调整梯度切分策略
背景介绍
分布式训练场景下,各个Device之间计算梯度后执行梯度聚合操作。由于梯度数据会按顺序产生,且产生后不会再变化,为了提高训练性能,我们可以对梯度参数数据进行切分,同一分段中的梯度数据在产生后可以立即开始梯度聚合,使得一部分梯度参数数据聚合和前后向时间并行执行。
系统默认切分策略是:按照梯度数据量切分为两段,第一段梯度数据量为96.54%,第二段梯度数据量为3.46%(部分情况可能出现为一段情况)。因不同网络梯度数据量、梯度计算时间差异,此种切分方式可能不适用于其他的网络,用户可以参考本节内容调整分布式梯度切分策略,从而提升分布式场景下的训练性能。
确定梯度切分策略
用户需要结合Profiling工具分析训练过程的迭代轨迹数据(Training Trace),确定梯度切分策略需要调整到什么值以达到分布式场景下训练性能提升的目标。

迭代轨迹数据即训练任务及AI软件栈的软件信息,实现对训练任务的性能分析。以默认的两段式梯度切分为例,通过打印出训练任务中关键节点fp_start/bp_end/allreduce1_start/allreduce1_end/allreduce2_start/allreduce2_end/Iteration_end的时间戳,达到把一个迭代的执行情况描述清楚的目的。
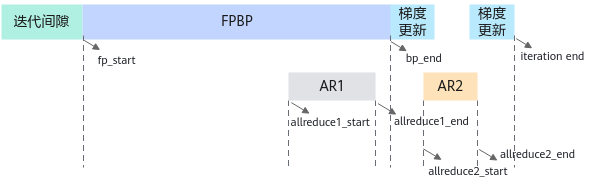
一个较优的梯度数据切分原则为:
- AR1隐藏在FPBP之间。默认情况下Allreduce和前后向串行执行,此时需要配置hcom_parallel为True开启Allreduce和前后向并行执行,后面代码示例“调整梯度切分策略”中会介绍配置方法。
- AR2的时间尽可能短,从而减少计算后因为集合通信而带来的拖尾时间的消耗。
以上述切分原则为依据,用户可以调整梯度切分策略,从而提升分布式场景下的训练性能。下面以两段式梯度切分为例,结合三种优化场景,帮助用户理解如何确定梯度切分策略。
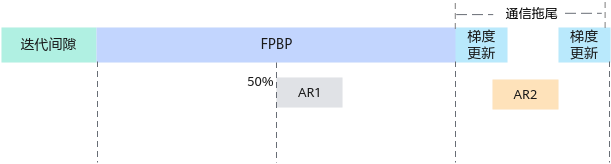
【优化场景1】AR1开始时间较早,AR2时间较长,这种情况下可以将切分点往后设置,从而尽可能缩短AR2的时间。
例如原始设置为第一段梯度数据量为50%,第二段梯度数据量为50%:
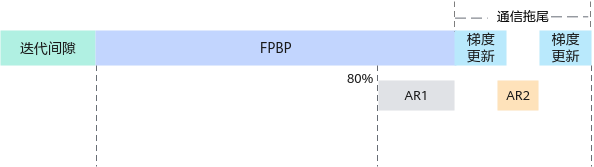
可以修改为第一段梯度数据量为80%,第二段梯度数据量为20%:
【优化场景2】AR1开始时间较晚,AR1时间超出了FPBP的时间,这种情况下,可以将切分点往前设置,从而将AR1隐藏在FPBP之间。
例如原始设置为第一段梯度数据量为90%,第二段梯度数据量为10%:

可以修改为第一段梯度数据量为80%,第二段梯度数据量为20%:

【优化场景3】FPBP数据量较大,计算时间较长,两段式梯度切分的情况下,如果把大部分梯度数据放到AR1中会导致拖尾时间很长,参见优化场景2;如果把大部分的梯度数据放到AR2中会导致AR2时间很长,参见优化场景1。但FPBP中还有较多的时间可以利用,此时可以新增切分段数,使更多的集合通信时间和FPBP并行起来。

调整梯度切分策略
用户可以在训练脚本中调用梯度切分类接口来设置反向计算阶段的allreduce切分融合策略。
set_split_strategy_by_idx:基于梯度的索引id,在集合通信group内设置反向梯度切分策略。
1 2 | from hccl.split.api import set_split_strategy_by_idx set_split_strategy_by_idx([20, 100, 159]) |
set_split_strategy_by_size:基于梯度数据量百分比,在集合通信group内设置反向梯度切分策略。
1 2 | from hccl.split.api import set_split_strategy_by_size set_split_strategy_by_size([60, 20, 20]) |
关于“set_split_strategy_by_idx”与“set_split_strategy_by_size”接口的详细参数介绍,可参见《HCCL API(Python)》。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import tensorflow as tf from npu_bridge.npu_init import * npu_init = npu_ops.initialize_system() npu_shutdown = npu_ops.shutdown_system() config = tf.ConfigProto() custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["use_off_line"].b = True # 开启Profiling迭代轨迹采集 custom_op.parameter_map["profiling_mode"].b = True custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes('{"output":"/home/HwHiAiUser/output","task_trace":"on","training_trace":"on","fp_point":"","bp_point":""}') # 开启Allreduce和前后向并行执行 custom_op.parameter_map["hcom_parallel"].b = True config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF with tf.Session(config=config) as sess: # 进行集合通信初始化 sess.run(npu_init) #设置反向梯度切分策略 set_split_strategy_by_size([80, 20]) #进行allreduce计算... #执行训练... sess.run(npu_shutdown) |