IFMR数据量化算法
IFMR(Input Feature Map Reconstruction)算法在某个数据分布下,通过搜索的方式确定最佳量化方式。 该算法用于训练后量化场景,量化原理图如下所示:
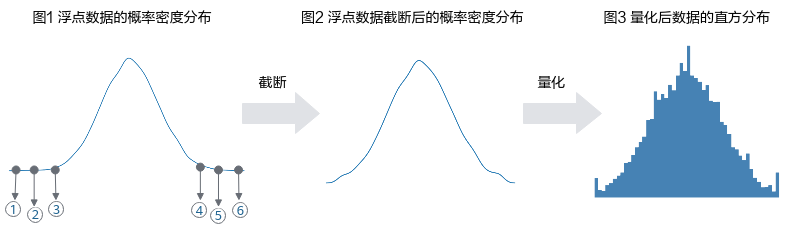
上图中序号[1,3]代表[clip_min_start, clip_min_end]、2代表clip_min、 [4,6]代表[clip_max_start, clip_max_end]、5代表clip_max。
该算法中量化过程分为两步,如图1所示,第一步,将浮点数截断到[clip_min, clip_max]范围,即图1中的[2,5]点 ;第二步,将浮点数据量化到int范围。通常情况下,数据分布处于边界附近的数值比较稀疏,均可做截断处理,以提高量化精度。
为获得最佳量化效果,可以不断改变截断范围[clip_min, clip_max],选择量化效果最好的一组范围作为最终的量化结果。IFMR算法中,clip_min和clip_max用来设置搜索范围和搜索步长,遍历查询得到最优的量化效果。量化配置中FMRQuantize(参数解释请参见表1)提供的参数则用来调整截断范围。
- clip_min(即图1中的序号2)的遍历取值范围为[clip_min_start, clip_min_end] (即图1中的[1,3]),步长为search_step。
- clip_max(即图1中的序号5)的遍历取值范围为[clip_max_start, clip_max_end] (即图1中的[4,6]),步长为search_step。
在数据降序序列中,根据min_percentile参数获得clip_min_init,从而得到clip_min_start、clip_min_end参数,其中:
- clip_min_start =clip_min_init*search_range_start
- clip_min_end= clip_min_init* search_range_end
在数据升序序列中,根据max_percentile参数获得clip_max_init,从而得到clip_max_start、clip_max_end参数,其中:
- clip_max_start =clip_max_init*search_range_start
- clip_max_end=clip_max_init* search_range_end
通常情况下,搜索范围[clip_min_start, clip_min_end]越大、搜索步长search_step越小,可能获得更高的量化精度,但量化耗时更多。
父主题: 训练后量化算法