'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
数据dump比对场景
通常情况下,用户可以优先选择整网dump数据比对,常见现象为loss不收敛。注意在dump CPU或GPU、NPU数据时,使用的torch版本要保持一致。
单卡场景
- 参考工具安装,完成ptdbg_ascend组件包安装。dump整网数据。分别dump CPU或GPU以及NPU数据,在PyTorch训练脚本插入dump接口,示例代码如下(下面以NPU为例,CPU或GPU dump基本相同):
from ptdbg_ascend import register_hook, overflow_check, seed_all, set_dump_path, set_dump_switch, acc_cmp_dump # 在main函数开始前固定随机数 seed_all() # 配置dump数据的路径 set_dump_path("./data/dump", dump_tag='all') # 注册dump回调函数 register_hook(model, acc_cmp_dump) ... # 在第一个迭代开始的位置开启dump和堆栈模式,同时为保证数据完整性开启dump bool和整型的tensor以及浮点、bool和整型的标量。 set_dump_switch("ON", mode="api_stack", filter_switch="OFF") ... # 在第一个迭代结束的位置关闭dump set_dump_switch("OFF")dump文件目录结构如下,dump文件目录结构说明可参考dump文件目录结构。
all_v1.0 └── rank1 ├── api_stack_dump │ ├── Functional_conv2d_0_forward_input.0.npy │ ├── Functional_conv2d_0_forward_output.npy │ ..... │ ├── Torch_relu__9_forward_input.0.npy │ └── Torch_relu__9_forward_output.npy └── api_stack_dump.pkl - 比对整网数据。参考比对脚本compare.py配置示例创建并配置精度比对脚本,以创建compare.py为例,示例代码如下:
from ptdbg_ascend import compare dump_result_param={ "npu_pkl_path": "./npu/ptdbg_dump_v2.0/rank0/dump.pkl", "bench_pkl_path": "./cpu/ptdbg_dump_v2.0/rank0/dump.pkl", "npu_dump_data_dir": "./npu/ptdbg_dump_v2.0/rank0/dump", "bench_dump_data_dir": "./cpu/ptdbg_dump_v2.0/rank0/dump" "is_print_compare_log": True } compare(dump_result_param, "./output", stack_mode=True)执行比对:python3 compare.py
脚本中设置了“is_print_compare_log”为True,则部分回显如下所示:
start comapre: Functional_conv2d_0_forward_input.0 start comapre: Functional_conv2d_0_forward_input.1 start comapre: Functional_conv2d_0_forward_output start comapre: Functional_batch_norm_0_forward_input.0 start comapre: Functional_batch_norm_0_forward_input.1 [Functional_conv2d_0_forward_input.1] Compare result: cosine 0.000649, max_abs_err 0.134957, start comapre: Functional_batch_norm_7_forward_input.0 start comapre: Functional_batch_norm_0_forward_input.2 start comapre: Functional_batch_norm_0_forward_input.3 [Functional_conv2d_0_forward_input.0] Compare result: cosine 1.0, max_abs_err 0.000000, start comapre: Functional_conv2d_7_forward_output start comapre: Functional_batch_norm_0_forward_input.4 [Functional_batch_norm_0_forward_input.3] Compare result: cosine 1.0, max_abs_err 0.000000, start comapre: Functional_batch_norm_7_forward_output [Functional_batch_norm_0_forward_input.1] Compare result: cosine 1.0, max_abs_err 0.000000, start comapre: Functional_batch_norm_7_forward_input.3 start comapre: Functional_batch_norm_0_forward_output [Functional_batch_norm_0_forward_input.2] Compare result: cosine 1.0, max_abs_err 0.000000, start comapre: Functional_batch_norm_7_forward_input.4 ...
比对完成后会在指定的输出目录中生成对比结果文件“compare_result_timestamp.csv”,示例文件如下所示。
图1 示例文件 图2 比对结果展示
图2 比对结果展示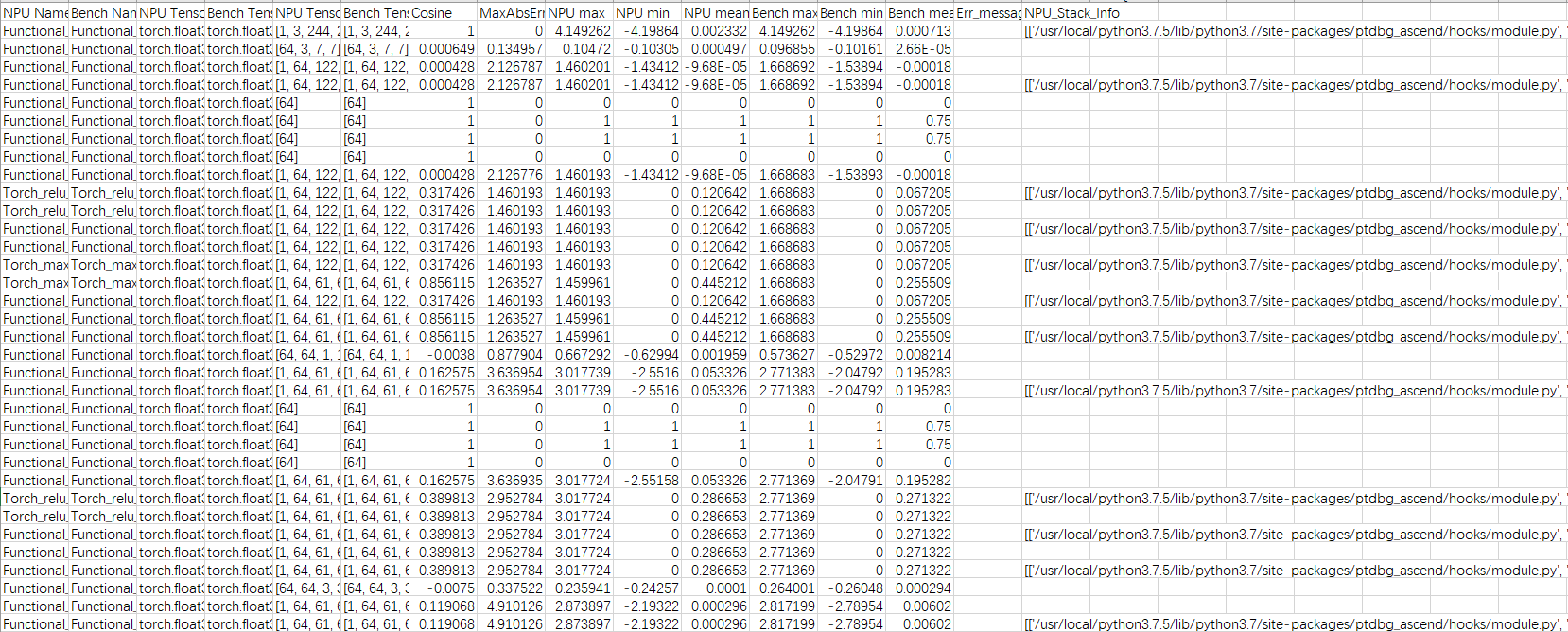
- 查看比对结果文件,找出存在问题的API。
例如在比对结果的csv文件中,通过对比dump出的数值,计算两者的余弦相似度、均方根误差和最大绝对误差,定位和排查NPU算子存在的计算精度问题。筛选出余弦相似度(Cosine)小于0.99,最大绝对值误差(MaxAbsError)大于0.001的第一个API,针对该API执行后续比对操作,分析该API存在的精度问题。
多卡场景

- 多卡一般为多进程,须保证每个进程都正确调用set_dump_path,或把set_dump_path插入到import语句后,如:
from ptdbg_ascend import * seed_all() set_dump_path('./data/dump')如此可保证set_dump_path在每个进程都被调用。
- register_hook需要在set_dump_path之后调用,也需要在每个进程上被调用,建议在搬运模型数据到卡之后调用。识别方法如下:
- 找到训练代码中遍历epoch的for循环或遍历数据集的for循环,把register_hook放到循环开始前即可。
- 找到训练代码中调用DDP或者DistributedDataParallel的代码行,把register_hook放到该代码行所在的代码块之后。
- 若代码中均无以上两种情况,需要保证register_hook在模型定义之后插入,并配置rank参数,示例如下:
register_hook(model, acc_cmp_dump, rank=rank_id)
- 两次运行须用相同数量的卡,传入compare_distributed的两个文件夹下须有相同个数的rank文件夹,且不包含其他无关文件,否则将无法比对。
精度工具多卡场景下的精度比对步骤与单卡场景基本一致。不同的是精度比对时需要使用compare_distributed函数进行比对:
多机多卡场景需要每个设备单独执行比对操作。
- 参考工具安装,完成ptdbg_ascend组件包安装。创建比对脚本,例如compare_distributed.py。
from ptdbg_ascend import * compare_distributed('npu_dump/dump_conv2d_v1.0', 'gpu_dump/dump_conv2d_v1.0', './output') - 执行比对。
python3 compare_distributed.py
完成比对后会生成比对结果文件。
图3 生成文件
父主题: 精度调测
