支持数据并行(Allreduce)
AllReduce是主流的数据并行架构,各个节点按照算法协同工作,适用于对训练算力要求高、设备规模大的场景。本节介绍如何将TensorFlow训练脚本在昇腾AI处理器上通过AllReduce架构进行分布式训练。
Allreduce实现原理
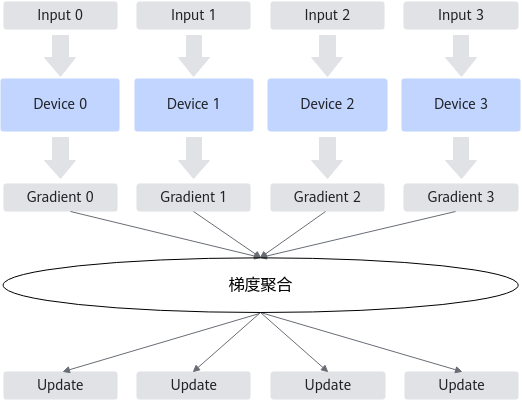
如果按照梯度聚合方式进行分类,数据并行的主流实现有PS-workers架构和AllReduce架构两种。在AllReduce架构中,每个参与训练的Device形成一个环,没有中心节点来聚合所有计算梯度。AllReduce算法将参与训练的Device放置在一个逻辑环路(logical ring)中。每个Device从上行的Device接收数据,并向下行的Device发送数据,可充分利用每个Device的上下行带宽。
AllReduce架构是为了解决了PS-workers架构无法线性扩展问题而提出的改良架构。各个节点按照算法协同工作,算法的目标是减少传输数据量,并充分利用硬件通信带宽。一般适合训练算力要求高、设备规模大的场景。AllReduce架构的实现原理如下图所示。
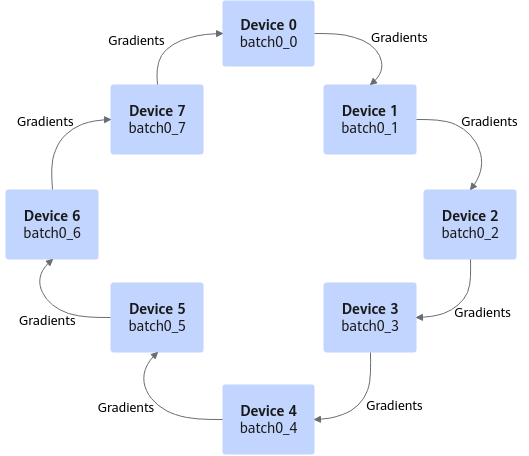
以Ring算法为例介绍allreduce模式(称为Ring-allreduce),如图2所示,在Ring-allreduce架构下,每个设备都是worker,并且形成一个环,不需要中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成一份mini-batch样本数据的前向计算、反向计算,得到梯度数据,然后使用Ring-allreduce算法完成梯度数据的同步。Ring-allreduce算法包括scatter-reduce和allgather两部分,梯度数据分多个步骤传递给环中的下一个worker,同时它也多次接收上一个worker的梯度数据。对于一个包含N个worker的环,每个worker需要从其它worker接收2*(N-1)次梯度数据(每次接收1/N的数据),并向其他节点发送2*(N-1)次梯度数据(每次发送1/N的数据)。
使用的接口
在TensorFlow中,一般使用tf.distribute.Strategy进行分布式训练,具体请参考https://www.tensorflow.org/guide/distributed_training。而昇腾AI处理器暂不支持上述分布式策略,TF Adapter提供了分布式接口npu_distributed_optimizer_wrapper,对传入的optimizer梯度函数添加NPU的allreduce操作,最终返回输入的优化器,从而支持单机多卡、多机多卡等组网形式下,各个Device之间计算梯度后执行梯度聚合操作。用户调用该函数后,在生成的训练图中,梯度计算和更新算子之间插入了allreduce算子节点。
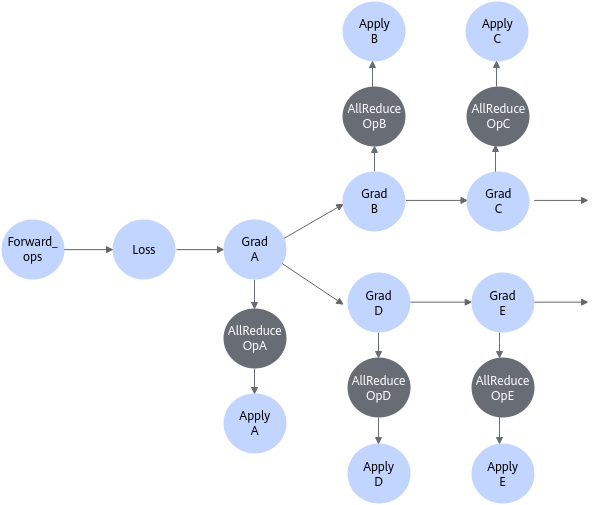
因此,对于原始TensorFlow训练脚本,需要经过修改后,才可在昇腾AI处理器上支持分布式训练。
数据集切分
分布式训练时,用户可以使用TensorFlow接口进行数据集切分。如果数据集切分时需要获取处理器资源信息,用户可以通过集合通信接口get_rank_size获取昇腾AI处理器数量,通过get_rank_id获取处理器id,例如:
1
|
dataset = dataset.shard(get_rank_size(),get_rank_id()) |
Estimator模式下脚本迁移
- TensorFlow会将策略对象传递到Estimator的Runconfig中,但是TF Adapter暂不支持这种方式,用户需要将相关代码删除。例如:
迁移前:
1 2 3 4 5 6
mirrored_strategy = tf.distribute.MirroredStrategy() config = tf.estimator.RunConfig( train_distribute=mirrored_strategy, eval_distribute=mirrored_strategy, session_config=session_config, save_checkpoints_secs=60*60*24)
迁移后:
1 2 3
config = tf.estimator.NPURunConfig( session_config=session_config, save_checkpoints_secs=60*60*24)
- 然后调用npu_distributed_optimizer_wrapper,对传入的optimizer梯度函数添加NPU的allreduce操作,最终返回输入的优化器,从而在昇腾AI处理器上实现分布式计算。具体方法为:
1 2 3 4 5 6 7 8 9 10 11 12
def cnn_model_fn(features,labels,mode): #搭建网络 xxx #计算loss xxx #Configure the TrainingOp(for TRAIN mode) if mode == tf.estimator.ModeKeys.TRAIN: optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001) # 使用SGD优化器 optimizer = npu_distributed_optimizer_wrapper(optimizer) # 使用NPU分布式计算,更新梯度 train_op=optimizer.minimize(loss=loss,global_step=tf.train.get_global_step()) # 最小化loss return tf.estimator.EstimatorSpec(mode=mode,loss=loss,train_op=train_op)

- NPUDistributedOptimizer分布式优化器在当前版本依然兼容。
- Estimator模式下,使用npu_distributed_optimizer_wrapper实现allreduce功能时,由于NPUEstimator中自动添加了NPUBroadcastGlobalVariablesHook,因此无需手写实现broadcast功能。
如果原始脚本使用TensorFlow接口计算梯度,例如grads = tf.gradients(loss, tvars),需要在计算完梯度之后,调用npu_allreduce接口对梯度进行allreduce。
迁移前:
1grads = tf.gradients(a + b, [a, b], stop_gradients=[a, b])
迁移后:
1grads = npu_allreduce(tf.gradients(a + b, [a, b], stop_gradients=[a, b]))
sess.run模式下脚本迁移
Estimator模式下,使用npu_distributed_optimizer_wrapper实现allreduce功能时,由于NPUEstimator中自动添加了NPUBroadcastGlobalVariablesHook,因此无需手写实现broadcast功能。但sess.run模式的训练脚本还需要用户手写实现broadcast功能。具体方法为:
- 在变量初始化之后,训练之前,通过集合通信接口broadcast进行变量广播:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
from npu_bridge.npu_init import * def broadcast_global_variables(root_rank, index): """Broadcasts all global variables from root rank to all other processes. Arguments: root_rank: rank of the process from which global variables will be broadcasted to all other processes. index: rank_id """ op_list = [] for var in tf.trainable_variables(): # the input and out tensor of HCOMBroadcast interface are list if "float" in var.dtype.name: inputs = [var] outputs=hccl_ops.broadcast(tensor=inputs,root_rank=root_rank) if outputs is not None: op_list.append(outputs[0].op) op_list.append(tf.assign(var, outputs[0])) return tf.group(op_list) ... bcast_op = broadcast_global_variables(root_rank, index) sess = tf.Session() ... sess.run(bcast_op)
此外,broadcast接口中有改图的操作,如果图无法修改(例如冻结了图或者使用tf.train.Supervisor创建session等),则在需要先取消图冻结:
1 2 3
with sv.managed_session() as sess: sess.graph._unsafe_unfinalize() # 取消冻结的Graph sess.run(bcast_op)
- 执行训练时,在使用梯度优化器计算完各Device数据后,直接调用npu_distributed_optimizer_wrapper进行梯度数据聚合:
1 2 3
from npu_bridge.npu_init import * optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001) # 使用SGD优化器 distributedOptimizer=npu_distributed_optimizer_wrapper(optimizer) # 使用NPU分布式计算,更新梯度
NPUDistributedOptimizer分布式优化器在当前版本依然兼容。
如果原始脚本使用TensorFlow接口计算梯度,例如grads = tf.gradients(loss, tvars),需要在计算完梯度之后,调用npu_allreduce接口对梯度进行allreduce:1grads = npu_allreduce(tf.gradients(a + b, [a, b], stop_gradients=[a, b]))
Keras模式下脚本迁移
如需在Keras模式下进行分布式训练,需要在Keras模型编译时修改optimizer,调用npu_distributed_optimizer_wrapper,对传入的optimizer梯度函数添加NPU的allreduce操作;并且在keras_model.fit的callbacks参数中增加NPUBroadcastGlobalVariablesCallback。
迁移前:
1 2 3 4 5 6 7 8 |
from npu_bridge.npu_init import * data = xxx labels = xxx opt = tf.keras.optimizers.Adam(learning_rate=0.001) keras_model.compile(optimizer=opt,loss='sparse_categorical_crossentropy') keras_model.fit(data, labels, epochs=10, batch_size=32) |
1 2 3 4 5 6 7 8 9 10 |
from npu_bridge.npu_init import * data = xxx labels = xxx opt = tf.keras.optimizers.Adam(learning_rate=0.001) opt = npu_distributed_optimizer_wrapper(opt) # allreduce keras_model.compile(optimizer=opt,loss='sparse_categorical_crossentropy') callbacks = [NPUBroadcastGlobalVariablesCallback(0)] # 变量进行广播 keras_model.fit(data, labels, epochs=10, batch_size=32, callbacks=callbacks) |
KerasDistributeOptimizer分布式优化器在当前版本依然兼容。
