分迭代保存功能使用
此功能适用于两个场景:
- 分迭代溢出检测:用户需要dump指定迭代或者多个迭代的数据或者检测溢出。
- 分迭代dump数据:用户需要dump某个特定API的数据或检测溢出检测。
分迭代溢出检测
- 添加分迭代保存代码。
debugger = PrecisionDebugger(dump_path="./dump_path", hook_name="overflow_check", step=list(range(10, 20)), enable_dataloader=True) debugger.configure_hook(overflow_nums=-1)
step参数配置为list(range(10,20)),即让工具检测训练第10到19个迭代中的所有溢出。
- 执行命令启动训练。
- NPU训练:
python ddp_basic_main.py 8
8表示训练所用卡数。
- GPU训练:
python ddp_basic_main.py 8
需注释掉NPU相关代码,进行训练。
每一个step的溢出会分别保存在单独的文件夹中,如下图所示。
图1 保存结果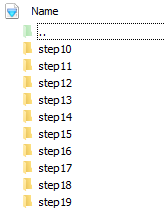
- NPU训练:
分迭代dump数据
- 添加分API保存代码,以在第0和第2个迭代捕获resnet中的relu为例。
debugger = PrecisionDebugger(dump_path="./", hook_name="dump", step=[0,2], enable_dataloader=True) debugger.configure_hook(mode="API_list", API_list=["relu"])
dump结果分为step0和step2。
图2 保存结果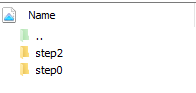

启用enable_dataloader在个别特殊场景可能会失效,导致工具只能捕获到部分rank的数据,这种场景用户需要在训练工程中添加PrecisionDebugger.start(), PrecisionDebugger.stop()和PrecisionDebugger.step()来手动启停开关以及更新迭代。在本例中,dataloader不启用的场景下,step放在训练迭代最后。
如下所示,如果有多个start和stop的情况中,step放在最后一个stop后。
def _run_epoch(self, epoch): for i, (source, targets) in enumerate(self.train_loader): debugger.start() source = source.to(self.GPU_id) targets = targets/to(self.GPU_id).long() self._run_batch(source, targets) debugger.stop() debugger.step()
父主题: 使用示例
