接口调用流程
开发应用时,如果涉及整网模型推理,则应用程序中必须包含模型执行的代码逻辑,关于模型执行的接口调用流程。请先参见pyACL接口调用流程了解整体流程,再查看本节中的流程说明。
本节描述的是整网模型执行的接口调用流程,对于算子模型加载与执行的详细说明请参见单算子调用。
模型执行
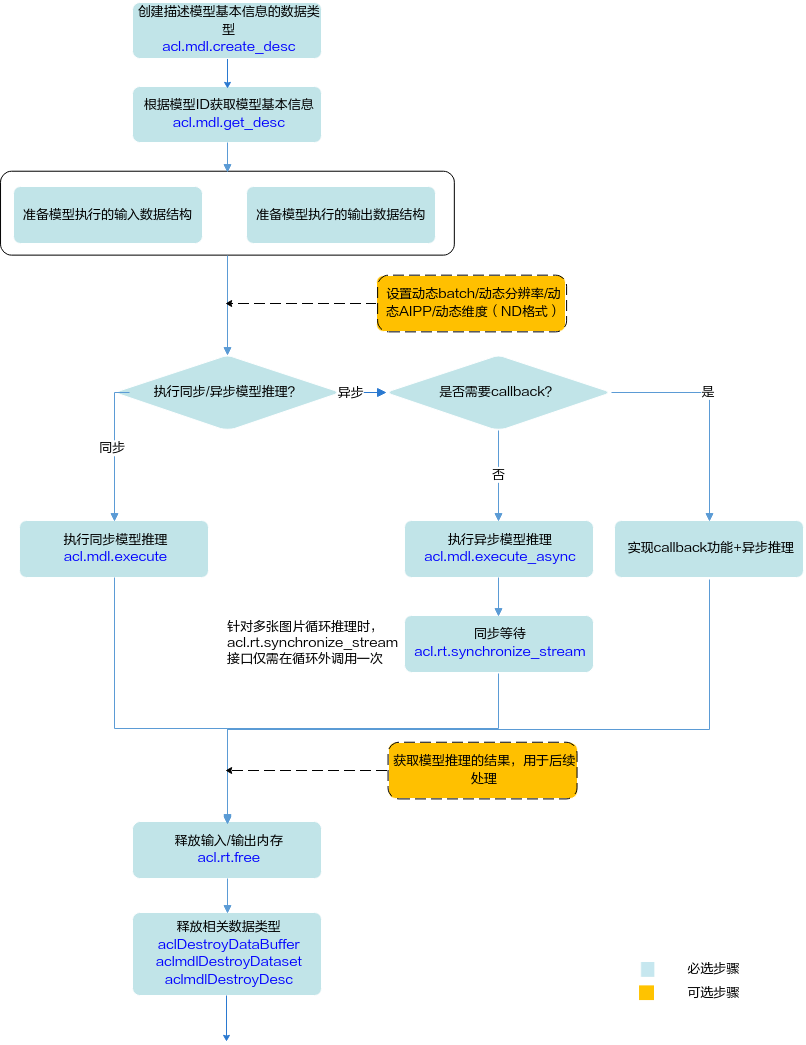
关键接口的说明如下:
- 调用acl.mdl.create_desc接口创建描述模型基本信息的数据类型。
- 调用acl.mdl.get_desc接口根据接口调用流程中返回的模型ID获取模型基本信息。
- 准备模型执行的输入、输出数据结构,具体流程请参见准备模型执行的输入/输出数据结构。
如果模型的输入涉及动态Batch、动态分辨率、动态AIPP、动态维度(ND格式)等特性,请参见模型动态推理、模型动态AIPP推理。
- 执行模型推理。
对于固定的多Batch场景,需要满足Batch数后,才能将输入数据发送给模型进行推理。不满足Batch数时,用户需根据自己的实际场景处理。
当前系统支持模型的同步推理和异步推理:
- 同步推理时调用acl.mdl.execute接口。
- 异步推理时调用acl.mdl.execute_async接口。
对于异步接口,还需调用acl.rt.synchronize_stream接口阻塞应用程序运行,直到指定Stream中的所有任务都完成。
异步推理的详细介绍,请参见模型异步推理。
- 获取模型推理的结果,用于后续处理。
对于异步推理,在实现Callback功能时,在回调函数内获取模型推理的结果,供后续使用。
- 释放内存。
调用acl.rt.free接口释放Device上的内存。
- 释放相关数据类型的数据。
在模型推理结束后,需及时依次调用acl.destroy_data_buffer接口和acl.mdl.destroy_dataset接口释放描述模型输入的数据。如果存在多个输入、输出,需调用多次acl.destroy_data_buffer接口。
准备模型执行的输入/输出数据结构
pyACL提供了以下数据类型来描述模型、模型输入、模型输出以及存放数据的内存,在模型执行前,需要构造好这些数据类型,作为模型执行的输入:
- 使用aclmdlDesc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等)。
模型加载成功后,用户可根据模型的ID,调用acl.mdl.get_desc接口获取该模型的描述信息,进而从模型的描述信息中获取模型输入/输出的个数、内存大小、维度信息、Format、数据类型等信息,可参见aclmdlDesc类型下的操作接口。
- 使用aclmdlDataset类型的数据描述模型的输入/输出数据,模型可能存在多个输入、多个输出。
调用aclmdlDataset类型下的操作接口添加aclDataBuffer类型的数据、获取aclDataBuffer的个数等。
- 每个输入/输出的内存地址、内存大小用aclDataBuffer类型的数据来描述。
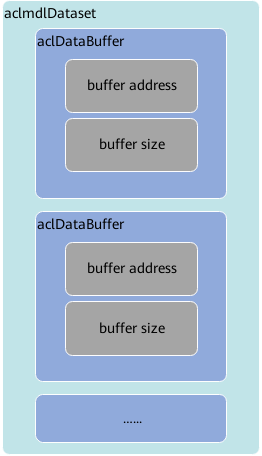
了解相关的数据类型后,可以使用这些数据类型的操作接口准备模型的输入、输出数据结构,如下图所示。
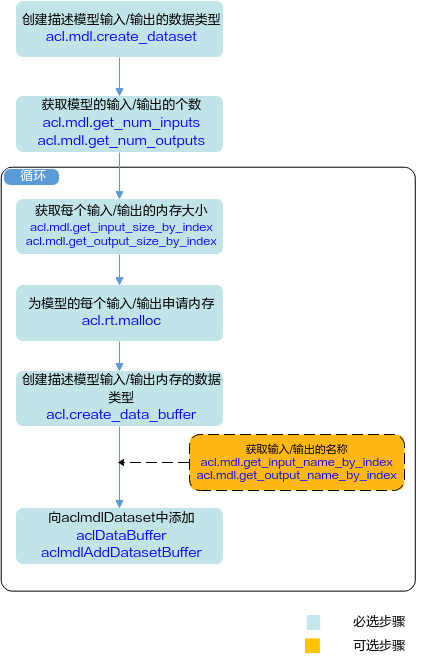
关键说明如下:
- 模型存在多个输入、输出时,用户可调用acl.mdl.get_num_inputs、acl.mdl.get_num_outputs接口获取输入、输出的个数。
- 模型每个输入、输出所需的内存大小,用户可调用acl.mdl.get_input_size_by_index、acl.mdl.get_output_size_by_index接口获取。
如果模型的输入涉及动态Batch、动态分辨率、动态维度(ND格式)等特性,输入tensor数据的Shape支持多种档位,在模型执行前才能确定,因此该输入所需的内存大小建议用户调用acl.mdl.get_input_size_by_index接口获取,该接口获取的是最大档位的内存,确保内存够用。
- 模型存在多个输入、输出时,用户在向aclmdlDataset中添加aclDataBuffer时,为避免顺序出错,可以先调用acl.mdl.get_input_name_by_index、acl.mdl.get_output_name_by_index接口获取输入、输出的名称,根据输入、输出名称所对应的index的顺序添加。