn_loss_box, train_op, summary_op], feed_dict={input_image: input_image_np,input_bbox: input_bbox_np}) summary_writer.add_summary(summary_str, global_step=step) # 修改后的代码示例 for step in range(restore_step, FLAGS.max_steps): data = next(data_generator) inputs_padded = data[0] bbox_padded = pad_bbox(data[1],FLAGS.num_bbox) input_image_np = inputs_padded input_bbox_np = bbox_padded lossScale = loss_scale_manager.get_loss_scale() l_s, global_steppp, ml, tl,ce_loss, bbox_loss, _, summary_str = sess.run( [lossScale, global_step, model_loss, total_loss, rpn_cross_entropy, rpn_loss_box, train_op, summary_op], feed_dict={input_image: input_image_np, input_bbox: input_bbox_np}) summary_writer.add_summary(summary_str, global_step=step) print('loss_scale is: ', l_s) print("global_step:", global_steppp) |