'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
save_model
功能说明
根据量化因子记录文件record_file以及修改后的模型,调用该接口,插入AscendQuant、AscendDequant等算子,然后保存为可以在ONNX Runtime环境进行精度仿真的fake_quant模型,和可以在昇腾AI处理器做推理的deploy模型。
约束说明
- 在网络推理的batch数目达到batch_num后,再调用该接口,否则量化因子不正确,量化结果不正确。
- 该接口只接收quantize_model接口产生的ONNX类型模型文件。
- 该接口需要输入量化因子记录文件,量化因子记录文件在quantize_model阶段生成,在模型推理阶段填充有效值。
函数原型
save_model(modified_onnx_file, record_file, save_path)
参数说明
参数名 |
输入/返回值 |
含义 |
使用限制 |
|---|---|---|---|
modified_onnx_file |
输入 |
文件名,修改后的ONNX模型文件,由quantize_model接口输出。 |
数据类型:string |
record_file |
输入 |
量化因子记录文件路径及名称。 |
数据类型:string |
save_path |
输入 |
模型存放路径。 该路径需要包含模型名前缀,例如./quantized_model/*model。 |
数据类型:string |
返回值说明
无。
函数输出
- 精度仿真模型文件:模型名中包含fake_quant,可以在ONNX执行框架ONNX Runtime进行精度仿真。
fake_quant模型主要用于验证量化后模型的精度,可以在ONNX Runtime环境下运行。进行前向推理的计算过程中,在fake_quant模型中对卷积层等的输入数据和权重进行了量化反量化的操作,来模拟量化后的计算结果,从而快速验证量化后模型的精度。
如下图所示,Quant层、Conv卷积层和DeQuant层之间的数据都是Float32数据类型的,其中Quant层将数据量化到INT8又反量化为Float32,权重也是量化到INT8又反量化为Float32,实际卷积层的计算是基于Float32数据类型的,该模型用于ONNX Runtime环境验证量化后模型的精度,不能够用于ATC工具转换成om模型。图1 fake_quant模型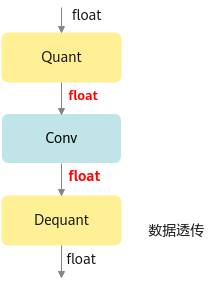
- 部署模型文件:模型名中包含deploy,经过ATC转换工具转换后可部署到昇腾AI处理器。
deploy模型由于已经将权重等转换成为了INT8, INT32类型, 因此不能在ONNX Runtime环境上执行推理计算。如下图所示,deploy模型的AscendQuant层将Float32的输入数据量化为INT8,作为卷积层的输入,权重也是使用INT8数据类型作为计算,在deploy模型中的卷积层的计算是基于INT8,INT32数据类型的,输出为INT32数据类型经过AscendDeQuant层转换成Float32数据类型传输给下一个网络层。图2 deploy模型
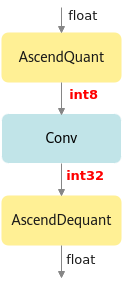
重新执行量化时,该接口输出的上述文件将会被覆盖。
调用示例
import amct_onnx as amct # 进行网络推理,期间完成量化 # 由于quantize_model接口生成的校准模型中包含了AMCT新增的自定义算子,所以在执行校准集的推理时创建的onnxruntime的InferenceSession需要包含AMCT提供的SessionOptions for i in batch_num: onnxruntime.InferenceSession(onnx_model, amct.AMCT_SO).run(None, {'input':input_batch}) # 插入API,将量化的模型存为onnx文件 amct.save_model(modified_onnx_file="./tmp/modified_model.onnx", record_file="./scale_offset_record_file.txt", save_path="./results/model")
父主题: 训练后量化
