E2E Profiling数据采集与分析
概述
在进行调优之前,需要通过profiling采集性能数据,进行分析来定位问题。在PyTorch层面采集的数据记录了PyTorch框架层面的算子在多次分发中调用栈的耗时信息,可以获取算子耗时信息、算子的input shape、使用的NPU内存等信息。在CANN层面展示的数据分为GE/ACL/RunTime/AI CPU/device等多个模块。
采集并解析性能数据
- 获取性能数据文件。
with torch_npu.npu.profile(profiler_result_path="./result",use_e2e_profiler=True): model_train()- profiler_result_path表示profiling结果保存路径,默认为当前路径。
- use_e2e_profiler表示是否开启E2E profiling功能,默认为False,代表仅开启CANN profiling功能,采集CANN层面的数据。

因NPU算子需要编译后才能执行,为保证数据的准确性,建议先运行10个step,在第十个step后再进行E2E profiling操作,并且一般只需要profiling1个或者2个step即可。
if step == 11: with torch_npu.npu.profile(profiler_result_path="./result",use_e2e_profiler=True): model_train() - 解析性能数据。
使用E2E profiling工具获得的结果为原始数据,需要解析查看。
- 切换至如图1路径,执行脚本,msprof工具路径请根据实际安装路径修改,完整参数请参见《性能分析工具使用指南》中“性能数据解析与导出”章节。
/usr/local/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/bin/msprof --export=on --output=./
--export为导出timeline和summary性能数据开关。--output为性能数据文件导出目录。
- 运行完成后,在原始数据路径下生成timeline目录,timeline路径下为解析得到的json格式的性能数据文件。
- 在Chrome浏览器中输入“chrome://tracing”地址,将json文件拖到空白处打开,通过键盘上的快捷键(w:放大, s:缩小, a:左移, d:右移)进行查看。

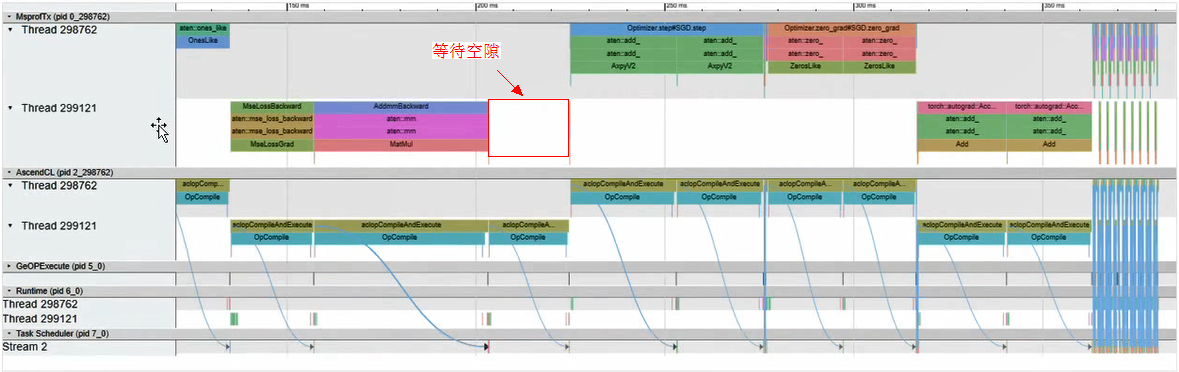
该示例分为4个层次,由上到下,第一层MsprofTx为PyTorch框架数据,第二层AscendCL为AscendCL层面数据,第三层Task Scheduler为device上数据,第四层为AI CPU上数据。
- 切换至如图1路径,执行脚本,msprof工具路径请根据实际安装路径修改,完整参数请参见《性能分析工具使用指南》中“性能数据解析与导出”章节。
- (可选)配置E2E高级设置。
E2E profiling工具默认配置获取PyTorch和CANN所有层面数据。获取数据过程会影响性能,若获取数据过多,会导致性能数据不具备参考价值。因此,E2E profiling工具提供了如下可配置选项,用于精细化控制获取部分层面数据。
with torch_npu.npu.profile(profiler_result_path="./results", use_e2e_profiler=True, \ config=torch_npu.npu.profileConfig(ACL_PROF_ACL_API=True, \ ACL_PROF_TASK_TIME=True, ACL_PROF_AICORE_METRICS=True, \ ACL_PROF_AICPU=True, ACL_PROF_L2CACHE=False, \ ACL_PROF_HCCL_TRACE=True, ACL_PROF_TRAINING_TRACE=False, \ TORCH_CALL_STACK=False, \ aiCoreMetricsType=1)):表1 配置参数说明 参数名称
参数含义
参数说明
ACL_PROF_ACL_API
采集AscendCL接口的性能数据。
默认True。
ACL_PROF_TASK_TIME
采集AI CORE算子的执行时间。
默认True。
ACL_PROF_AICORE_METRICS
采集AI CORE性能指标数据。
默认为True。当值为True时,aicore_metrics入参处配置的性能指标采集项才有效。
ACL_PROF_AICPU
采集AI CPU任务的开始、结束轨迹数据。
默认为True。
ACL_PROF_L2CACHE
采集L2 Cache数据,该数据会导致prof结果膨胀。
默认False。
ACL_PROF_HCCL_TRACE
采集HCCL数据。
默认为True。
ACL_PROF_TRAINING_TRACE
表示迭代轨迹数据,记录模型正向和反向等步骤。
默认为False。
TORCH_CALL_STACK
表示PyTorch框架层的算子调用栈信息。
默认为False。
aiCoreMetricsType
见表2。
默认为1,详情见表2。
表2 aiCoreMetricsType取值和定义说明表 参数取值
相关参数
参数定义
采集项
0
ACL_AICORE_ARITHMETIC_UTILIZATION
各种计算类指标占比统计。
mac_fp16_ratio、mac_int8_ratio、vec_fp32_ratio、vec_fp16_ratio、vec_int32_ratio、vec_misc_ratio。
1
ACL_AICORE_PIPE_UTILIZATION
计算单元和搬运单元耗时占比。
vec_ratio、mac_ratio、scalar_ratio、mte1_ratio、mte2_ratio、mte3_ratio、icache_miss_rate。
2
ACL_AICORE_MEMORY_BANDWIDTH
外部内存读写类指令占比。
ub_read_bw、ub_write_bw、l1_read_bw、l1_write_bw、l2_read_bw、l2_write_bw、main_mem_read_bw、main_mem_write_bw。
3
ACL_AICORE_L0B_AND_WIDTH
内部内存读写类指令占比。
scalar_ld_ratio、scalar_st_ratio、l0a_read_bw、l0a_write_bw、l0b_read_bw、l0b_write_bw、l0c_read_bw、l0c_write_bw。
4
ACL_AICORE_RESOURCE_CONFLICT_RATIO
流水线队列类指令占比。
vec_bankgroup_cflt_ratio、vec_bank_cflt_ratio、vec_resc_cflt_ratio、mte1_iq_full_ratio、mte2_iq_full_ratio、mte3_iq_full_ratio、cube_iq_full_ratio、vec_iq_full_ratio、iq_full_ratio。
5
ACL_AICORE_MEMORY_UB
内部内存读写指令占比。
ub_read_bw_vector、ub_write_bw_vector、ub_read_bw_scalar、ub_write_bw_scalar。
0x FF
ACL_AICORE_NONE
不采集。
无。


分析方法
- 主要分析流程。
- 找到“/{profiler_result_path}/timeline”目录下的msprof.json文件,Chrome浏览器中输入“chrome://tracing”地址,将json文件拖到空白处打开,可从该文件中找到耗时较长的接口和等待空隙。
- 对照算子信息表进行量化分析。
其中,op_statistic.csv文件主要统计同一算子在device上的执行次数、总耗时等数据。op_summary.csv文件主要统计算子执行时间,通过对op_summary.csv文件中的Task Duration字段进行排序,可找到耗时最大算子,除此之外,通过对Task Start Time进行排序,结合timeline数据可找到算子在脚本执行过程中的位置。
- 找到“/{profiler_result_path}/timeline”目录下的msprof.json文件,Chrome浏览器中输入“chrome://tracing”地址,将json文件拖到空白处打开,可从该文件中找到耗时较长的接口和等待空隙。
- 框架侧算子与device侧算子连线。这里选取一个样例讲解如下。
- 对一个模型进行训练,拿到Profiling数据并解析得到msprof.json、op_summary.csv和op_statistic.csv文件。
- 查看op_statistic.csv文件中算子耗时,发现TransData算子耗时排在第三位。结果如下。
- 分析msprof.json文件,发现TransData算子经常出现在AxpyWithSoftmaxAndDropOutDoMask算子两侧,由此可推断AxpyWithSoftmaxAndDropOutDoMask算子的输入不符合它需要的格式,因此会自动插入TransData算子进行转换。timeline示意如下。
- 在op_summary.csv文件中对Task Start Time进行排序,找到排序后的AxpyWithSoftmaxAndDropOutDoMask算子,发现其要求的输入格式为FRACTAL_NZ,但是上一算子输出的格式为FORMAT_ND,因此需要使用TransData算子对格式进行转换。算子信息如下。
- 继续在msprof.json文件中找到该算子并点击它,在底部的算子详细信息中点击“connect”找到下发算子,如下。
点击后下发算子如下:
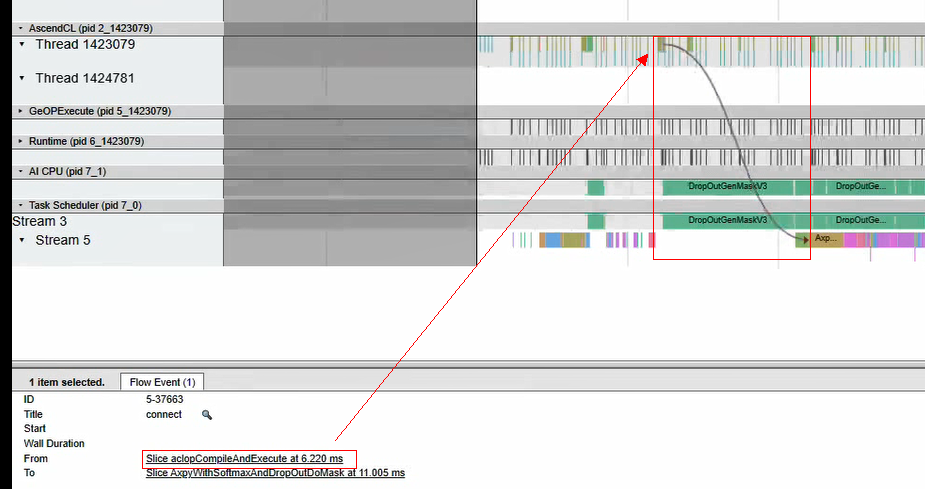
- 点击下发算子(From处),可以看到ACL下发算子的详细信息,如下。
点击下发算子详情页的“connect”,得到框架侧下发算子,如下。

- 点击该算子,可以看到该算子的详细信息。
通过看框架侧下发算子调用栈call_stack,可以找到瓶颈算子在代码中的位置,然后可进行针对性的优化。相关优化操作可参考格式转换优化。







采集数据说明
PyTorch性能数据采集生成的数据文件汇总如下。各数据文件详细文件介绍请参见《性能分析工具》。
timeline文件名 |
说明 |
|---|---|
msprof*.json |
timeline数据总表。对采集到的timeline性能数据按照迭代粒度进行性能展示。 |
thread_group_*.json |
AscendCL,GE,Runtime组件耗时数据。该文件内的各组件数据按照线程(Thread)粒度进行排列,方便查看各线程下各组件的耗时数据。当模型为动态Shape时自动采集并生成该文件。 |
task_time_*.json |
Task Scheduler任务调度信息。 |
acl_*.json |
AscendCL接口耗时数据。 |
runtime_api_*.json |
Runtime接口耗时数据。 |
task_queue.json |
msproftx数据,通过E2E profiling方式采集,需在PyTorch训练脚本内设置“use_e2e_profiler=True”。 |
timeline文件名 |
说明 |
|---|---|
msprof_tx.json |
msproftx timeline数据。对采集到的host msproftx timeline数据按线程进行拼接,并进行数据关联性展示。 |
msprof*.json |
timeline数据总表。对采集到的timeline性能数据按照迭代粒度进行性能展示。 |
summary文件名 |
说明 |
|---|---|
op_summary_*.csv |
AI Core和AI CPU算子信息。 |
op_statistic_*.csv |
AI Core和AI CPU算子调用次数及耗时,从算子类型维度找出耗时最大的算子类型。 |
runtime_api_*.csv |
每个runtime api的调用时长。 |
task_time_*.csv |
Task Scheduler的任务调度信息数据。 |
ge_op_execute_*.csv |
算子下发各阶段耗时数据。当模型为动态Shape时自动采集并生成该文件。 |
acl_*.csv |
AscendCL接口的耗时。 |
acl_statistic_*.csv |
AscendCL接口调用次数及耗时。 |
prof_rule_0.json |
调优建议。 |
summary文件名 |
说明 |
|---|---|
pytorch_operator_view.csv |
msproftx数据,通过E2E profiling方式采集,需在PyTorch训练脚本内设置“use_e2e_profiler=True”。 |
msprof_tx.csv |
msproftx summary数据。对采集到的host msproftx summary数据按线程进行拼接,并进行数据关联性展示。 |
