样例介绍
获取样例
单击Gitee,进入Ascend samples开源仓,详细参见README中的“版本说明”下载配套版本的sample包,从“python/level1_single_api/1_acl/4_blas/acl_operator_add”目录下获取acl_operator_add样例。
功能描述
此样例实现了对自定义算子的功能验证,通过将自定义算子转换为单算子离线模型文件,然后通过ACL加载单算子模型文件进行运行。
该实现矩阵-矩阵相加的运算示例为:C = A + B,其中A、B、C都是8*16的矩阵,类型为int32,矩阵加的结果是一个8 * 16的矩阵。
主要接口
功能 |
对应ACL模块 |
ACL 接口函数 |
功能说明 |
|---|---|---|---|
资源初始化 |
初始化 |
acl.init |
初始化ACL配置。 |
Device管理 |
acl.rt.set_device |
指定用于运算的Device。 |
|
Context管理 |
acl.rt.create_context |
创建Context。 |
|
Stream管理 |
acl.rt.create_stream |
创建Stream。 |
|
算子加载与执行 |
acl.op.set_model_dir |
加载模型文件的目录。 |
|
数据后处理 |
算子加载与执行 |
acl.op.create_attr |
创建aclopAttr类型的数据。 |
-- |
acl.create_tensor_desc |
创建aclTensorDesc类型的数。 |
|
-- |
acl.get_tensor_desc_size |
获取Tensor描述占用的空间大小。 |
|
-- |
acl.create_data_buffer |
创建aclDataBuffer类型的数据。 |
|
数据交互 |
内存管理 |
acl.rt.memcpy |
数据传输,Host->Device或Device->Host。 |
内存管理 |
acl.rt.malloc |
申请Device上的内存。 |
|
内存管理 |
acl.rt.malloc_host |
申请Host上的内存。 |
|
单算子推理 |
算子加载与执行 |
acl.op.execute |
异步加载并执行指定的算子。 |
公共模块 |
-- |
acl.util.ptr_to_numpy |
通过指针地址获取numpy.ndarray对象。 |
-- |
acl.util.numpy_to_ptr |
获取numpy.ndarray对象的内存数据的指针地址。 |
|
资源释放 |
内存管理 |
acl.rt.free |
释放Device上的内存。 |
内存管理 |
acl.rt.free_host |
释放Host上的内存。 |
|
Stream管理 |
acl.rt.destroy_stream |
销毁Stream。 |
|
Context管理 |
acl.rt.destroy_context |
销毁Context。 |
|
Device管理 |
acl.rt.reset_device |
复位当前运算的Device,回收Device上的资源。 |
|
去初始化 |
acl.finalize |
实现ACL去初始化。 |
单算子矩阵相加流程图流程图
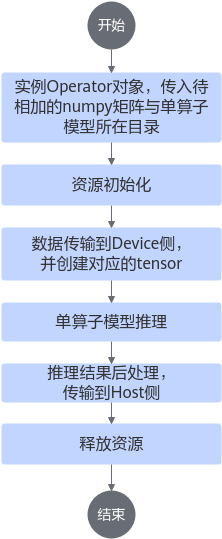
目录结构
如下为模型文件转换后的示例目录结构,“op_models”文件夹是转换后生成的。
acl_operator_add
├──src
│ ├── acl_execute_add.py //运行文件。
│ └── constant.py //常量定义。
└── test_data
├── config
│ ├── acl.json //系统初始化的配置文件。
│ └── add_op.json //矩阵相加算子的描述信息。
└── op_models
└── 0_Add_3_2_8_16_3_2_8_16_3_2_8_16.om //矩阵相加算子的模型文件。
