基本的模型执行流程
开发应用时,如果涉及整网模型推理,则应用程序中必须包含模型执行的代码逻辑,关于模型执行的接口调用流程,请依次参见主要接口调用流程以及本节中的说明。
本节描述的是整网模型执行的接口调用流程,对于算子模型加载与执行的接口调用流程请参见算子调用。
图1 基本的模型推理流程
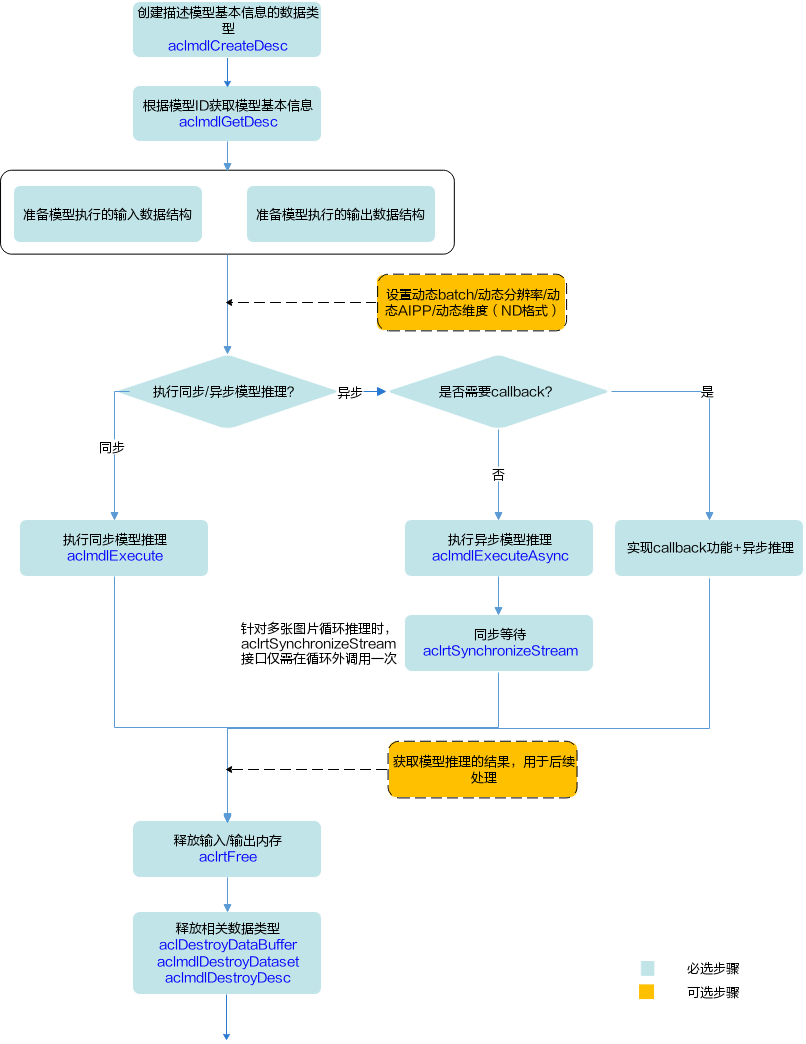
关键接口的说明如下(调用示例请参见模型推理基本场景、模型推理扩展场景):
- 调用aclmdlCreateDesc接口创建描述模型基本信息的数据类型。
- 调用aclmdlGetDesc接口根据模型加载中返回的模型ID获取模型基本信息。
- 准备模型执行的输入、输出数据结构,具体流程,请参见准备模型执行的输入/输出数据结构。
如果模型的输入涉及动态Batch、动态分辨率、动态AIPP、动态维度(ND格式)等特性,请参见设置动态Batch/动态分辨率/动态AIPP/动态维度(ND格式)。
- 执行模型推理。
对于固定的多Batch场景,需要满足Batch数后,才能将输入数据发送给模型进行推理。不满足Batch数时,用户需根据自己的实际场景处理。
当前系统支持模型的同步推理和异步推理:
- 同步推理时调用aclmdlExecute接口
- 异步推理时调用aclmdlExecuteAsync接口
对于异步接口,还需调用aclrtSynchronizeStream接口阻塞应用程序运行,直到指定Stream中的所有任务都完成。
如果同时需要实现Callback功能,请参见Callback场景。
- 获取模型推理的结果,用于后续处理。
对于异步推理,在实现Callback功能时,在回调函数内获取模型推理的结果,供后续使用。
- 释放内存。
调用aclrtFree接口释放Device上的内存。
- 释放相关数据类型的数据。
在模型推理结束后,需及时调用aclDestroyDataBuffer接口和aclmdlDestroyDataset接口释放描述模型输入的数据,且先调用aclDestroyDataBuffer接口,再调用aclmdlDestroyDataset接口。如果存在多个输入、输出,需调用多次aclDestroyDataBuffer接口。
父主题: 模型执行