权重更新(在线推理)
背景
推理过程的同时,训练服务器不停训练得到新的权重,而推理部分希望直接更新最新的权重,不希望再走一遍保存pb、编译成离线模型、然后执行离线模型的流程,这种场景可以采用在线推理模式直接更新权重。
本节介绍TensorFlow在线推理场景下,如何更新权重。
整体流程
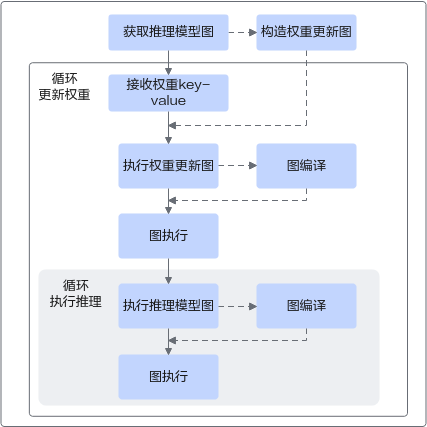
如图1所示,支持循环地更新权重与执行推理。如果多次执行过程batch_size等不发生变化,理论上虚线部分只执行一次。主要流程:
- 获取在线推理模型和权重信息,例如从ckpt文件中加载,实际更新用的权重则来自于外部的key-value;
- 构造权重更新图,包含需要更新的变量和赋值算子,如Assign;
- 执行权重更新图, 将第1步获取到的key-value更新到对应权重;
- 执行在线推理流程。
样例参考
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 | import tensorflow as tf import time import numpy as np from tensorflow.core.protobuf.rewriter_config_pb2 import RewriterConfig from npu_bridge.estimator import npu_ops class TestPolicy(object): def __init__(self, ckpt_path): # NPU模型编译和优化配置 # -------------------------------------------------------------------------------- config = tf.compat.v1.ConfigProto() custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" # 配置1: 选择在Ascend NPU上执行推理 custom_op.parameter_map["use_off_line"].b = True # 配置2:在线推理场景下建议保持默认值force_fp16,使用float16精度推理,以获得较优的性能 custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("force_fp16") # 配置3:关闭remapping config.graph_options.rewrite_options.remapping = RewriterConfig.OFF # 配置4:设置graph_run_mode为推理 custom_op.parameter_map["graph_run_mode"].i = 0 # 配置5:指定AICORE引擎的并行度为4 custom_op.parameter_map["stream_max_parallel_num"].s = tf.compat.as_bytes("AIcoreEngine:4") # -------------------------------------------------------------------------------- # 初始化操作 self.sess = tf.compat.v1.Session(config=config) self.ckpt_path = ckpt_path # 加载推理模型 self.load_graph() self.graph = self.sess.graph def load_graph(self): ''' 从ckpt加载推理模型,获取权重的信息,并构造权重更新图 ''' saver = tf.compat.v1.train.import_meta_graph(self.ckpt_path + '.meta') saver.restore(self.sess, self.ckpt_path) self.vars = tf.compat.v1.trainable_variables() self.var_placeholder_dict = {} self.var_id_to_name = {} self.update_op = [] for id, var in enumerate(self.vars): self.var_placeholder_dict[var.name] = tf.compat.v1.placeholder(var.dtype, shape=var.get_shape(), name=("PlaceHolder_" + str(id))) self.var_id_to_name[id] = var.name self.update_op.append(tf.compat.v1.assign(var, self.var_placeholder_dict[var.name])) self.update_op = tf.group(*self.update_op) # 实际场景的权重key-value来自于训练服务器,这里保存一份ckpt中的权重仅用于示例 self.key_value = self.get_dummy_weights_for_test() def unload(self): ''' 关闭session,释放资源 ''' print("====== start to unload ======") self.sess.close() def get_dummy_weights_for_test(self): ''' 从ckpt中获取权重的信息,并构造权重更新图 :return: 权重 key-value :NOTES: 实际场景的权重key-value来自于训练服务器,这里返回的ckpt中的权重仅用于示例 ''' weights_data = self.sess.run(self.vars) weights_key_value = {} for id, var in enumerate(weights_data): weights_key_value[self.var_id_to_name[id]] = var return weights_key_value def get_weights_key_value(self): ''' 获取权重key-value :return: 权重 key-value :NOTES: 实际场景的权重key-value来自于训练服务器,这里返回保存的权重仅用于示例 ''' return self.key_value def update_weights(self): ''' 更新权重 ''' feed_dict = {} weights_key_value = self.get_weights_key_value() for key, weight in weights_key_value.items(): feed_dict[self.var_placeholder_dict[key]] = weight self.sess.run(self.update_op, feed_dict=feed_dict) def infer(self, input_image): ''' 执行推理流程 :param: input_image 输入的数据,示例中为图像数据 :return: output 推理结果, 示例中为labels ''' image = self.graph.get_operation_by_name('Placeholder').outputs[0] label_output = self.graph.get_operation_by_name('accuracy/ArgMax').outputs[0] output = self.sess.run([label_output], feed_dict={image: input_image}) return output def prepare_input_data(batch): ''' 推理的输入数据 :param: batch 数据batch_size :return: 推理数据 ''' image = 255 * np.random.random([batch, 784]).astype('float32') return image if __name__ == "__main__": batch_size = 16 ckpt_path = "./mnist_deep_model/mnist_deep_model" policy = TestPolicy(ckpt_path) update_count = 10 for i in range(update_count): update_start = time.time() policy.update_weights() update_consume = time.time() - update_start print("Update weight time cost: {} ms".format(update_consume * 1000)) test_count = 20 input_data = prepare_input_data(batch_size) start_time = time.time() for i in range(test_count): output = policy.infer(input_data) print("result is ", output) time_consume = (time.time() - start_time) / (test_count) print("Inference average time cost: {} ms \n".format(time_consume * 1000)) policy.unload() print("====== end of test ======") |
父主题: 更多特性