张量分解
张量分解通过分解卷积核的张量,将一个卷积转化成两个小卷积的堆叠来降低推理开销,如用户模型中存在大量卷积,且卷积核shape普遍大于(64, 64, 3, 3)时推荐使用张量分解。目前仅支持满足如下条件的卷积进行分解:
- group=1,dilation=(1,1),stride<3
- kernel_h>2,kernel_w>2
例如,用户使用的Caffe原始模型中存在Convolution层,并且该层满足上述条件,才有可能将相应的Convolution层分解成两个Convolution层,然后使用AMCT转换成可以在昇腾AI处理器部署的量化模型,以便在模型推理时获得更好的性能。
该场景为可选操作,用户自行决定是否进行原始模型的分解。
分解约束
如果Convolution层的shape过大,会造成分解时间过长或分解异常中止,为防止出现该情况,执行分解动作前,请先参见如下约束或参考数据:
- 分解工具性能参考数据:
- CPU: Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz
- 内存: 512G
分解单层卷积:
- shape(512, 512, 5, 5), 大约耗时25秒。
- shape(1024, 1024, 3, 3),大约耗时16秒。
- shape(1024, 1024, 5, 5),大约耗时78秒。
- shape(2048, 2048, 3, 3),大约耗时63秒。
- shape(2048, 2048, 5, 5),大约耗时430秒。
- 内存超限风险提醒:
分解大卷积核存在内存超限风险参考数值:shape为(2048, 2048, 5, 5)的卷积核约占用32G内存。
接口调用流程
接口调用流程如图1所示,分解示例请参见获取更多样例>tensor_decompose。

具体流程如下:
- 根据用户提供的Caffe原始模型,调用auto_decomposition生成张量分解后的模型文件以及权重文件。
- 对分解后的模型进行finetune,输出分解后的模型,如果要对该模型进行量化,则请参见训练后量化或者量化感知训练。
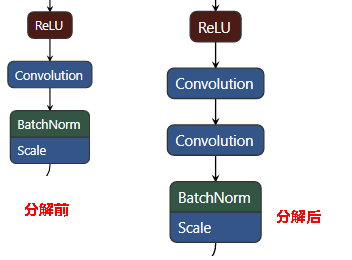
图2为resnet50网络模型分解前后的示意图。
调用示例
# 导入相关模块 from amct_caffe.tensor_decompose import auto_decomposition # 待分解模型文件 model_file = 'src_path/xxx.prototxt' # 待分解权值文件 weights_file = 'src_path/xxx.caffemodel' # 分解后保存的模型文件 new_model_file = 'decomposed_path/xxx.prototxt' # 分解后保存的权值文件 new_weights_file = 'decomposed_path/xxx.caffemodel' # 执行张量分解 auto_decomposition(model_file=model_file, weights_file=weights_file, new_model_file=new_model_file, new_weights_file=new_weights_file)
父主题: AMCT工具(Caffe)
