概述
混合精度概述
混合精度训练是在训练时混合使用单精度(float32)与半精度(float16)数据类型,将两者结合在一起,并使用相同的超参数实现了与float32几乎相同的精度。若用户使用Atlas 训练系列产品,则在迁移完成、训练开始之前,由于其架构特性限制,用户需要开启混合精度。推荐用户使用PyTorch1.8.1及以上版本框架内置的AMP功能模块来使能混合精度训练。
用户也可选择引入第三方APEX混合精度模块,使用方法可参见APEX模块。

混合精度开启可能会提升性能,但不针对所有模型生效。如果性能没有提升,则需要做进一步调优修改。
混合精度原理
float16是指采用2字节(16位)进行编码存储的一种数据类型;同理float32是指采用4字节(32位)存储的数据类型。
使用float16代替float32有如下优点:
- 内存占用减少:应用float16内存占用比float32更小,可以设置更大的batch_size。
- 加速计算:float16训练速度可以是float32的2~8倍。
图1 float32与float16数据格式示意图
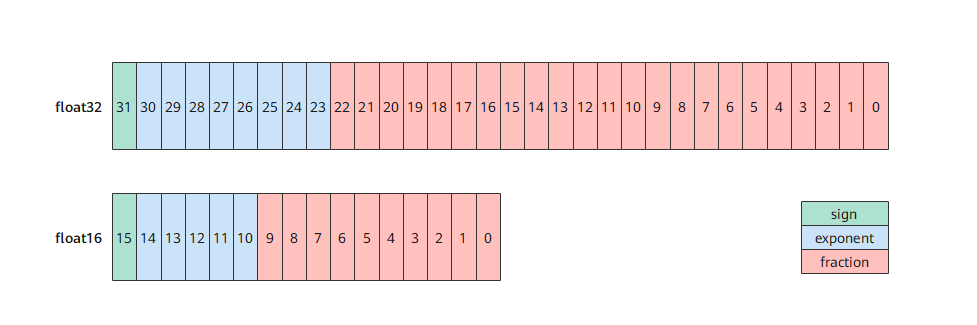
使用float16代替float32也会带来如下问题:
- 溢出错误:由于float16的值区间比float32的值区间小很多,所以在计算过程中很容易出现上溢出(Overflow,>65504)和下溢出(Underflow,<6x10^-8)的错误,溢出之后就会出现“Nan”的问题。在深度学习中,由于激活函数的梯度往往要比权重梯度小,更易出现下溢出的情况。
- 舍入误差: 舍入误差指的是当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失败。
上述问题可使用混合精度训练加上动态损失缩放(Loss Scale)来解决。大致思想和步骤简单描述如下:
- 混合精度加速:使用float16进行乘法和存储,只使用float32进行加法操作,避免累加误差。
- 损失缩放(Loss Scale):反向传播前,将损失变化手动增大2k倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出。反向传播后,将权重梯度缩2k倍,恢复正常值。
以上两点,分别是通过使用amp.autocast和amp.GradScaler来实现的。
- 用户不需要手动对模型参数的dtype进行转换,AMP会使用amp.autocast自动为算子选择合适的数值精度。autocast可以作为Python上下文管理器(Context Manager)和装饰器来使用,用来指定脚本中某个区域或者某些函数按照AMP运行。混合精度是先将float32的模型的参数拷贝一份并转换成float16。AMP规定的float16算子(例如卷积、Matmul)以float16计算。AMP规定的float32算子(例如BatchNormalize、softmax)在输入和输出时精度为float16,计算时为float32,在反向传播时依然是混合精度计算,得到数值精度为float16的梯度。优化器的操作是利用float16的梯度对float32的参数进行更新。
- 对于反向传播时float16的梯度数值溢出的问题,AMP使用amp.GradScaler提供梯度缩放(scale)操作。在优化器更新参数前,AMP会自动对梯度缩放进行还原(unscale),所以对用于模型优化的超参数不会有任何影响。
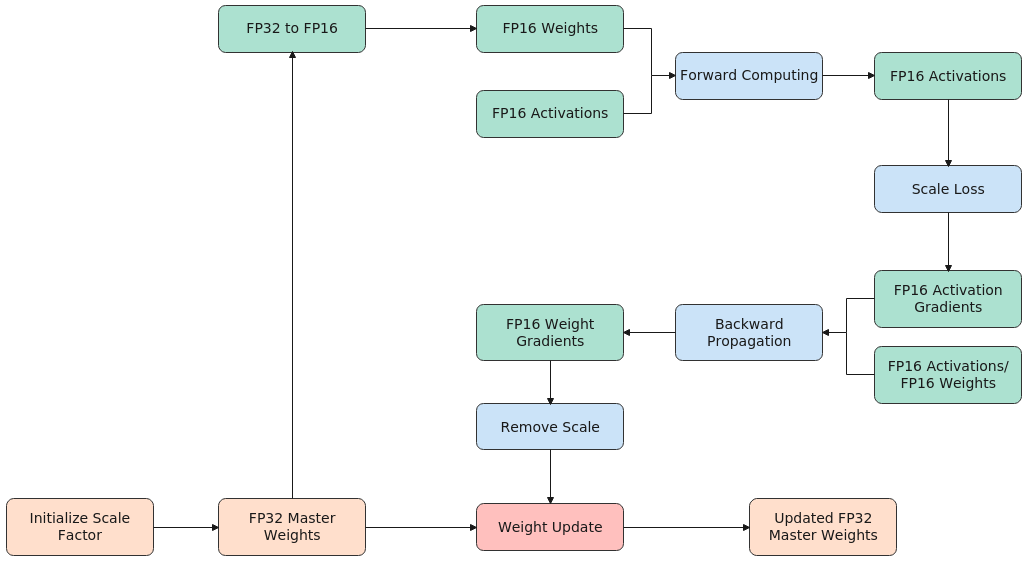
混合精度计算过程
AMP的基本计算过程如下:
- 拷贝并维护一个float32数值精度模型的副本。
- 初始化缩放系数(scale factor)。
- 精度转换,每个迭代计算一次。
- 拷贝参数并转换为float16模型精度。
- 正向传播(float16的模型参数)。
- Loss乘缩放系数。
- 反向传播(float16的模型参数与参数梯度)。
- 参数梯度除以缩放系数。
- 利用float16的梯度更新float32的模型参数。
AMP计算过程图如下所示。
图2 AMP计算过程图
父主题: 自动混合精度(AMP)
