模型执行
基本原理
开发应用时,如果涉及整网模型推理,则应用程序中必须包含模型执行的代码逻辑,关于模型执行的接口调用流程。请先参见pyACL接口调用流程了解整体流程,再查看本节中的流程说明。
本节描述的是整网模型执行的接口调用流程,对于算子模型加载与执行的详细说明请参见单算子调用。
接口调用流程

关键接口的说明如下:
- 调用acl.mdl.create_desc接口创建描述模型基本信息的数据类型。
- 调用acl.mdl.get_desc接口根据模型加载中返回的模型ID获取模型基本信息。
- 准备模型执行的输入、输出数据结构,具体流程请参见准备模型执行的输入/输出数据结构。
如果模型的输入涉及动态Batch、动态分辨率、动态AIPP、动态维度(ND格式)等特性,请参见模型动态推理、模型动态AIPP推理。
- 执行模型推理。
对于固定的多Batch场景,需要满足Batch数后,才能将输入数据发送给模型进行推理。不满足Batch数时,用户需根据自己的实际场景处理。
当前系统支持模型的同步推理和异步推理:
- 同步推理时调用acl.mdl.execute接口。
- 异步推理时调用acl.mdl.execute_async接口。
对于异步接口,还需调用acl.rt.synchronize_stream接口阻塞应用程序运行,直到指定Stream中的所有任务都完成。
异步推理的详细介绍,请参见模型异步推理。
- 获取模型推理的结果,用于后续处理。
对于同步推理,直接获取模型推理的输出数据即可。
对于异步推理,在实现Callback功能时,在回调函数内获取模型推理的结果,供后续使用。
- 释放内存。
- 释放相关数据类型的数据。
在模型推理结束后,需及时依次调用acl.destroy_data_buffer接口和acl.mdl.destroy_dataset接口释放描述模型输入的数据。如果存在多个输入、输出,需调用多次acl.destroy_data_buffer接口。
准备模型执行的输入/输出数据结构
pyACL提供了以下数据类型来描述模型、模型输入、模型输出以及存放数据的内存,在模型执行前,需要构造好这些数据类型,作为模型执行的输入:
- 使用aclmdlDesc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等)。
模型加载成功后,用户可根据模型的ID,调用acl.mdl.get_desc接口获取该模型的描述信息,进而从模型的描述信息中获取模型输入/输出的个数、内存大小、维度信息、Format、数据类型等信息,可参见aclmdlDesc类型下的操作接口。
- 使用aclmdlDataset类型的数据描述模型的输入/输出数据,模型可能存在多个输入、多个输出。
调用aclmdlDataset类型下的操作接口添加aclDataBuffer类型的数据、获取aclDataBuffer的个数等。
- 每个输入/输出的内存地址、内存大小用aclDataBuffer类型的数据来描述。
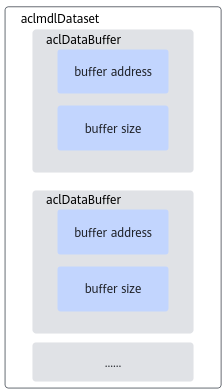
了解相关的数据类型后,可以使用这些数据类型的操作接口准备模型的输入、输出数据结构,如下图所示。

关键说明如下:
- 模型存在多个输入、输出时,用户可调用acl.mdl.get_num_inputs、acl.mdl.get_num_outputs接口获取输入、输出的个数。
- 模型每个输入、输出所需的内存大小,用户可调用acl.mdl.get_input_size_by_index、acl.mdl.get_output_size_by_index接口获取。
如果模型的输入涉及动态Batch、动态分辨率、动态维度(ND格式)等特性,输入Tensor数据的Shape支持多种档位,在模型执行前才能确定,因此该输入所需的内存大小建议用户调用acl.mdl.get_input_size_by_index接口获取,该接口获取的是最大档位的内存,确保内存够用。
- 模型存在多个输入、输出时,用户在向aclmdlDataset中添加aclDataBuffer时,为避免顺序出错,可以先调用acl.mdl.get_input_name_by_index、acl.mdl.get_output_name_by_index接口获取输入、输出的名称,根据输入、输出名称所对应的index的顺序添加。
示例代码(准备模型的输入和输出数据结构)
您可以从样例介绍中获取完整样例代码。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝运行,仅供参考。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 初始化变量。 ACL_MEM_MALLOC_HUGE_FIRST = 0 # 1.根据模型的ID,获取该模型的描述信息。 # self.model_desc为aclmdlDesc类型。 self.model_desc = acl.mdl.create_desc() ret = acl.mdl.get_desc(self.model_desc, self.model_id) # 2.准备模型推理的输入数据集。 # 创建aclmdlDataset类型的数据,描述模型推理的输入。 self.load_input_dataset = acl.mdl.create_dataset() # 获取模型输入的数量。 input_size = acl.mdl.get_num_inputs(self.model_desc) self.input_data = [] # 循环为每个输入申请内存,并将每个输入添加到aclmdlDataset类型的数据中。 for i in range(input_size): buffer_size = acl.mdl.get_input_size_by_index(self.model_desc, i) # 申请输入内存。 buffer, ret = acl.rt.malloc(buffer_size, ACL_MEM_MALLOC_HUGE_FIRST) data = acl.create_data_buffer(buffer, buffer_size) _, ret = acl.mdl.add_dataset_buffer(self.load_input_dataset, data) self.input_data.append({"buffer": buffer, "size": buffer_size}) # 3.准备模型推理的输出数据集。 # 创建aclmdlDataset类型的数据,描述模型推理的输出。 self.load_output_dataset = acl.mdl.create_dataset() # 获取模型输出的数量。 output_size = acl.mdl.get_num_outputs(self.model_desc) self.output_data = [] # 循环为每个输出申请内存,并将每个输出添加到aclmdlDataset类型的数据中。 for i in range(output_size): buffer_size = acl.mdl.get_output_size_by_index(self.model_desc, i) # 申请输出内存。 buffer, ret = acl.rt.malloc(buffer_size, ACL_MEM_MALLOC_HUGE_FIRST) data = acl.create_data_buffer(buffer, buffer_size) _, ret = acl.mdl.add_dataset_buffer(self.load_output_dataset, data) self.output_data.append({"buffer": buffer, "size": buffer_size}) # ...... |
示例代码(执行模型)
您可以从样例介绍中获取完整样例代码。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝运行,仅供参考。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
ACL_MEMCPY_HOST_TO_DEVICE = 1 ACL_MEMCPY_DEVICE_TO_HOST = 2 NPY_BYTE = 1 images_list = ["./data/dog1_1024_683.jpg", "./data/dog2_1024_683.jpg"] for image in images_list: # 1.自定义函数transfer_pic,使用Python库读取图片文件,并对图片进行缩放、剪裁等操作。 # transfer_pic函数的实现请参考样例中源代码。 img = transfer_pic(image) # 2.准备模型推理的输入数据,运行模式默认为运行模式为ACL_HOST,当前实例代码中模型只有一个输入。 bytes_data = img.tobytes() np_ptr = acl.util.bytes_to_ptr(bytes_data) # 将图片数据从Host传输到Device。 ret = acl.rt.memcpy(self.input_data[0]["buffer"], self.input_data[0]["size"], np_ptr, self.input_data[0]["size"], ACL_MEMCPY_HOST_TO_DEVICE) # 3.执行模型推理。 # self.model_id表示模型ID,在模型加载成功后,会返回标识模型的ID。 ret = acl.mdl.execute(self.model_id, self.load_input_dataset, self.load_output_dataset) # ...... |
示例代码(处理推理结果:直接处理内存中的数据)
您可以从样例介绍中获取完整样例代码。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝运行,仅供参考。
以图片分类网络为例,模型执行结束后,需处理每一张图片的模型推理结果,直接输出top5置信度的类别编号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 处理模型推理的输出数据,输出top5置信度的类别编号。 inference_result = [] for i, item in enumerate(self.output_data): buffer_host, ret = acl.rt.malloc_host(self.output_data[i]["size"]) # 将推理输出数据从Device传输到Host。 ret = acl.rt.memcpy(buffer_host, self.output_data[i]["size"], self.output_data[i]["buffer"], self.output_data[i]["size"], ACL_MEMCPY_DEVICE_TO_HOST) bytes_out = acl.util.ptr_to_bytes(buffer_host, self.output_data[i]["size"]) data = np.frombuffer(bytes_out, dtype=np.byte) inference_result.append(data) tuple_st = struct.unpack("1000f", bytearray(inference_result[0])) vals = np.array(tuple_st).flatten() top_k = vals.argsort()[-1:-6:-1] print("======== top5 inference results: =============") for j in top_k: print("[%d]: %f" % (j, vals[j])) # ...... |
示例代码(处理推理结果:调用单算子处理推理结果)
您可以从样例介绍中获取完整样例代码。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝运行,仅供参考。
以图片分类网络为例,模型执行结束后,需处理每一张图片的模型推理结果,直接输出最大置信度的类别编号。您可以从样例介绍中获取完整样例代码。
当前示例中,使用Cast算子(将推理结果的数据类型从float32转成float16)和ArgMaxD算子(从推理结果中查找最大置信度的类别标识)实现数据后处理。单算子调用的流程请参见接口调用流程。
- Cast算子被封装成pyACL接口,因此在使用时,将算子的输入输出Tensor描述、算子输入输出数据的内存等信息作为acl.op.cast的入参,直接调用acl.op.cast接口加载并执行算子。
- ArgMaxD算子没有被封装成pyACL接口,因此在使用时,必须自行构造算子描述信息(输入输出Tensor描述、算子属性等)、申请存放算子输入输出数据的内存、明确算子类型名称、调用acl.op.execute_v2接口加载并执行算子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
ACL_MEMCPY_DEVICE_TO_HOST = 2 # 提前将Cast和ArgMaxD两个单算子的定义文件*.json编译成适配昇腾AI处理器的离线模型(*.om文件),用于验证单算子的运行。 # 设置单算子模型文件所在的目录,加载单算子模型。 ret = acl.op.set_model_dir("./op_models") # ...... # 以下步骤需针对每一张图片的模型推理结果进行处理。 # 1.在数据后处理前,先获取模型推理的输出,dataset_ptr表示模型推理的输出。 self.input_buffer = acl.mdl.get_dataset_buffer(dataset_ptr, 0) # 2.自定义函数_forward_op_cast,构造Cast算子的输入输出Tensor描述、申请存放算子输出数据的内存dev_buffer_cast、调用acl.op.cast接口加载并执行算子。 self._forward_op_cast() # 3.自定义函数_forward_op_arg_max_d,构造ArgMaxD算子的输入输出Tensor、输入输出Tensor描述、算子属性、申请存放算子输出数据的内存dev_buffer_arg_max_d、调用acl.op.execute_v2接口加载并执行算子。 self._forward_op_arg_max_d() # 4.将ArgMaxD算子的输出数据回传到Host。 # 4.1 根据ArgMaxD算子输出数据的大小,申请Host上的内存。 host_buffer, ret = acl.rt.malloc_host(self.tensor_size_arg_max_d) # 4.2 将ArgMaxD算子的输出数据从Device复制到Host。 ret = acl.rt.memcpy(host_buffer, self.tensor_size_arg_max_d, self.dev_buffer_arg_max_d, self.tensor_size_arg_max_d, ACL_MEMCPY_DEVICE_TO_HOST) # 4.3 在终端窗口显示最大置信度的类别编号。 bytes_out = acl.util.ptr_to_bytes(buffer_host, self.output_shape) data = np.frombuffer(bytes_out, dtype=np.int32).reshape((self.output_shape,)) print("[SingleOP][ArgMaxOp] label of classification result is:{}" .format(data[0])) # 5.释放资源。 # 5.1 释放Host的内存。 ret = acl.rt.free_host(host_buffer) # 5.2 释放Device上存放算子输出数据的内存。 ret = acl.rt.free(self.dev_buffer_cast) ret = acl.rt.free(self.dev_buffer_arg_max_d) # 5.3 释放aclDataBuffer类型数据(用于描述算子输出数据)。 ret = acl.destroy_data_buffer(self.output_buffer_cast) ret = acl.destroy_data_buffer(self.output_buffer_arg_max_d) # ...... |
示例代码(释放模型的输入、输出资源)
您可以从样例介绍中获取完整样例代码。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝运行,仅供参考。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 释放模型推理的输入、输出资源。 # 释放输入资源,包括数据结构和内存。 while self.input_data: item = self.input_data.pop() ret = acl.rt.free(item["buffer"]) input_number = acl.mdl.get_dataset_num_buffers(self.load_input_dataset) for i in range(input_number): data_buf = acl.mdl.get_dataset_buffer(self.load_input_dataset, i) if data_buf: ret = acl.destroy_data_buffer(data_buf) ret = acl.mdl.destroy_dataset(self.load_input_dataset) # 释放输出资源,包括数据结构和内存。 while self.output_data: item = self.output_data.pop() ret = acl.rt.free(item["buffer"]) output_number = acl.mdl.get_dataset_num_buffers(self.load_output_dataset) for i in range(output_number): data_buf = acl.mdl.get_dataset_buffer(self.load_output_dataset, i) if data_buf: ret = acl.destroy_data_buffer(data_buf) ret = acl.mdl.destroy_dataset(self.load_output_dataset) |
