'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
超参数优化
概述
在机器学习、深度学习中,有两类参数,一类需要从数据中学习和估计得到,称为模型参数(Parameter);另一类需要人为设定,称为超参数(Hyperparameter),例如学习率、正则化系数等。
HPO(Hyperparameter Optimization, 超参数优化 )是指用自动化的算法来优化超参数,从而提升模型的精度、性能等指标。使用HPO能力,可以快速高效地在超参数空间中测试选择最佳的超参数组合,节省大量人力和时间。
当前提供的HPO能力支持Random、ASHA、BOHB、BOSS、PBT等HPO算法,适用于常见的深度神经网络的超参数优化,包括单目标优化和随机帕累托的多目标超参选择。
帕累托机制
了解帕累托机制主要需要了解以下两个概念:
- 帕累托支配:一个超参A在任何一个优化目标维度都优于另外一个超参B,称为超参A支配超参B。
- 帕累托前沿:在一系列超参中,对于任何一个超参,没有其他超参能支配它。
HPO功能会通过HPO算法搜索出满足帕累托前沿的一系列超参数组合,如图1代表的是以准确率Acc和时延Latency为优化目标搜索出的超参的情况。
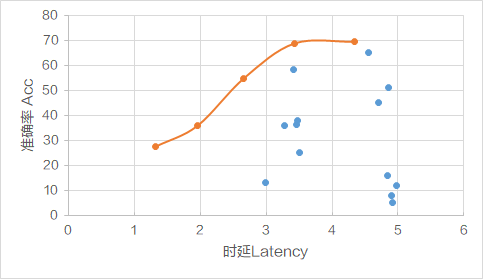
其中,橙色圆点为搜索出来的在准确率Acc和时延Latency维度都优于蓝色圆点代表的超参,即橙色圆点代表的超参支配蓝色圆点代表的超参。
在橙色圆点代表的一系列超参中,对于任何一个超参,没有其他参数能在准确率Acc和时延Latency维度均优于它,即没有其他参数能支配它,橙色圆点代表的一系列超参构成帕累托前沿。
前提条件
- 已安装1.1.3版本的pandas依赖包。
- 配置Ascend-cann-toolkit环境变量。
- 以运行用户登录,在任意目录下执行vi ~/.bashrc命令,打开.bashrc文件,在文件最后一行后面添加以下内容(以非root用户的默认安装路径为例)。
source ~/Ascend/ascend-toolkit/set_env.sh
- 执行:wq!命令保存文件并退出。
- 执行source ~/.bashrc命令使其立即生效。
- 以运行用户登录,在任意目录下执行vi ~/.bashrc命令,打开.bashrc文件,在文件最后一行后面添加以下内容(以非root用户的默认安装路径为例)。
HPO工具运行流程
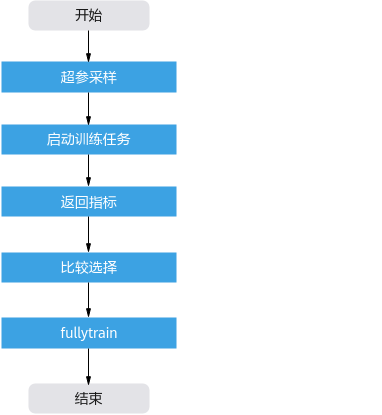
- 超参采样:HPO工具读取配置文件(由用户自行准备),使用HPO算法在搜索空间中进行多组超参的采样。
- 启动训练任务:对于每组采样得到的超参,HPO工具在子进程中启动相应的训练任务。
- 返回指标:每个训练任务将待优化指标值,如精度、时延等,保存到json文件中,由HPO工具读取。
- 比较选择:HPO工具对多组超参对应的指标值进行比较,选出较优的一组或多组超参。
- fullytrain:HPO工具使用较优超参,进行训练任务的fullytrain。
操作步骤
- 进入{CANN包安装路径}/ascend-toolkit/latest/tools/ascend_automl/examples/docs/hpo目录,已提供示例文件hpo.yml,建议拷贝至当前运行目录修改即可。
- 编写hpo.yml配置文件,进行任务配置。任务配置主要包含通用配置、hpo阶段和fully_train阶段的配置,请参考以下加粗字体信息进行通用配置。
general: parallel_search: False # 是否使用多卡进行HPO搜索 parallel_fully_train: False# 是否使用多卡进行fully_train search_timeout: 10000 # HPO阶段的搜索timeout,单位为秒,不配置则使用 31536000 worker: timeout: 150 # HPO阶段/fully_train阶段单个训练任务的timeout,单位为秒,不配置则使用 `search_timeout` logger: level: info # 日志级别,debug|info|warn|error| task: local_base_path: /home/xxx # 任务路径,默认值为启动HPO任务的工作路径,请根据实际路径配置 pipeline: [hpo, fully_train] # 与后续阶段的名称保持一致,需为[hpo, fully_train]或[hpo]- 如果配置了“ search_timeout” 或“ worker: timeout”会在超时时尝试停止任务,在某些情况下可能会停不掉,造成未停掉的任务显存占用,导致后续任务显存不足。
- 若不配置“search_timeout”字段,则使用默认值 “31536000”。若不配置“worker: timeout”字段,将使用“search_timeout”。
- 配置hpo阶段,主要配置搜索算法(search_algorithm)、搜索空间(search_space)和训练任务(trainer)信息。请参考以下加粗字体信息配置hpo阶段任务类型。
hpo: pipe_step: type: CustomSearchPipeStep# 不需修改,也可设置为SearchPipeStep search_algorithm: # 搜索算法 …… search_space: # 搜索空间 …… trainer: # 训练脚本及训练参数配置 ……“pipe_step: type”若要支持多卡搜索,需要配置为 “SearchPipeStep”,但 “SearchPipeStep” 不支持 “general.search_timeout”。- search_algorithm配置。HPO 命令行工具能力支持 Random、ASHA、BOHB、BOSS、PBT 等 HPO 算法,以Random 搜索算法为例,参考以下加粗字体信息进行配置,其他算法配置请参考超参数优化支持的搜索算法说明。
search_algorithm: # 搜索算法配置 type: RandomSearch # 搜索算法 objective_keys: 'accuracy' # 优化目标,需要与trainer.objectives以及训练脚本中dump_objective的实际输出匹配,可以为多个 ,如['accuracy','avg_time'] policy: #算法策略配置 num_sample: 10 #RandomSearch超参采样的总组数,可选,默认值为10 - search_space配置。HPO 工具将根据“hpo.search_space.hyperparameters”指定的参数类型和范围,进行超参数值的采样。参考以下加粗字体信息进行配置。
search_space: # 搜索空间配置 type: SearchSpace # 搜索空间,无需修改 hyperparameters: #超参数配置 - key: lr # 超参数名称,需要与用户脚本实际需要的参数名称匹配 type: FLOAT # 超参数值类型,需要与用户脚本实际需要的参数类型匹配 range: [0.001,0.01] # 超参数采样值,根据超参数值的类型进行配置超参数值类型type支持 CATEGORY、BOOL、INT、INT_EXP、FLOAT、FLOAT_EXP 等。
其中CATEGORY表示离散值,此时 range 配置为可选值的列表,如 [16, 32, 48, 64]、["sgd", "adam", "lamb"]、[True, False]。BOOL、INT、INT_EXP、FLOAT、FLOAT_EXP 表示连续值,此时 range 配置为参数的取值范围,如 [0.001, 0.1]、[16, 128],其中INT_EXP、FLOAT_EXP 表示按照 log10 的分布采样。
- trainer配置。HPO工具将从search_space中进行超参采样,并结合trainer中的配置内容,组合一个完整的训练任务启动命令,并在子进程中运行。
trainer: # 训练脚本以及训练参数配置 type: HpoRunner # 无需修改 objectives: #优化目标配置,值需与search_algorithm.objective_keys一致 accuracy: 'MAX' #优化目标的择优方式,取值为'MAX'或'MIN' avg_time: 'MIN' #优化目标的择优方式,取值为'MAX'或'MIN' train_script: /home/xxx/hpo_sample.py #用户训练工程的启动脚本,根据实际情况配置 pkg_path: /home/xxx/pkg_path #可选,用户训练工程代码所在路径,HPO工具会将该路径加入PYTHONPATH other_args: #可选,无需进行调优的固定参数 momentum: 0.9 # 带值参数,拼接命令为 --momentum=0.9 pretrained: ~ # 不带值参数,拼接命令为 --pretrained has_config_arg: True # 是否需要配置文件,取值为True或False config_arg_name: config_file # 若 has_config_arg 为 True,指定配置文件在训练脚本中的参数名 config_file_path: /home/xxx/config.yml # 若 has_config_arg 为 True,指定配置文件的路径 enable_arg_check: True # 是否检查脚本参数,取值为True或False- “has_config_arg”默认为“False”,若设置为“True”,需同时配置“config_arg_name”和“config_file_path”。
- “enable_arg_check”决定了参数匹配方式,设置为“True”时将对参数进行检查,不匹配的参数将不会传给训练脚本。
- search_algorithm配置。HPO 命令行工具能力支持 Random、ASHA、BOHB、BOSS、PBT 等 HPO 算法,以Random 搜索算法为例,参考以下加粗字体信息进行配置,其他算法配置请参考超参数优化支持的搜索算法说明。
- 配置fully_train阶段。参考以下加粗字体信息进行配置。
fully_train: # 使用调优后的参数,完整训练模型 pipe_step: type: TrainPipeStep #无需修改 trainer: ref: hpo.trainer #复用hpo阶段的配置 - 进行源码修改。HPO主进程与训练任务子进程之间,需要进行信息交互,用户需要修改源码,从环境变量中获取部分变量值,并将需要传回给主进程的数值保存在json文件中。参考同目录下hpo_sample.py文件,修改用户自行准备的训练脚本。
- dump 待优化指标值到 json 文件。参考样例 hpo_sample.py 中的 modification 1 和 modification 4进行如下配置。
def dump_objective(objective_key, objective_value): json_path = './{}.json'.format(objective_key) if os.path.exists(json_path): os.remove(json_path) with os.fdopen(os.open(json_path, os.O_WRONLY | os.O_CREAT | os.O_TRUNC, stat.S_IWUSR | stat.S_IRUSR), 'w') as fout: json.dump({objective_key: objective_value}, fout) ... dump_objective(objective_key="accuracy", objective_value={实际训练中的数值})
- 用户可将dump_objective()函数添加在脚本中,并以dump_objective(objective_key, objective_value)的格式进行调用,将待优化指标值保存至json文件中。HPO主进程将从这一json文件中读取指标值,并以此为依据进行后续超参的比较。
- objective_key需与步骤3中的hpo.search_algorithm.objective_keys保持一致。
- 获取 PIPESTEP 与 EPOCHS 环境变量。若配置hpo阶段“search_algorithm”的类型不是RandomSearch搜索算法,则需要从环境变量获取实际指定的脚本训练 epochs,请参考样例 hpo_sample.py 中的 “modification 3”进行如下配置。
pipestep_env = os.getenv("PIPESTEP") if pipestep_env == "hpo": #标识当前子进程阶段,取值为 "hpo" 或 "fullytrain",以此指定 epochs 数量等训练参数。 epochs = int(os.getenv("EPOCHS", opt.epochs))部分HPO算法向不同的子任务分配不同的训练资源(即epochs),因此子进程需要读取主进程指定的epochs配额。“EPOCHS”取值为'0'、'1'、'2'……,用于 hpo 阶段,fully_train 阶段会取消该环境变量。
- 获取 DEVICE_ID 环境变量。进行多卡训练时,训练脚本需要获取实际分配的 DEVICE_ID,参考样例 hpo_sample.py 中的 modification 3进行如下配置。若为单卡搜索/训练,用户可自行指定NPU卡号,无需做对应修改。
opt.device = "npu:{}".format(os.getenv("DEVICE_ID", '0')) #在多卡搜索/训练时,主进程为子进程指定NPU卡的id,取值为'0'、'1'、'2'……
- dump 待优化指标值到 json 文件。参考样例 hpo_sample.py 中的 modification 1 和 modification 4进行如下配置。
- 启动超参数调优任务。
- 单卡训练,使用以下命令进行任务启动:
export DEVICE_ID=3 # 可选,指定实际使用的 NPU vega hpo.yml #根据实际文件名进行修改
- 多卡训练,需要在步骤3通用配置时,“parallel_search”配置为“ True”,hpo阶段“pipe_step: type”配置为 “SearchPipeStep”,使用以下命令进行任务启动:
export NPU_VISIBLE_DEVICES=3,4 # 使用多卡搜索/训练时的 NPU vega hpo.yml #根据实际文件名进行修改
- 单卡训练,使用以下命令进行任务启动:
- 查看超参调优结果。运行界面中会打印超参调优结果,参考如下。
2022-08-21 07:08:11.85 INFO ------------------------------------------------ 2022-08-21 07:08:11.85 INFO Pipeline end. 2022-08-21 07:08:11.85 INFO 2022-08-21 07:08:11.85 INFO task id: 0820.152508.049 2022-08-21 07:08:11.95 INFO output folder: /example/tasks/0820.152508.049/output 2022-08-21 07:08:11.95 INFO 2022-08-21 07:08:11.95 INFO running time: 2022-08-21 07:08:11.95 INFO hpo: 14:38:29 [2022-08-20 15:25:47.798652 - 2022-08-21 06:04:17.701847] 2022-08-21 07:08:11.95 INFO fully_train: 1:03:51 [2022-08-21 06:04:17.713431 - 2022-08-21 07:08:09.083200] 2022-08-21 07:08:11.96 INFO 2022-08-21 07:08:11.115 INFO result: 2022-08-21 07:08:11.116 INFO 6: {'hps': {'batch_size': 16, 'lr': 0.0058436978394671175}, 'accuracy': 0.835} 2022-08-21 07:08:11.116 INFO ------------------------------------------------- 若结果值出现 9e+16 或者 -9e+16,说明任务运行超时,或者没有正确的保存优化指标值。
- 其中输出结果中 result 部分为 fully_train 中对应 {worker_id} 的调参结果。
- 在结果所示路径下会生成tasks文件夹,tasks文件夹下有名为{task-id}的文件夹,可查看运行日志、运行结果等数据。
{task-id} ├── logs │ ├── fully_train_worker_{worker_id}.log # 第worker_id个worker上进行fully_train的日志文件 │ ├── hpo_worker_{worker_id}.log # 第worker_id个worker上进行hpo的日志文件 │ └── pipeline.log ├── output │ ├── fully_train │ │ ├── output.csv # 优化指标值汇总文件 │ │ └── performance_{worker_id}.json # 搜索出的最佳优化指标值 │ ├── hpo │ │ ├── hps_{worker_id}.json # 搜索出的最佳超参值 │ │ ├── output.csv # 优化指标值汇总文件 │ │ └── performance_{worker_id}.json # 搜索出的最佳优化指标值 │ ├── hpo.yml # 配置文件 │ └── reports.json # hpo任务的报告文件 └── workers ├── fully_train │ ├── {worker_id} │ └── {worker_id} │ └── performance_{worker_id}.json # 优化目标值 └── hpo ├── {worker_id} └── {worker_id} ├── hps_{worker_id}.json # 超参值 └── performance_{worker_id}.json # 优化目标值
