手工量化
功能介绍
量化是指对模型的参数和数据进行低比特处理,让最终生成的网络模型更加轻量化,从而达到节省网络模型存储空间、降低传输时延、提高计算效率达到性能提升与优化的目标。
用户可通过自己的框架和工具完成量化,并将这些量化参数(scaled、scalew、offsetd)在模型构建时注入到模型中。

- 当前仅Conv2D/DepthwiseConv2D/FullyConnection算子支持量化。
- 网络中Conv2D/DepthwiseConv2D/FullyConnection算子输入数据的Channel维度小于等于16时,由于Padding补齐,INT8量化无性能受益。因此量化要求Conv2D/DepthwiseConv2D/FullyConnection算子输入数据的Channel维度大于16,否则无法进行量化。
以Conv2D算子进行INT8量化为例,通过在Conv2D算子前插入AscendQuant量化算子,在Conv2D算子后插入AscendDequant反量化算子实现模型量化,如图1所示。
AscendQuant量化算子的作用是将float类型的数据转换为int8类型,即:dataint8=round[(datafloat*scale)+offset],其中scale=1/scaled,offset=offsetd。此处的round算法类似于C语言rint取整模式中的FE_TONEAREST模式。
AscendDequant反量化算子的作用是将int32类型的数据转换为float16类型,即:datafloat=dataint32*deq_scale,其中deq_scale=scaled*scalew。
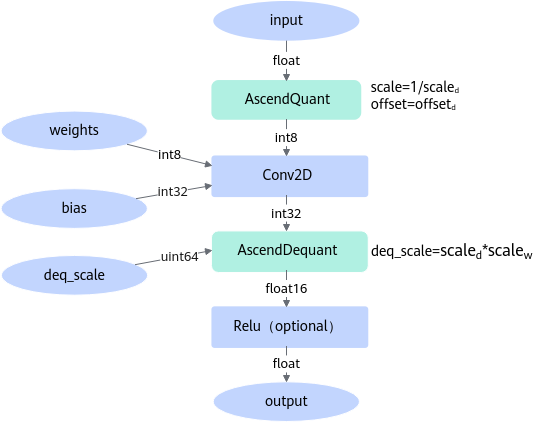
在Conv2D算子前插入AscendQuant算子
AscendQuant算子原型定义:
1 2 3 4 5 6 7 8 |
REG_OP(AscendQuant) .INPUT(x, TensorType({DT_FLOAT16, DT_FLOAT32})) .OUTPUT(y, TensorType({DT_INT8, DT_INT4})) .REQUIRED_ATTR(scale, Float) .REQUIRED_ATTR(offset, Float) .ATTR(sqrt_mode, Bool, false) .ATTR(round_mode, String, "Round") .OP_END_FACTORY_REG(AscendQuant) |
可以看到AscendQuant算子有1个输入x,两个必选属性scale和offset,两个可选属性sqrt_mode和round_mode,参数含义如下:
- x:指定AscendQuant算子输入,Tensor类型,支持的数据类型为float16和float32。
- scale:指定量化系数scale=1/scaled,支持float32和float16数据类型,建议在float16数据类型表达范围内,如果超出了float16表达范围,请配置sqrt_mode为True。
- offset:指定量化偏移量offset=1/offsetd,支持float32和float16数据类型。
- sqrt_mode:是否对scale进行开平方处理,取值为False和True,建议保持默认False。如果scale超出了float16表达范围,为了不损失精度,请配置sqrt_mode为True,系统会对scale做开平方处理。
- round_mode:float类型到int类型的转换方式,默认为Round,支持配置为:Round, Floor, Ceiling, Truncate。
根据AscendQuant算子原型定义创建AscendQuant算子实例:
1 2 3 4 |
auto quant = op::AscendQuant("quant") .set_input_x(data) .set_attr_scale(1.00049043) //指定量化系数 .set_attr_offset(-128.0); //指定偏移量 |
Conv2D算子
Conv2D算子的输入为AscendQuant,并设置输出type为int32。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// const op: conv2d weight auto weight_shape = ge::Shape({ 5,17,1,1 }); TensorDesc desc_weight_1(weight_shape, FORMAT_NCHW, DT_INT8); Tensor weight_tensor(desc_weight_1); uint32_t weight_1_len = weight_shape.GetShapeSize(); bool res = GetConstTensorFromBin(PATH+"const_0.bin", weight_tensor, weight_1_len); if(!res) { std::cout << "GetConstTensorFromBin Failed!" << std::endl; return -1; } auto conv_weight = op::Const("const_0") .set_attr_value(weight_tensor); // const op: conv2d bias auto bias_shape = ge::Shape({ 5 }); TensorDesc desc_bias(bias_shape, FORMAT_NCHW, DT_INT32); Tensor bias_tensor(desc_bias); uint32_t bias_len = bias_shape.GetShapeSize() * sizeof(int32_t); res = GetConstTensorFromBin(PATH + "const_1.bin", bias_tensor, bias_len); if(!res) { std::cout << "GetConstTensorFromBin Failed!" << std::endl; return -1; } auto conv_bias = op::Const("const_1") .set_attr_value(bias_tensor); // conv2d op auto conv2d = op::Conv2D("Conv2d") .set_input_x(quant) //AscendQuant作为Conv2D算子的输入 .set_input_filter(conv_weight) .set_input_bias(conv_bias) .set_attr_strides({ 1, 1, 1, 1 }) .set_attr_pads({ 0, 0, 0, 0 }) .set_attr_dilations({ 1, 1, 1, 1 }); TensorDesc conv2d_input_desc_x(ge::Shape(), FORMAT_NCHW, DT_INT8); //量化后,输入x的type为INT8 TensorDesc conv2d_input_desc_filter(ge::Shape(), FORMAT_NCHW, DT_INT8); TensorDesc conv2d_input_desc_bias(ge::Shape(), FORMAT_NCHW, DT_INT32); TensorDesc conv2d_output_desc_y(ge::Shape(), FORMAT_NCHW, DT_INT32); conv2d.update_input_desc_x(conv2d_input_desc_x); conv2d.update_input_desc_filter(conv2d_input_desc_filter); conv2d.update_input_desc_bias(conv2d_input_desc_bias); conv2d.update_output_desc_y(conv2d_output_desc_y); |
在Conv2D算子后插入AscendDequant算子
AscendDequant算子原型定义:
1 2 3 4 5 6 7 8 |
REG_OP(AscendDequant) .INPUT(x, TensorType({DT_INT32})) .INPUT(deq_scale, TensorType({DT_FLOAT16, DT_UINT64})) .OUTPUT(y, TensorType({DT_FLOAT16, DT_FLOAT})) .ATTR(sqrt_mode, Bool, false) .ATTR(relu_flag, Bool, false) .ATTR(dtype, Int, false, DT_FLOAT) .OP_END_FACTORY_REG(AscendDequant) |
可以看到AscendDequant算子有2个输入x和deq_scale,两个可选属性sqrt_mode和relu_flag,参数含义如下:
- x:指定AscendDequant算子输入,Tensor类型,支持的数据类型为int32。
- deq_scale:指定反量化系数deq_scale=scaled*scalew,Tensor类型,支持的数据类型为uint64。shape可以为1,或者和Conv2D输出数据的Channel维度保持一致。
要求用户把scaled和scalew相乘得到的float32数据类型转换为uint64类型,并填入到deq_scale的低32位中,高32位要求全部为0。
1 2 3 4 5 6 7
import numpy as np def trans_float32_scale_deq_to_uint64(scale_deq): float32_scale_deq = np.array(scale_deq, np.float32) uint32_scale_deq = np.frombuffer(float32_scale_deq, np.uint32) uint64_result = np.zeros(float32_scale_deq.shape, np.uint64) uint64_result |= np.uint64(uint32_scale_deq) return uint64_result
- sqrt_mode:是否对deq_scale进行开平方处理,取值为False和True,建议保持默认False。如果deq_scale超出了float16表达范围,为了不损失精度,请配置sqrt_mode为True,同时将deq_scale开平方后填入。
- relu_flag:是否执行Relu,取值为False和True,默认值为False。
根据AscendDequant算子原型定义创建AscendDequant算子实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//构造dequant_scale TensorDesc desc_dequant_shape(ge::Shape({ 5 }), FORMAT_NCHW, DT_UINT64); Tensor dequant_tensor(desc_dequant_shape); uint32_t dequant_scale_len = 5 * sizeof(uint64_t); res = GetConstTensorFromBin(PATH + "const_2.bin", dequant_tensor, dequant_scale_len); if(!res) { std::cout << "GetConstTensorFromBin Failed!" << std::endl; return -1; } auto dequant_scale = op::Const("dequant_scale") .set_attr_value(dequant_tensor); //定义AscendDequant算子 auto dequant = op::AscendDequant("dequant") .set_input_x(conv2d) //Conv2D作为AscendDequant算子的输入 .set_input_deq_scale(dequant_scale); |
将AscendDequant的输出作为其他算子的输入,或者作为整个graph的输出。
1 2 3 4 |
auto bias_add_1 = op::BiasAdd("bias_add_1") .set_input_x(dequant) .set_input_bias(bias_weight_1) .set_attr_data_format("NCHW"); |
