性能调优建议
在执行完Profiling数据导出命令“python3 msprof.py export summary -dir xxx”后,会在屏幕打印相关性能调优建议,具体如下:

如果没有调优建议,相应项目结果显示NA。
- 基于单算子性能数据cube或vector利用率优化建议。
单算子数据分析时,发现算子满足cube或vector使用率小于预设阈值(80%),cube或vector利用率低,需要提升利用率。
图1 low vector(cube) compute utilization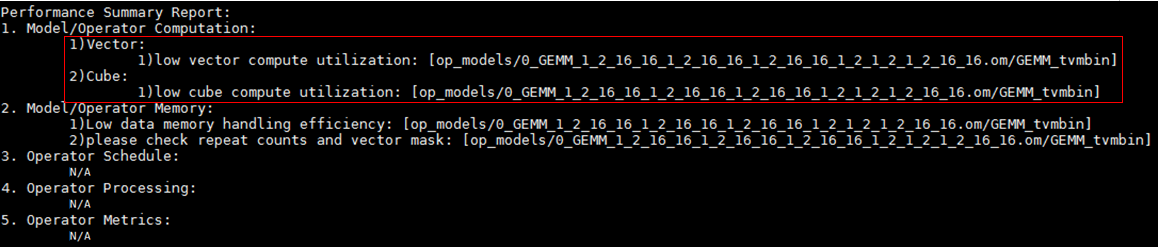
- 基于单算子性能数据vec_bankgroup_cflt_ratio或vec_bank_cflt_ratio优化建议。
单算子数据分析时,发现算子满足vec_bankgroup_cflt_ratio或vec_bank_cflt_ratio使用率大于预设阈值(4%),提示用户bank冲突。
图2 vector bank group conflict has reached the upper limit
- 基于单算子性能数据memory bound优化建议。
单算子数据分析时,发现算子满足memory bound大于设定阈值(1),检查数据搬运的burthlength是否较小、是否存在重复搬运。
图3 low data memory handling efficiency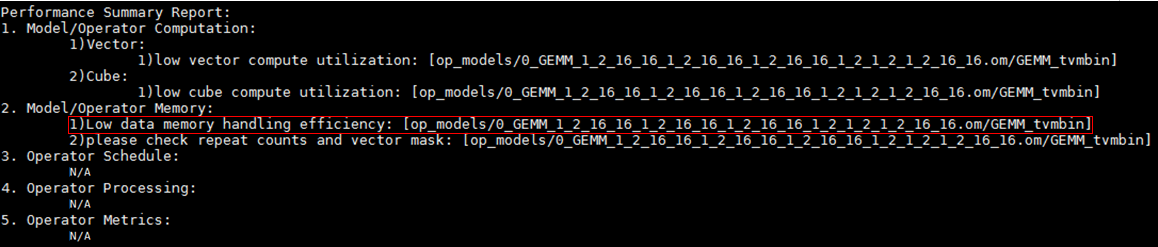
- 基于单算子性能数据vector bound优化建议。
单算子数据分析时,发现算子满足vector bound大于设定阈值(1),检查vector指令的repeat是否较小、是否频繁设置vector mask。
图4 check repeat counts and vector mask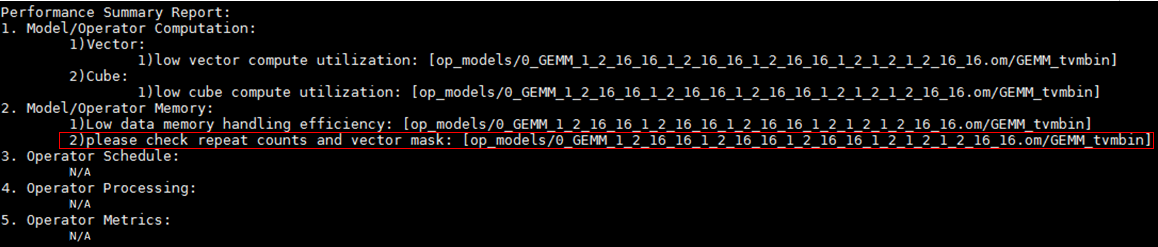
- 基于整网性能数据相邻算子的间隔大于阈值的优化建议。
根据配置的时间间隔阈值,如果前后两个算子的间隔(上一个算子执行结束到下一个算子执行开始的时间间隔)大于该阈值(10us),即存在等待时间较长的算子。
图5 task wait time has reached the upper limit
- 基于整网性能数据transData算子数量优化建议。
存在transData算子,且数量超过设定的阈值(2),需检查是否有使用transData算子的必要性。
图6 please check and reduce the transData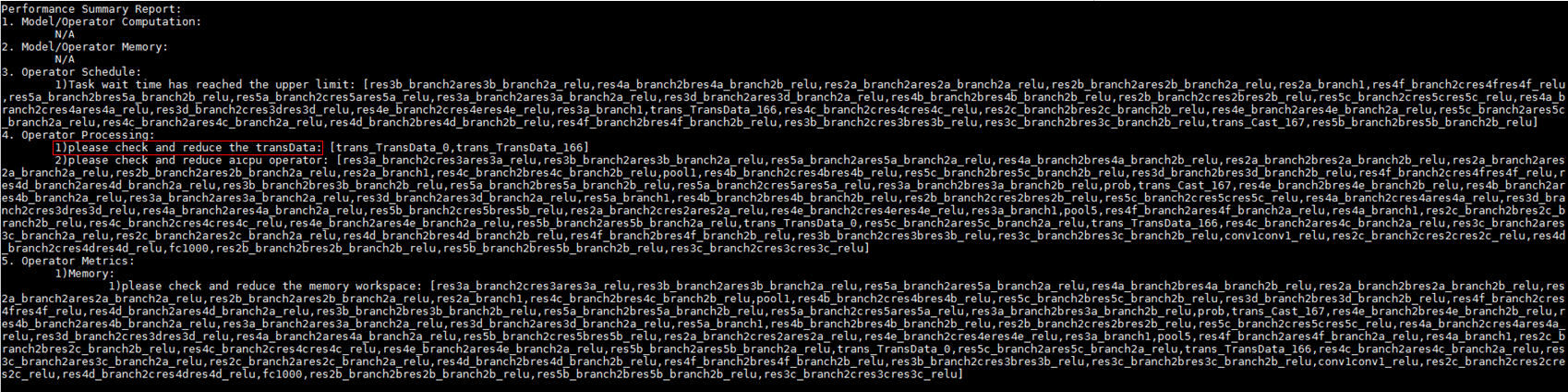
- 基于整网性能数据aicpu优化建议。
整网数据分析时,存在aicpu算子,建议优化并去除网络中的aicpu算子。
图7 check and reduce aicpu operator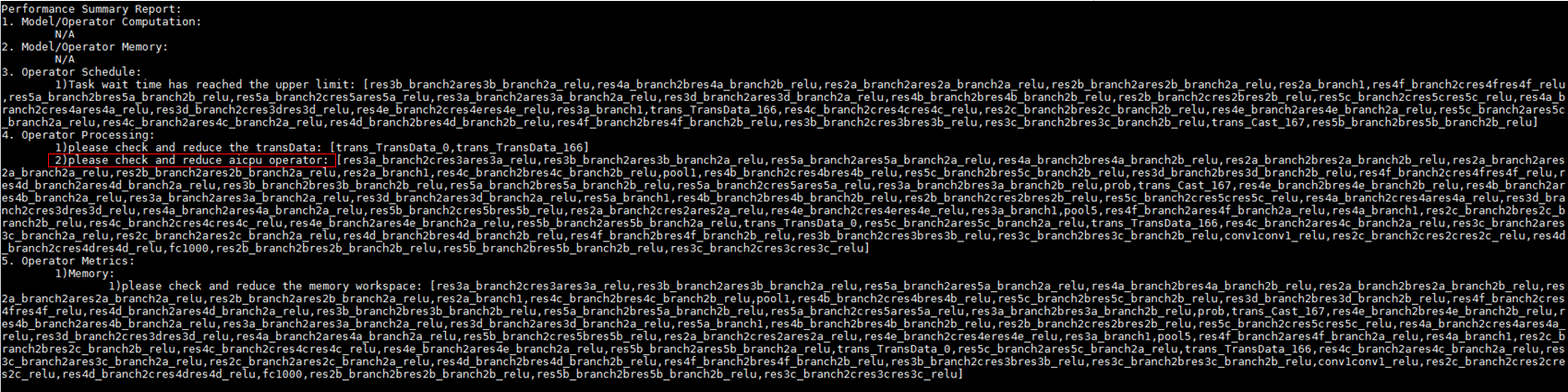
- 基于整网性能数据memory_workspace优化建议。
检测到性能数据memory_workspace中存在不为0的数据,建议优化memory_workspace。
图8 check and reduce the memory workspace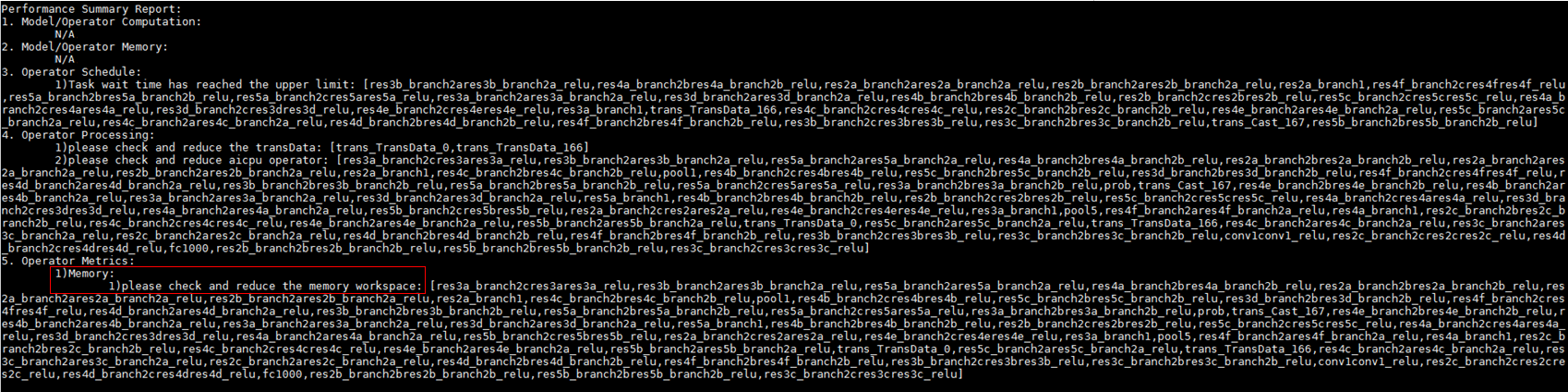
- 基于慢节点slow node优化建议。
由于集合通信算子是同步执行的,若集群中存在慢节点,则会由于木桶效应,拖累整个集群的性能。
优化建议原则:
计算每个Profiling的数据增强拖尾的平均耗时和所有Profiling目录的数据增强拖尾的平均时间的占比,当占比大于配置的迭代间隙阈值(20%),则识别为慢节点。
图9 For slow nodes, pay attention to the data preparation phase (threshold: 20%)
- 基于慢链路slow link优化建议。
若集群中某些链路存在问题,带宽较小,会影响集群通信的时长从而拖累整个集群的性能。
优化建议原则:
计算每个Profiling目录下的不同链路类型的带宽占比,当占比大于配置的链路带宽阈值(20%),则识别为慢链路。
图10 For slow link, pay attention to the data bandwith (threshold: 20%)