(推荐)Ascend PyTorch Profiler数据采集与分析
概述
Ascend PyTorch Profiler是针对PyTorch框架开发的性能数据采集和解析工具,通过在PyTorch训练脚本中插入Ascend PyTorch Profiler接口,执行训练的同时采集性能数据,完成训练后直接输出可视化的性能数据文件,提升了性能分析效率。Ascend PyTorch Profiler接口可全面采集PyTorch训练场景下的性能数据,主要包括PyTorch层算子信息、CANN层算子信息、底层NPU算子信息、以及算子内存占用信息等,可以全方位分析PyTorch训练时的性能状态。
采集并解析性能数据
- 使用Ascend PyTorch Profiler接口开启PyTorch训练时的性能数据采集。在训练脚本(如train_*.py文件)内添加如下示例代码进行性能数据采集参数配置,之后启动训练。下列示例代码中,加粗字段为需要配置的参数、方法、类和函数。
experimental_config = torch_npu.profiler._ExperimentalConfig( aic_metrics=torch_npu.profiler.AiCMetrics.PipeUtilization, profiler_level=torch_npu.profiler.ProfilerLevel.Level1, l2_cache=False ) with torch_npu.profiler.profile( activities=[ torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU ], schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=2, repeat=2, skip_first=10), on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./result"), record_shapes=True, profile_memory=True, with_stack=True, with_flops=False, with_modules=False, experimental_config=experimental_config) as prof: for step in range(steps): train_one_step(step, steps, train_loader, model, optimizer, criterion) prof.step()除了使用tensorboard_trace_handler导出性能数据外,还可以使用以下方式导出:with torch_npu.profiler.profile() as prof: for step in range(steps): train_one_step(step, steps, train_loader, model, optimizer, criterion) prof.export_chrome_trace('./chrome_trace_14.json')表1 torch_npu.profiler.profile配置参数说明 参数名称
参数含义
是否必选
activities
CPU、NPU事件采集列表,Enum类型。取值为:
- torch_npu.profiler.ProfilerActivity.CPU:框架侧数据采集的开关。
- torch_npu.profiler.ProfilerActivity.NPU:CANN软件栈及NPU数据采集的开关。
默认情况下两个开关同时开启。
否
schedule
设置不同step的行为,Callable类型。由schedule类控制。
否
on_trace_ready
采集结束时自动执行操作,Callable类型。当前仅支持执行tensorboard_trace_handler函数的操作,默认不执行任何操作。
否
record_shapes
算子的InputShapes和InputTypes,Bool类型。取值为:
- True:开启。
- False:关闭。默认值。
开启torch_npu.profiler.ProfilerActivity.CPU时生效。
否
profile_memory
算子的内存占用情况,Bool类型。取值为:
- True:开启。
- False:关闭。默认值。
否
with_stack
算子调用栈,Bool类型。取值为:
- True:开启。
- False:关闭。默认值。
开启torch_npu.profiler.ProfilerActivity.CPU时生效。
否
with_flops
算子浮点操作,Bool类型(该参数暂不支持解析性能数据)。取值为:
- True:开启。
- False:关闭。默认值。
开启torch_npu.profiler.ProfilerActivity.CPU时生效。
否
with_modules
with_stack时modules分层信息,Bool类型(该参数暂不支持解析性能数据)。取值为:
- True:开启。
- False:关闭。默认值。
开启torch_npu.profiler.ProfilerActivity.CPU时生效。
否
experimental_config
扩展参数,通过扩展配置性能分析工具常用的采集项。支持采集项和详细介绍请参见《性能分析工具使用指南》中“PyTorch训练/在线推理场景性能分析 > experimental_config扩展参数”。
否
表2 torch_npu.profiler.profile方法说明 方法名
含义
step
划分不同迭代。
export_chrome_trace
导出trace。在指定的.json文件里写入trace数据。trace为Ascend PyTorch Profiler接口整合框架侧CANN软件栈及NPU数据后展示的各算子和接口的运行时间及关联关系。
在设置了torch_npu.profiler.tensorboard_trace_handler的情况下,export_chrome_trace不生效。
表3 torch_npu.profiler类、函数说明 类、函数名
含义
torch_npu.profiler.schedule
设置不同step的行为。取值为:
- skip_first:采集前先跳过的step轮数。默认为值0。可选。建议跳过前10轮。
- wait:每次重复执行采集跳过的step轮数。必选。
- warmup:预热的step轮数。必选。建议设置1轮预热。
- active:采集的step轮数。必选。
- repeat:重复执行wait+warmup+active的次数。默认为值0。可选。
默认不执行该操作。
torch_npu.profiler.tensorboard_trace_handler
将采集到的性能数据导出为TensorBoard工具支持的格式。取值为:
- dir_name:采集的性能数据的输出目录。必选。
- worker_name:用于区分唯一的工作线程,默认为{hostname}_{pid}。可选。
torch_npu.profiler.ProfilerAction
Profiler状态,Enum类型。取值为:
- NONE:无任何行为。
- WARMUP:性能数据采集预热。
- RECORD:性能数据采集。
- RECORD_AND_SAVE:性能数据采集并保存。
- 查看采集到的PyTorch训练性能数据结果文件。
训练结束后,在torch_npu.profiler.tensorboard_trace_handler接口指定的目录下生成Ascend PyTorch Profiler接口的采集结果目录。
└── localhost.localdomain_139247_20230628101435_ascend_pt // 解析结果目录,命名格式:{worker_name}_{时间戳}_ascend_pt,默认情况下{worker_name}为{hostname}_{pid} ├── ASCEND_PROFILER_OUTPUT // Ascend PyTorch Profiler接口采集性能数据 │ ├── data_preprocess.csv // experimental_config开启torch_npu.profiler.ProfilerLevel.Level2生成 │ ├── kernel_details.csv │ ├── l2_cache.csv // experimental_config开启l2_cache生成 │ ├── memory_record.csv │ ├── operator_details.csv │ ├── operator_memory.csv │ └── trace_view.json ├── FRAMEWORK // 框架侧的性能原始数据,无需关注 │ ├── torch.memory_usage │ ├── torch.op_mark │ └── torch.op_range └── PROF_000001_20230628101435646_FKFLNPEPPRRCFCBA // CANN层的性能数据,命名格式:PROF_{数字}_{时间戳}_{字符串} │ ├── device_x │ └── host - 使用TensorBoard工具进行性能数据分析。
- 安装依赖。
pip3 install pandas==1.0.0 pip3 install tensorboard==2.11.0
要求pandas >= 1.0.0,tensorboard >= 2.11.0。
- 下载TensorBoard工具并安装。
pip3 install torch_tb_profiler_ascend-0.4.0-py3-none-any.whl
- 查看是否安装成功。
pip3 list | grep torch-tb
显示如下信息表示安装成功。torch-tb-profiler-ascend 0.4.0
- 启动工具。
tensorboard --logdir=./result
--logdir指定待解析的性能数据目录。
若是远程服务器启动TensorBoard想要在本机查看性能数据,需使用--bind_all参数。
tensorboard --logdir=./result --bind_all
回显如下:I0630 14:08:16.533923 281470215713104 plugin.py:454] Monitor runs begin I0630 14:08:16.536316 281470215713104 plugin.py:470] Find run directory /home/pzr I0630 14:08:16.539052 281470299730256 plugin.py:552] Load run .. I0630 14:08:16.561225 281470299730256 loader.py:73] started all processing TensorBoard 2.8.0 at http://localhost:6006/ (Press CTRL+C to quit) I0630 14:08:43.961050 281470299730256 plugin.py:556] Run .. loaded I0630 14:08:43.961973 281470257721680 plugin.py:493] Add run ..
- 查看性能数据。
将回显中加粗的URL复制,并使用浏览器访问(若为远端服务器则需要将域名“localhost”替换为远端服务器的IP),进入TensorBoard工具界面。
图1 工具页面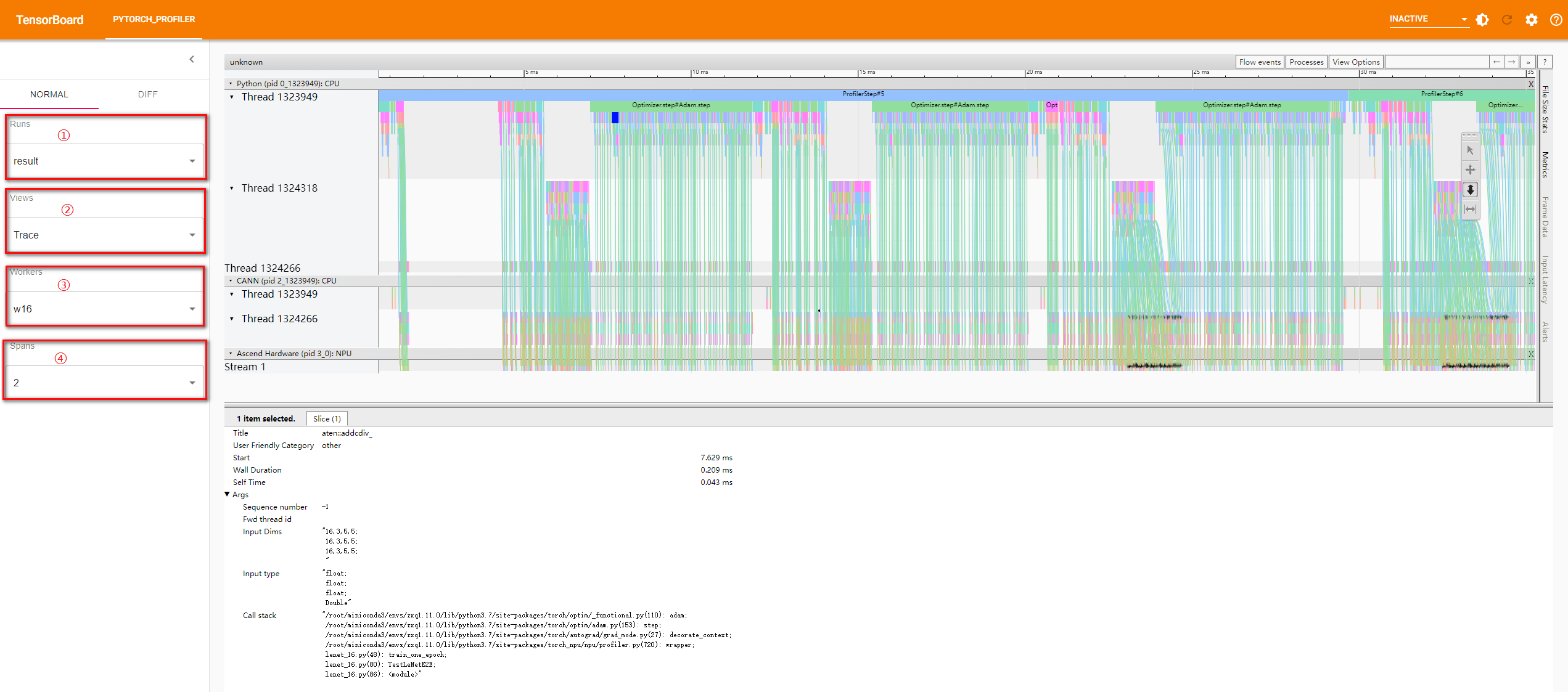
工具界面通过左侧侧边栏进行视图切换:
- Runs(红框①)用于切换展示的性能数据文件。
- Views(红框②)用于切换右侧性能数据详细视图,TensorBoard主要通过该功能进行性能数据分析,详细分析方法请参见性能分析方法。
- Workers(红框③)、Spans(红框④)用于切换不同进程和不同时间产生的数据。
- 安装依赖。

性能分析方法
TensorBoard工具主要通过Trace View、Kernel View、Operator View和Memory View来展示PyTorch性能数据:
- Trace View:主要展示从上层应用下发到下层NPU算子的过程中所有算子的执行耗时以及上下层算子直接的调用关系,因此,该视图主要通过观察各个层级上的耗时长短、间隙等判断对应组件、算子是否存在性能问题。
- Kernel View:包含在NPU上执行的所有算子的信息,主要用于进一步确认高耗时算子。
- Operator View:统计PyTorch算子在Host侧(下发)和Device侧(执行)的耗时,同样通过耗时判断性能问题,并且可以通过Call stack找到该算子对应的底层调用关系从而定位到具体代码行。
- Memory View:主要展示PTA和GE内存申请情况信息,以及分配给底层算子的详细信息,可以找出占用内存最大的算子。
详细示例请参见性能分析(Trace View)、性能分析(Kernel View)、性能分析(Operator View)和性能分析(Memory View)。
性能分析(Trace View)
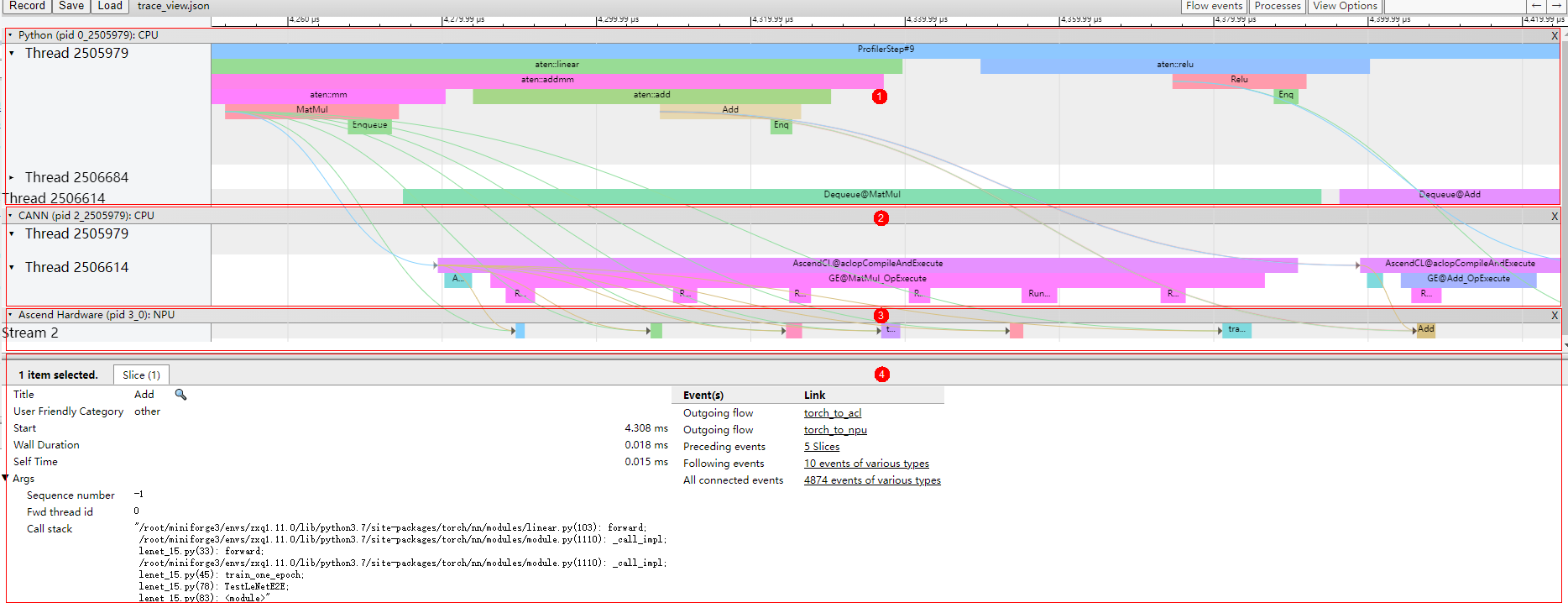
如图2所示,trace数据主要展示如下区域:
- 区域1:上层应用数据,包含上层应用算子的耗时信息。
- 区域2:CANN层数据,主要包含AscendCL、GE和Runtime组件的耗时数据。
- 区域3:底层NPU数据,主要包含Task Schduler组件耗时数据和迭代轨迹数据以及其他昇腾AI处理器BS9SX1A AI处理器AS31XM1X AI处理器SoC系统数据。
- 区域4:展示trace中各算子、接口的详细信息。单击各个trace事件时展示。
Trace View下的性能数据建议通过观察各个层级上的耗时长短、间隙等判断对应组件、算子是否存在性能问题。
- 示例一:算子下发瓶颈识别,优化方法可参见算子下发性能优化。
建议的优化方式有:增加batch size、绑核&高性能模式、使用NPU亲和优化器、自定义融合算子优化,具体优化视情况而定。
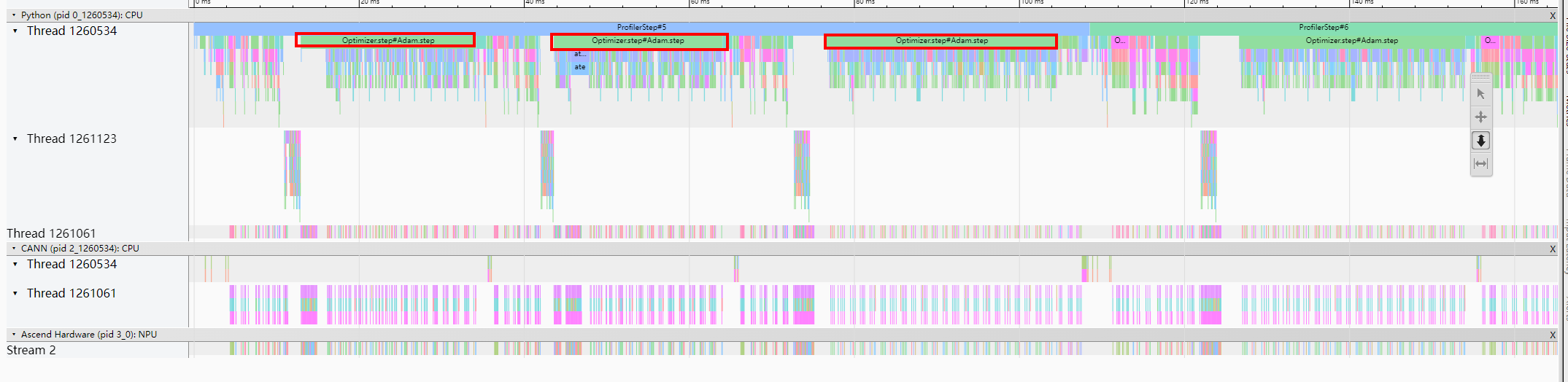
- 示例二:原生优化器耗时,可参见NPU亲和优化器替换。
开启混合精度时,原生优化器耗时过长,如图5所示。
请使用华为亲和优化器接口apex.optimizers.NpuFusedxxx替代原生优化器来提升性能,如图6所示。
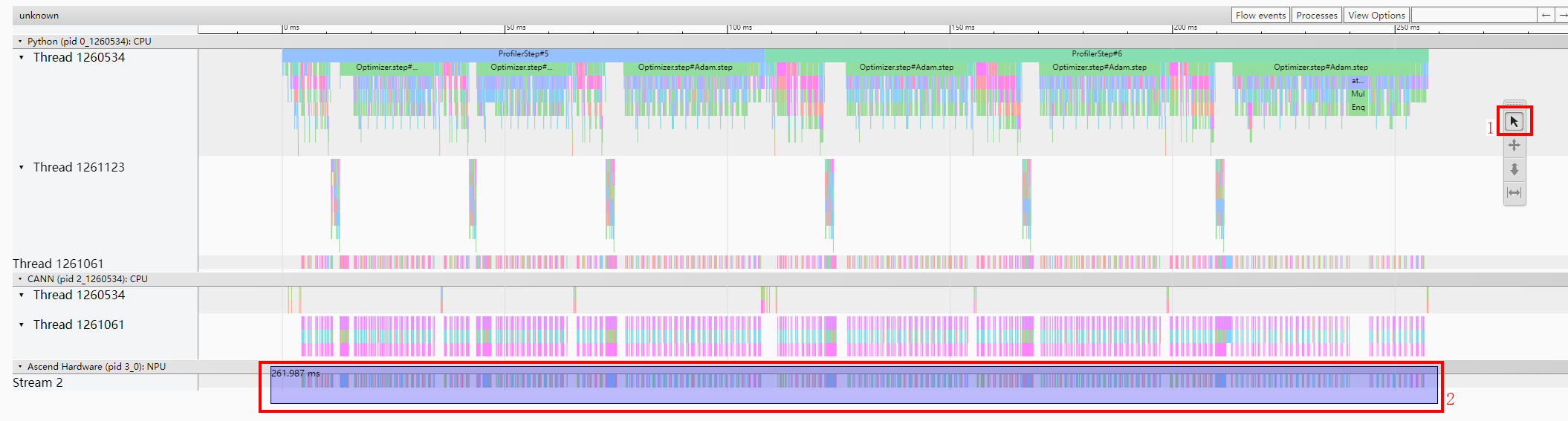
- 示例三:kernel耗时
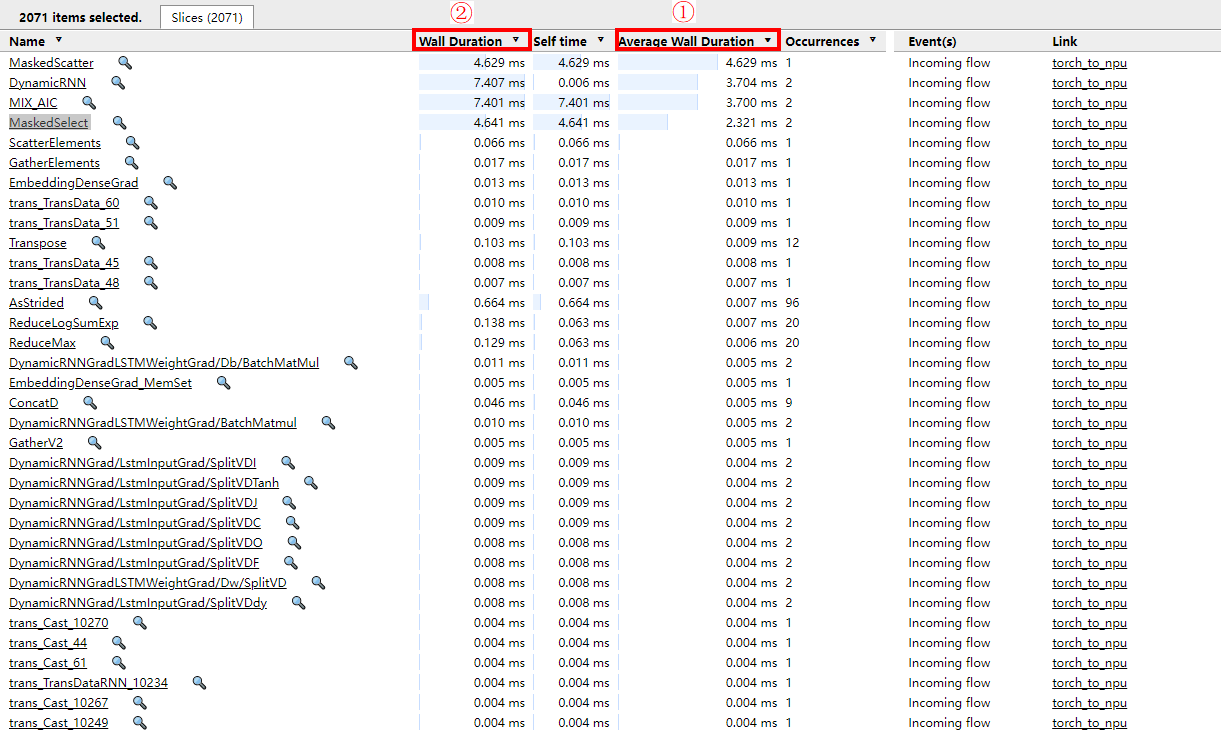
如图7所示,选中所有NPU栏目的色块,trace会自动帮助统计不同名称kernel的总耗时、平均耗时、调用次数等指标。如图8所示,单击Average Wall Duration进行倒序排序,查看耗时Top的kernel,观察发现MaskedScatter、DynamicRNN、MIX_AIC、MaskedSelect为明显性能较差的算子。再结合Wall Duration字段,查看该算子耗时占所有kernel总耗时的比例,判定该算子的优化能够带来的性能收益,以确定优先优化的kernel,可联系华为工程师进行具体优化。
- 示例四:转换类算子插入识别
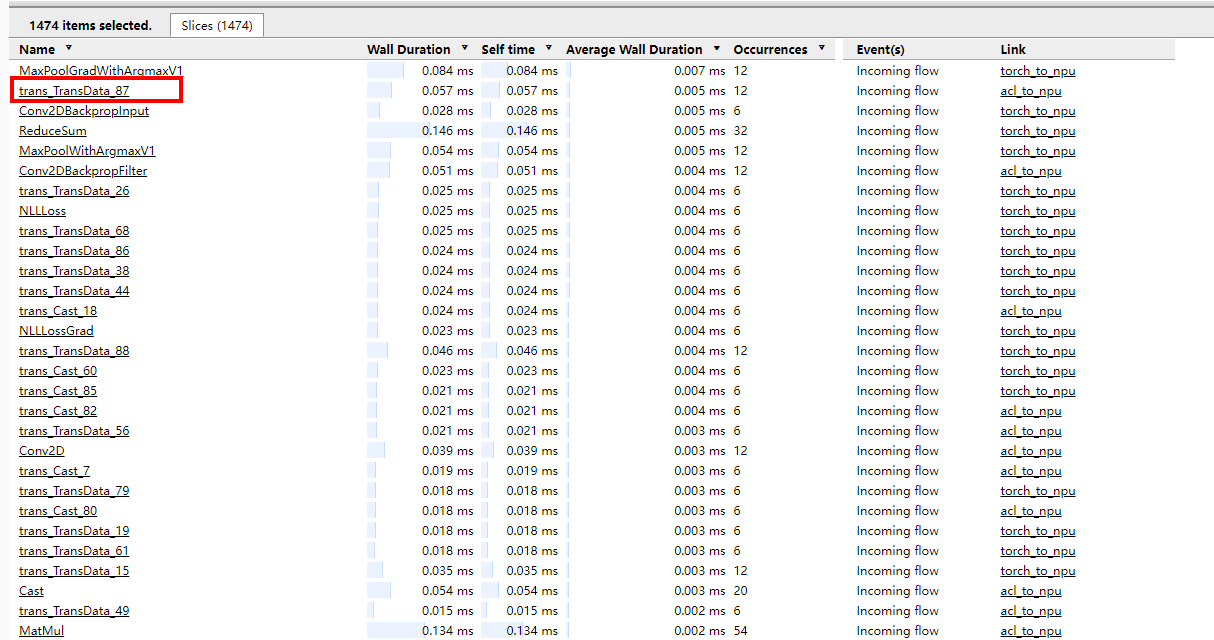
通过示例三的方式找出耗时Top的kernel,若Top算子存在转换类算子,如图9示例。
则可通过调用栈(Call stack)信息定位到具体的代码行。单击算子的名称跳转到对应算子的详细信息,如图10示例。
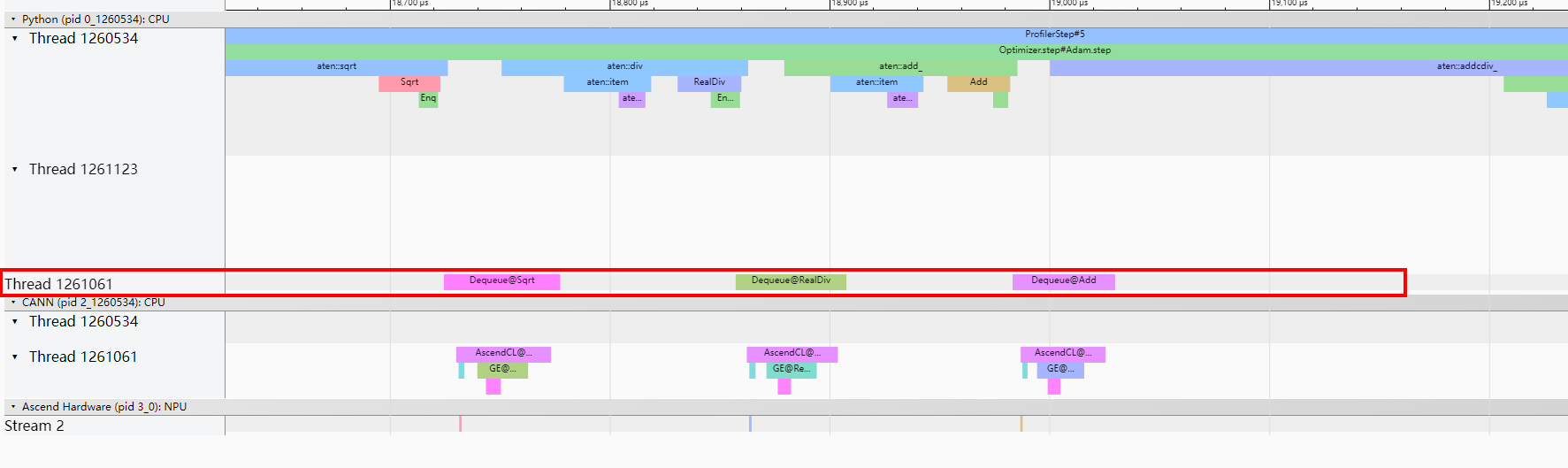
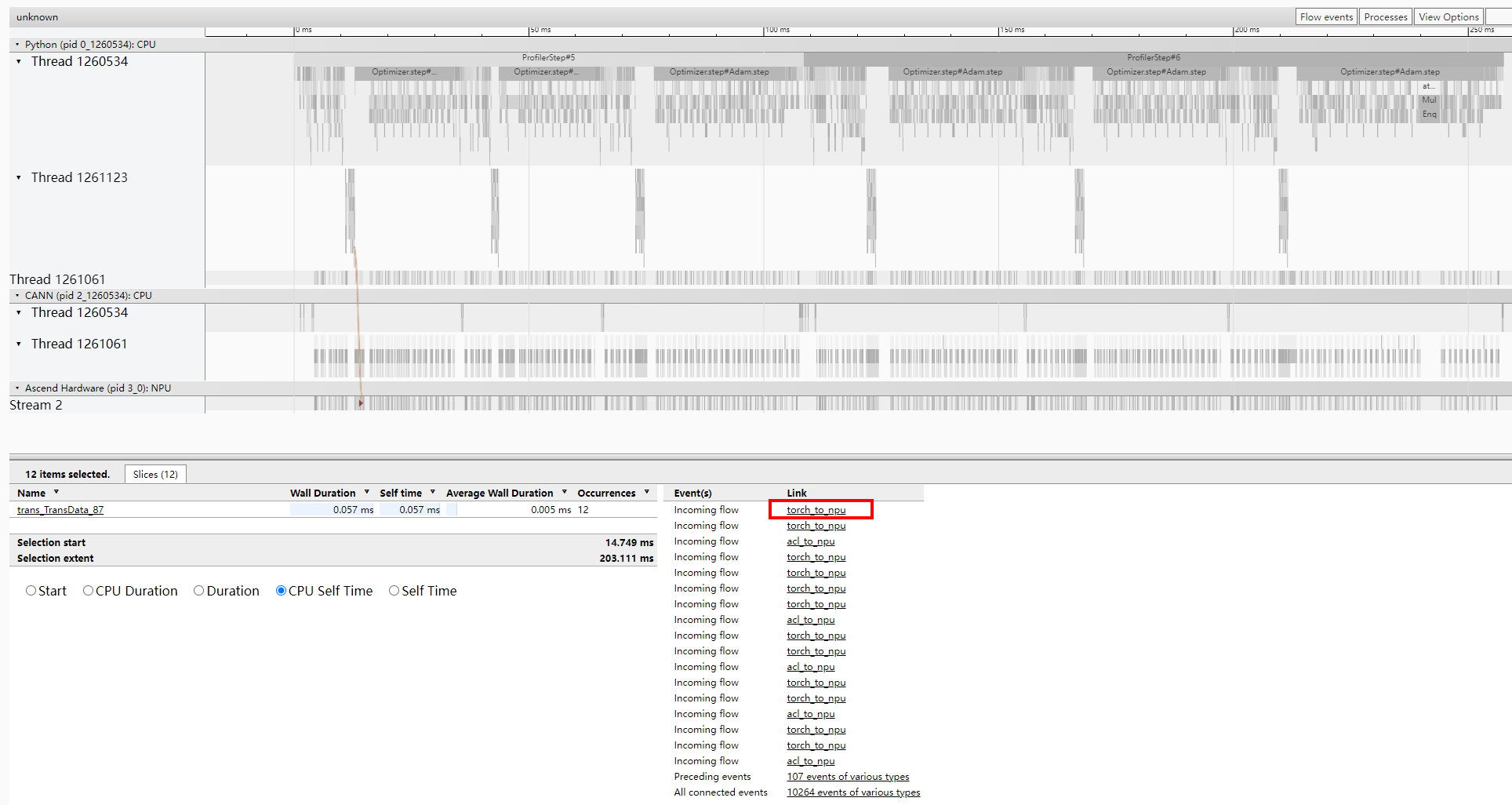
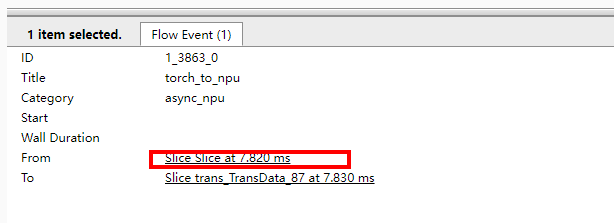
查看Events(s)列的Incoming flow表示Link列下的算子为trans_TransData_87的上游算子,单击Incoming flow表示Link列下的其中一个算子torch_to_npu,跳转至图11。
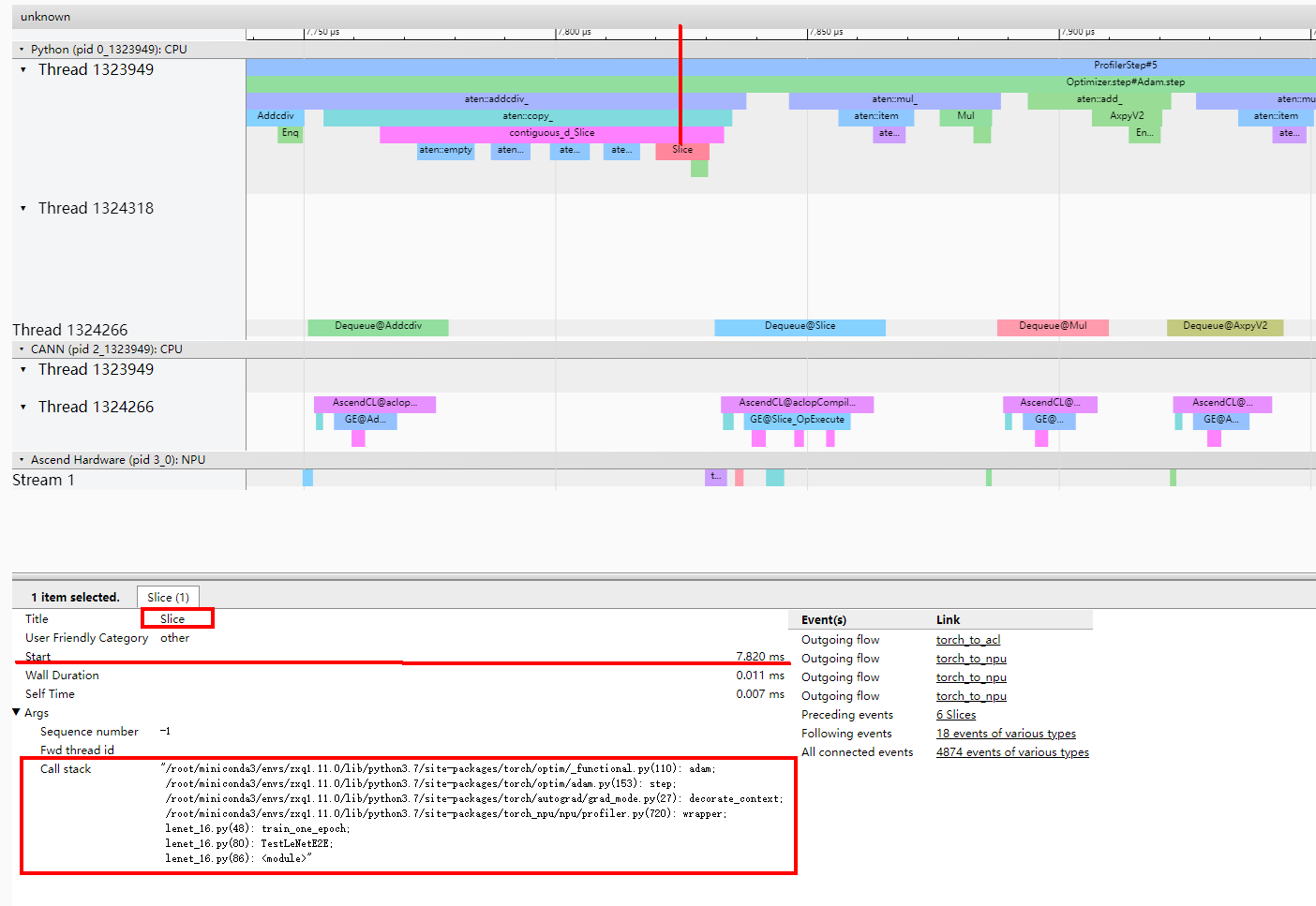
从torch_to_npu明细的From字段信息可以看出,Slice算子在trace中的第7.820 ms为torch_to_npu的上游算子,如图12所示。
从Slice明细的Call stack字段信息可以读取到具体调用的代码行。转换类算子的优化可参见格式转换优化进行格式转换。


性能分析(Kernel View)
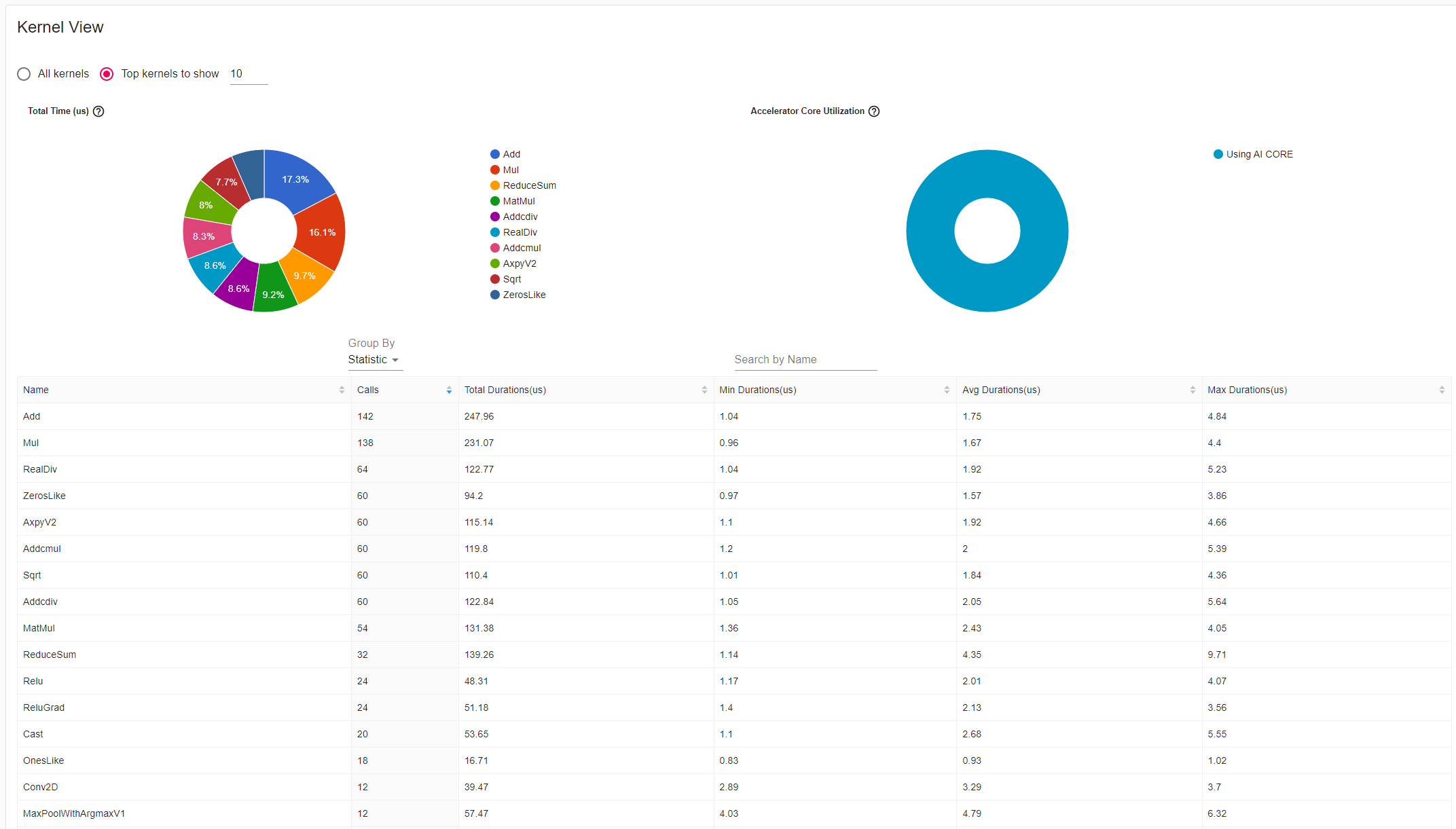
Kernel View为kernel_details.csv文件的TensorBoard可视化呈现,包含在NPU上执行的所有算子的信息,如图13所示。
左侧饼图统计不同名称的kernel总耗时占比;右侧饼图统计在不同加速核上执行时间的占比;下方列表Group By选择Statistic时,展示按kernel的名称汇总统计的执行信息。
列表Group By选择All时,展示所有kerenl执行的明细信息,如图14所示。
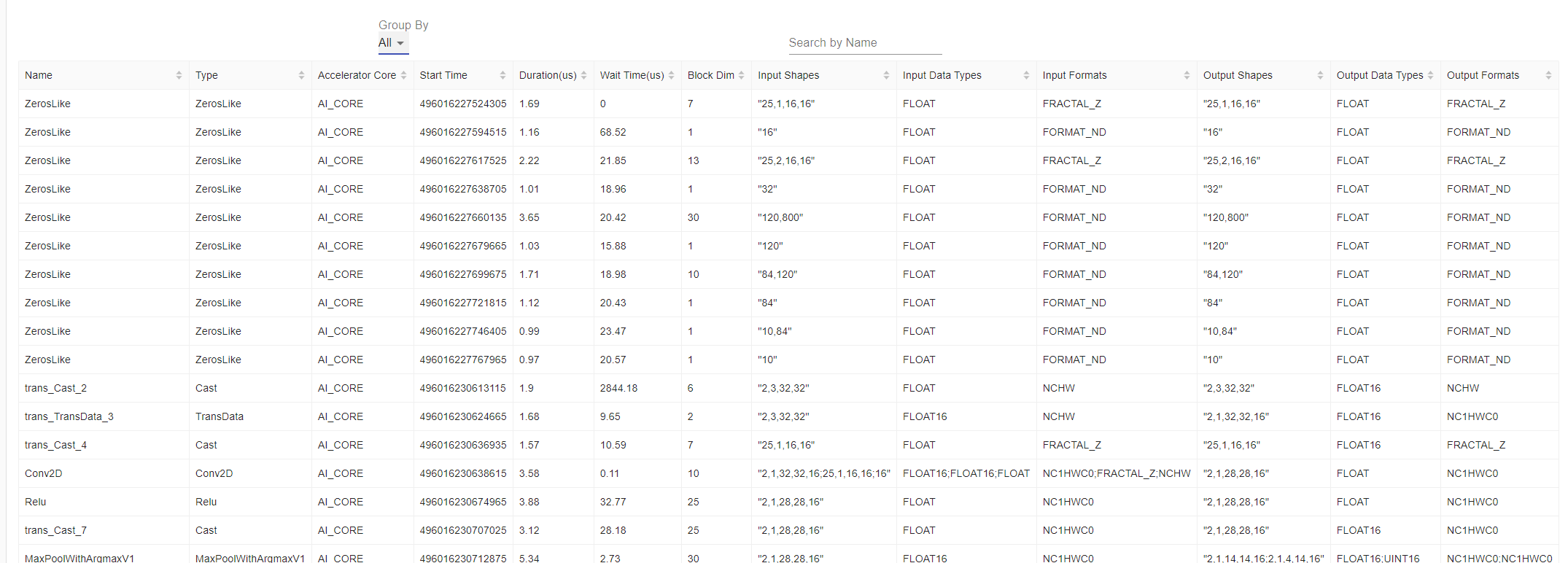
可以根据左侧饼图中耗时多的算子,联系华为工程师进一步排查。
性能分析(Operator View)
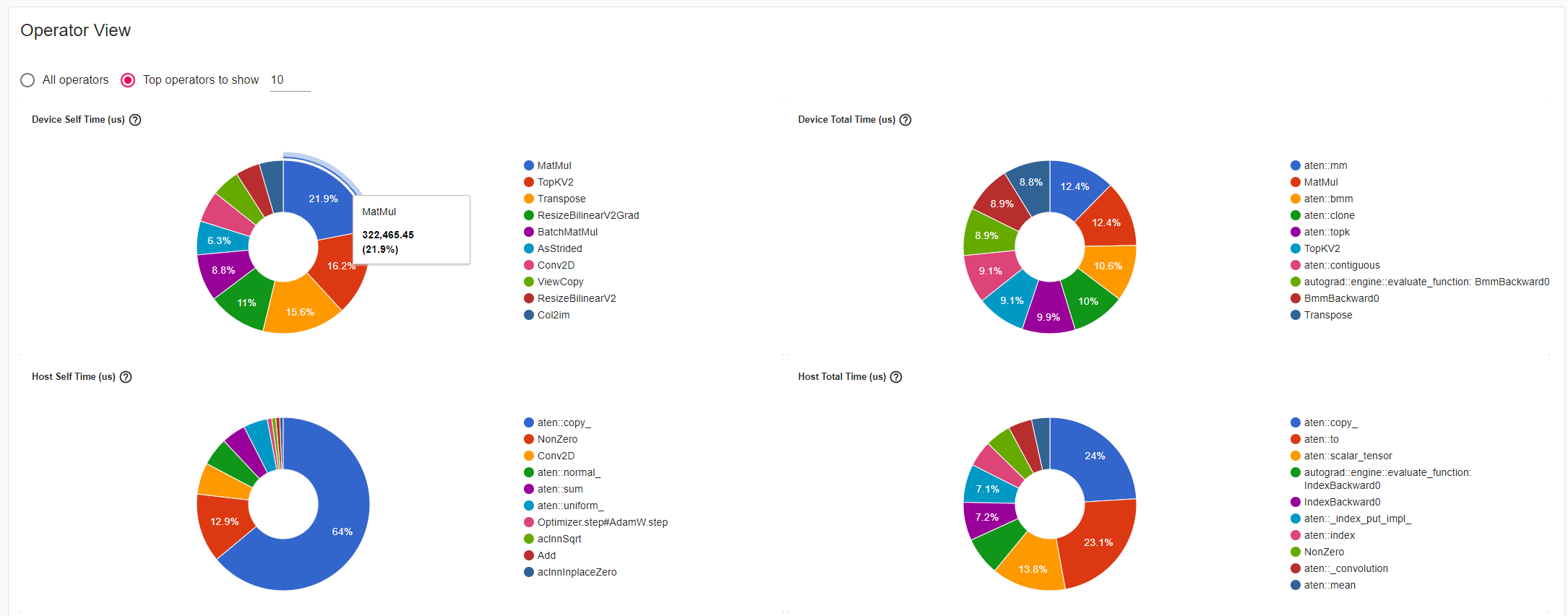
Operator View为operator_details.csv文件的TensorBoard可视化呈现,是统计PyTorch算子在Host侧(下发)和Device侧(执行)的耗时,如图15所示。
- Device Self Duration饼图统计由该算子直接下发,在Device上执行的总耗时。
- Device Total Duration饼图统计由该算子及其内部调用的其他算子下发,在Device上执行的总耗时。
- Host Self Duration饼图统计该算子在Host上执行的总耗时,不包括内部调用的其他算子。
- Host Total Duration饼图统计该算子及其内部调用的其他算子在Host上执行的总耗时。
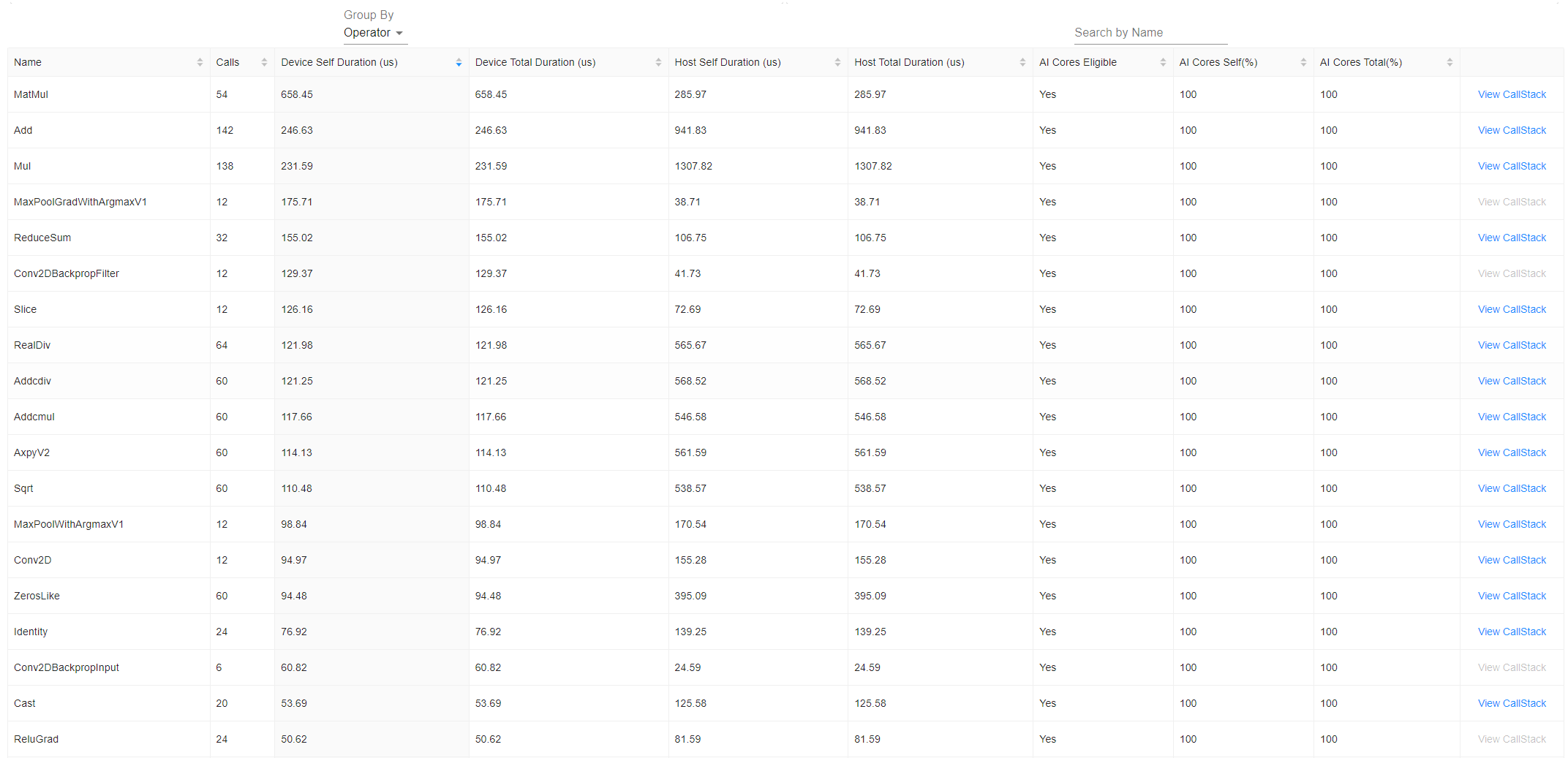
下方列表为上方饼图的明细呈现,如图16所示。
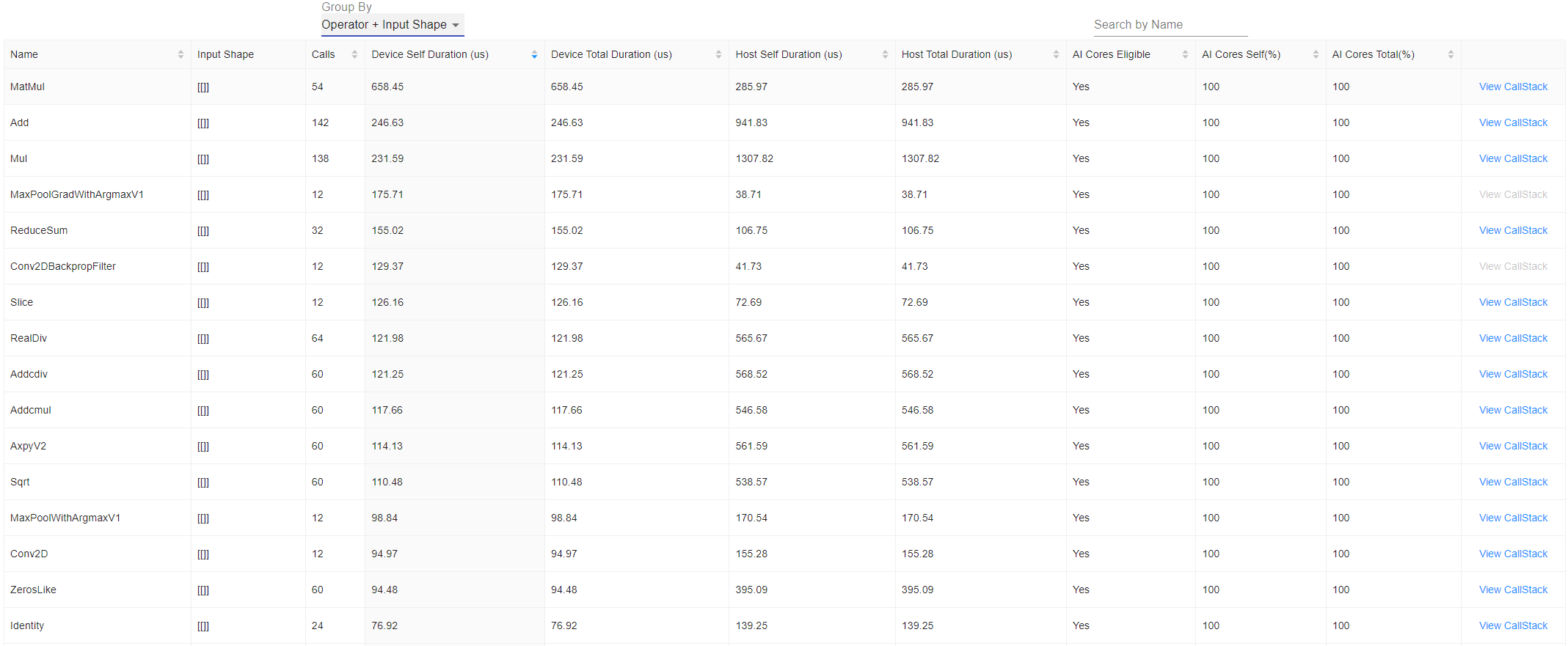
Group By选择Operator+Input Shape时,列表展示算子的输入Shape信息,如图17所示。
可以先根据耗时信息判断高耗时且存在性能瓶颈的算子,再通过单击View CallStack,呈现算子调用栈信息。以图18为例,MatMul有4种不同的调用栈,单击View call frames,可查看具体的调用栈信息。
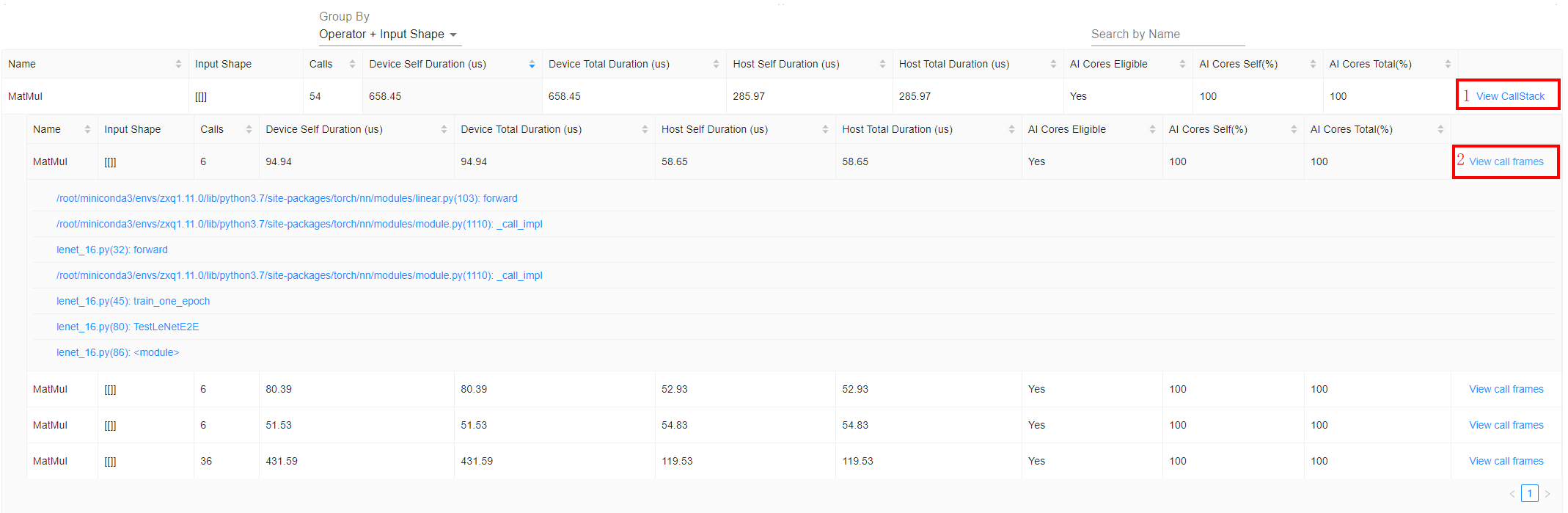
通过调用栈信息找到具体调用的代码行,联系华为工程师进一步排查。
性能分析(Memory View)
Memory View为operator_memory.csv和memory_record.csv文件的TensorBoard可视化呈现,包含PTA和GE内存申请情况信息,如图19所示。
- Group By选择Operator时,展示算子在NPU上执行时的内存占用明细表和折线图,其中内存由PTA和GE申请。
- Group By选择Component时,展示PTA和GE组件的内存占用明细表和折线图。
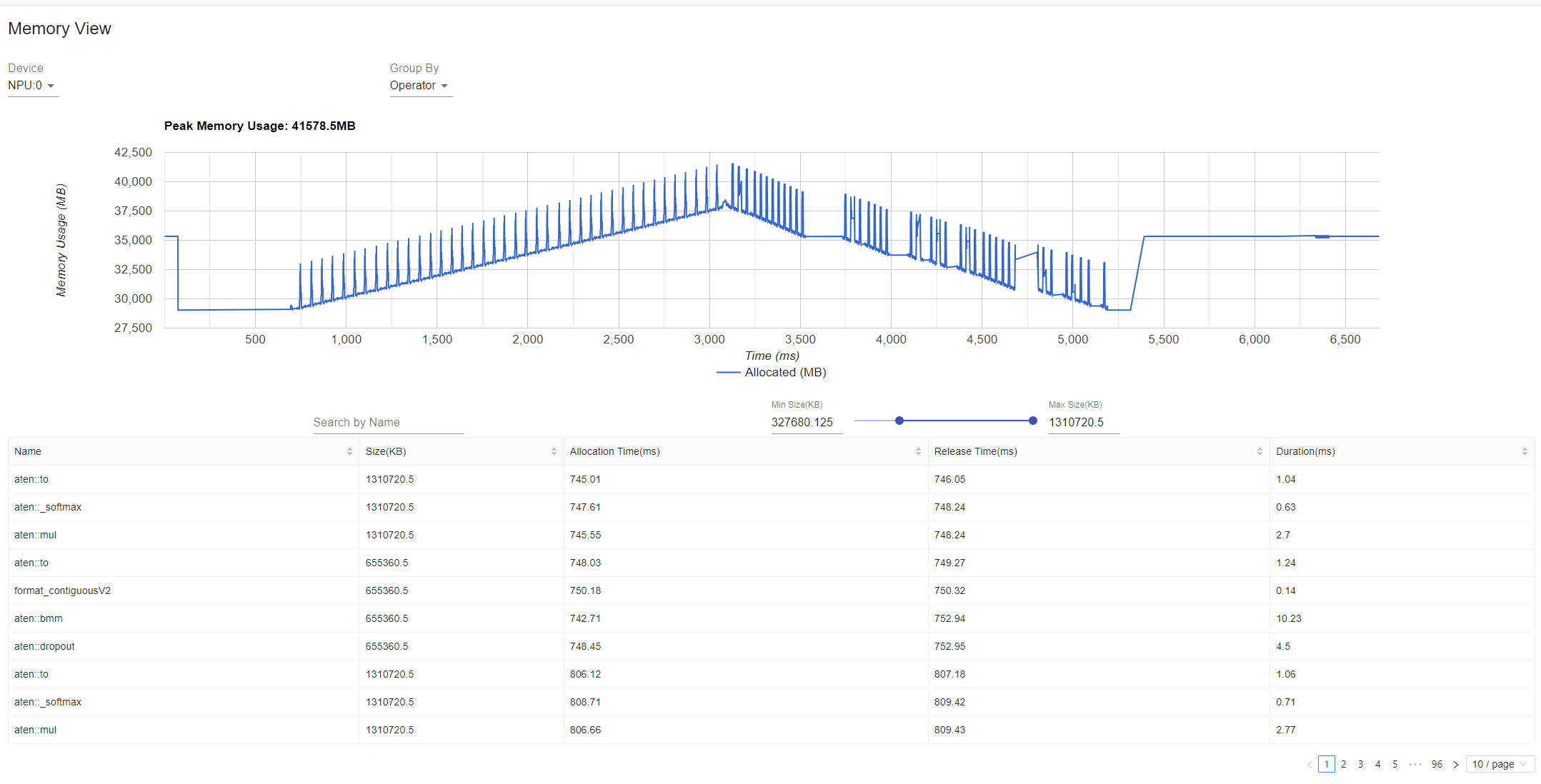
从Memory View图中可以看出算子在每个时刻否内存占用情况,一般来说对一个完整的迭代进行性能数据采集即可看到这个迭代算子内存的生命周期(迭代开始前的内存申请是模型初始化时的内存申请)。
根据算子的内存申请及内存时间,分析相关内存问题,将内存峰值减小。
可以从耗内存最大的算子开始排查,从而减小NPU内存的使用。
