非连续转连续优化
原理
- PyTorch共享Storage机制。
PyTorch中的tensor对象由表示层和存储层(Storage)构成,表示层主要包含tensor的形状、步长、类型和是否连续等信息,存储层为连续内存的一维数组。大多数情况下,每个tensor都有独立的表示层和存储层,但通过对tensor进行View类操作后,原始tensor和转换后的tensor表示层信息不同,但实际共享同一个存储层。
- PyTorch中tensor存储与读取原则是行优先。
行优先是多维数组以一维展开的一种方式,举例如下:
>>>t = torch.arange(12).reshape(3,4) >>>t tensor([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>>t.stride() (4, 1) >>>t.is_contiguous() True这里定义了一个二维数组t,t的逻辑结构如下。
图1 逻辑结构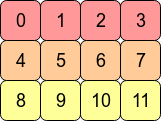 数组t在内存中实际以一维数组形式存储,可通过flatten查看。
数组t在内存中实际以一维数组形式存储,可通过flatten查看。>>> t.flatten() tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
其存储物理结构如下:
图2 一维展开
t.stride()表示在指定维度dim中从一个元素跳到下一个元素所需的步长,t有0和1两个dim。沿着dim0(即纵向),从一个元素跳到下一个元素(如从0到4)要经过1、2、3、4,四个元素;沿着dim1(即横向),从一个元素跳到下一个元素(如从1到2)只经过2,一个元素。因此t.stride()为(4, 1)。
- PyTorch中的非连续tensor。
tensor经过View非连续类(如transpose、permute等)操作后,转换后的tensor表示层信息不同但存储层相同。按照行优先展开时,存在数学上相邻的元素在内存上不再连续排布的情况。如对上述t进行transpose操作后结果如下。
>>> t1 = t.transpose(0, 1) >>> t1 tensor([[ 0, 4, 8], [ 1, 5, 9], [ 2, 6, 10], [ 3, 7, 11]]) >>> t1.stride() (1, 4) >>> t1.is_contiguous() False >>> t1.flatten() tensor([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11]) >>> t.data_ptr() == t1.data_ptr() Truet1的逻辑结构如下,通过data_ptr方法可知t和t1首元素地址相同,可以判断为共用Storage。
图3 t1逻辑结构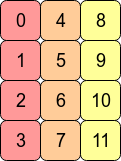
- 非连续转连续。
NPU采用SIMD指令架构,对访问内存有连续性要求,需要将非连续的tensor转为连续的tensor。PyTorch中由非连续转连续方法为contiguous,例如:
>>> t2 = t1.contiguous() >>> t2 tensor([[ 0, 4, 8], [ 1, 5, 9], [ 2, 6, 10], [ 3, 7, 11]]) >>> t2.data_ptr() == t1.data_ptr() False由以上可知,非连续转连续会重新开辟一块内存用来存储转换后的tensor,此过程存在性能开销。
问题定位
在模型或训练脚本中使用了View非连续类操作,如调用了transpose、narrow、select、permute、chunk、split等框架类算子,框架会调用format_contiguous函数对其进行校验,生成一个匹配且连续的tensor。
- 参见Profiling数据采集及分析在训练脚本中使能profiling。
- 通过查看Profiling数据,如发现在非连续转连续时耗时明显,可定位至对应算子,例如图4所示,format_contigousV2为转连续算子。

优化策略
- 使用计算类算子代替View类算子,view类算子指能够进行维度变换的算子,例如:view()、transpose()、permute()。
使用index_select代替torch.transpose(x, 1, 2).contiguous。
# 原始channel_shuffle操作 def channel_shuffle(x, groups): # type: (torch.Tensor, int) -> torch.Tensor batchsize, num_channels, height, width = x.data.size() channels_per_group = num_channels // groups # reshape x = x.view(batchsize, groups, channels_per_group, height, width) x = torch.transpose(x, 1, 2).contiguous() # flatten x = x.view(batchsize, -1, height, width) return x同等语义修改:
def channel_shuffle_index_select(x, groups=2): N, C, H, W = x.shape inp = C # channel_shuffle操作是对C维按一定规则的重排的工作,可以被表达为一次简单的重排 group_len = inp // groups index = torch.from_numpy(np.array(list(range(inp))).reshape(groups, group_len).transpose(1, 0).flatten()).long() x = x.index_select(1, index) return x - 如果存在对同一tensor的多次非连续操作,则可通过优先将其转连续以避免多次转换。
父主题: 算子性能优化
