double buffer
执行于AI Core上的指令队列主要包括如下几类,即Vector指令队列(V)、Matrix指令队列(M)和存储移动指令队列(MTE2、MTE3)。不同指令队列间的相互独立性和可并行执行特性,是double buffer优化机制的基石。
如图1所示,考虑一个完整的数据搬运和计算过程,MTE2将数据从Global Memory搬运到Unified Buffer,Vector完成计算后将结果写回Unified Buffer,最后由MTE3将计算结果搬回Global Memory。
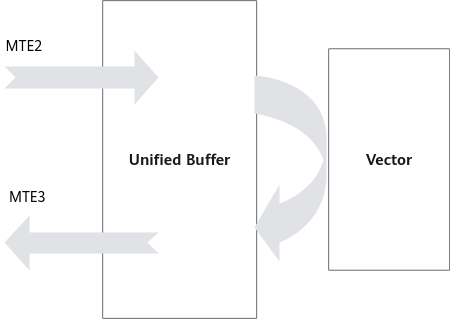
在此过程中,数据搬运与Vector计算串行执行,Vector计算单元无可避免存在资源闲置问题。举例而言,若MTE2、Vector、MTE3三阶段分别耗时t,则Vector的时间利用率仅为1/3,等待时间过长,Vector利用率严重不足。
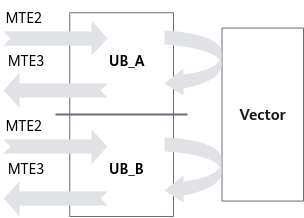
为减少Vector等待时间,double buffer机制将Unified Buffer一分为二,即UB_A、UB_B。如图2所示,当Vector对UB_A中数据进行读取和计算时,MTE2可将下一份数据搬入UB_B中;而当Vector切换到计算UB_B时,MTE3将UB_A的计算结果搬出,而MTE2则继续将下一份数据搬入UB_A中。由此,数据的进出搬运和Vector计算实现并行执行,Vector闲置问题得以有效缓解。
总体来说,double buffer是基于MTE指令队列与Vector指令队列的独立性和可并行性,通过将数据搬运与Vector计算并行执行以隐藏数据搬运时间并降低Vector指令的等待时间,最终提高Vector单元的利用效率,用户可以通过在for_range中设置参数thread_num来实现数据并行,简单代码示例如下:
with tik_instance.for_range(0, 10, thread_num=2) as i:
需要注意:
多数情况下,采用double buffer能有效提升Vector的时间利用率,缩减算子执行时间。然而,double buffer机制缓解Vector闲置问题并不代表它总能带来整体的性能提升。例如:
- 当数据搬运时间较短,而Vector计算时间显著较长时,由于数据搬运在整个计算过程中的时间占比较低,double buffer机制带来的性能收益会偏小。
- 又如,当原始数据较小且Vector可一次性完成所有计算时,强行使用double buffer会降低Vector计算资源的利用率,最终效果可能适得其反。
因此,double buffer的性能收益需综合考虑Vector算力、数据量大小、搬运与计算时间占比等多种因素。

一个for循环内不能同时开启多核和double buffer。如果想同时开启多核和double buffer,采用多个循环方式。
