'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
数据排布格式
Format为数据的物理排布格式,定义了解读数据的维度,比如1D,2D,3D,4D,5D等。
NCHW和NHWC
- N:Batch数量,例如图像的数目。
- H:Height,特征图高度,即垂直高度方向的像素个数。
- W:Width,特征图宽度,即水平宽度方向的像素个数。
- C:Channels,特征图通道,例如彩色RGB图像的Channels为3。
由于数据只能线性存储,因此这四个维度有对应的顺序。不同深度学习框架会按照不同的顺序存储特征图数据,比如Caffe,排列顺序为[Batch, Channels, Height, Width],即NCHW。TensorFlow中,排列顺序为[Batch, Height, Width, Channels],即NHWC。
如图1所示,以一张格式为RGB的图片为例,NCHW中,C排列在外层,实际存储的是“RRRRRRGGGGGGBBBBBB”,即同一通道的所有像素值顺序存储在一起;而NHWC中C排列在最内层,实际存储的则是“RGBRGBRGBRGBRGBRGB”,即多个通道的同一位置的像素值顺序存储在一起。

尽管存储的数据相同,但不同的存储顺序会导致数据的访问特性不一致,因此即便进行同样的运算,相应的计算性能也会不同。
NC1HWC0
昇腾AI处理器中,为了提高通用矩阵乘法(GEMM)运算数据块的访问效率,所有张量数据统一采用NC1HWC0的五维数据格式。其中C0与微架构强相关,等于AI Core中矩阵计算单元的大小。
C1=(C+C0-1)/C0。如果结果不整除,向上取整。
NHWC/NCHW -> NC1HWC0的转换过程为:将数据在C维度进行分割,变成C1份NHWC0/NC0HW,再将C1份NHWC0/NC0HW在内存中连续排列成NC1HWC0,其格式转换示意图如下图所示。

- NHWC -> NC1HWC0的转换公式如下:
Tensor.reshape( [N, H, W, C1, C0]).transpose( [0, 3, 1, 2, 4] )
- NCHW -> NC1HWC0的转换公式如下:
Tensor.reshape( [N, C1, C0, H, W]).transpose( [0, 1, 3, 4, 2] )
FRACTAL_NZ
FRACTAL_NZ是分形格式,如Feature Map的数据存储,在cube单元计算时,输出矩阵的数据格式为NW1H1H0W0。整个矩阵被分为(H1*W1)个分形,按照column major排布,形状如N字形;每个分形内部有(H0*W0)个元素,按照row major排布,形状如z字形。考虑到数据排布格式,将NW1H1H0W0数据格式称为Nz(大N小z)格式。其中,H0,W0表示一个分形的大小,示意图如下所示:
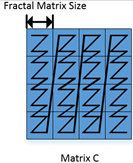
ND –> FRACTAL_NZ的变换过程为:
tensor.reshape( [M1, M0, N1, N0] ).transpose( [2, 0, 1, 3] )
FRACTAL_Z
FRACTAL_Z是用于定义卷积权重的数据格式,由FT Matrix(FT:Filter,卷积核)变换得到。FRACTAL_Z是送往Cube的最终数据格式,采用“C1HW,N1,N0,C0”的4维数据排布。
数据有两层Tiling,如下图所示:

第一层与Cube的Size相关,数据按照列的方向连续(小n);第二层与矩阵的Size相关,数据按照行的方向连续(大Z)。
例如:HWCN = (2, 2, 32, 32),将其变成 FRACTAL_Z( C1HW, N1, N0, C0 ) = (8, 2, 16, 16)。
HWCN变换5HD的过程为:
Tensor.padding([ [0,0], [0,0], [0,(C0–C%C0)%C0], [0,(N0–N%N0)%N0] ]).reshape( [H, W, C1, C0, N1, N0]).transpose( [2, 0, 1, 4, 5, 3] ).reshape( [C1*H*W, N1, N0, C0])
NCHW变换5HD的过程为:
Tensor.padding([ [0,(N0–N%N0)%N0], [0,(C0–C%C0)%C0], [0,0], [0,0] ]).reshape( [N1, N0, C1, C0, H, W,]).transpose( [2, 4, 5, 0, 1, 3] ).reshape( [C1*H*W, N1, N0, C0])
