基本概念
昇腾模型压缩工具提供了一系列的模型压缩方法,对模型进行压缩处理后,生成的部署模型在昇腾AI处理器上可使能一系列性能优化操作,提高性能。昇腾模型压缩工具当前使用的压缩方法主要为量化,量化过程中可以实现模型部署优化(主要为算子融合)。
量化
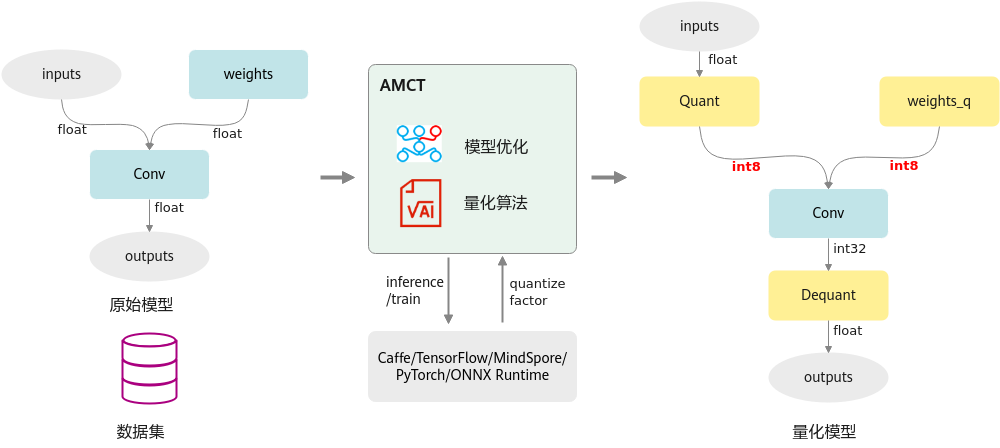
量化是指对模型的权重(weight)和数据(activation)进行低比特处理,让最终生成的网络模型更加轻量化,从而达到节省网络模型存储空间、降低传输时延、提高计算效率,达到性能提升与优化的目标。
昇腾模型压缩工具将量化和模型转换分开,实现对模型中可量化层的独立量化,并将量化后的模型保存为onnx文件。其中量化后的仿真模型可以在CPU或者GPU上运行,完成精度仿真;量化后的部署模型可以部署在昇腾AI处理器上运行,达到提升推理性能的目的。
其运行原理如下图所示。特性详细介绍请参见量化。
图1 量化运行原理
模型部署优化
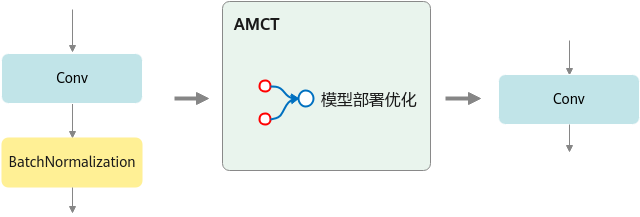
主要为算子融合,是指通过数学等价,将模型中的多个算子运算融合单算子运算,以减少实际前向过程中的运算量,如将卷积层和BN层融合为一个卷积层。
其运行原理如下图所示。
图2 模型部署优化原理
父主题: 概述