支持数据并行(PS-Worker)
在推荐网络中,特征数据通过embedding table保存,数据量最大可能达到TB(Terabyte,太字节,是一种信息计量单位,1TB=1012字节)级别,无法在Device侧保存,因此需要通过PS-Worker方式将数据保存在Host侧的内存中。本节介绍如何将TensorFlow训练脚本在昇腾AI处理器上通过PS-Worker架构进行分布式训练。
PS-Worker实现原理
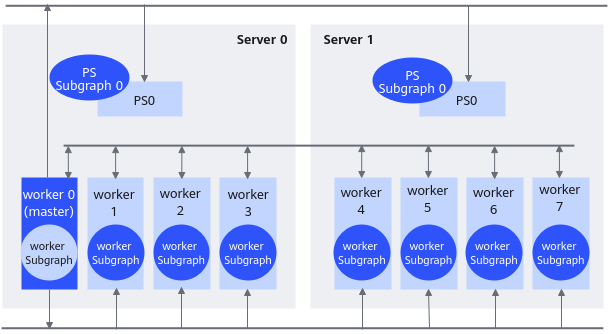
在PS-Worker架构中,集群中的节点被分为两类:参数服务器(parameter server)和工作服务器(worker)。其中参数服务器存放模型的参数,而工作服务器负责计算参数的梯度。在每个迭代过程,工作服务器从参数服务器中获得参数,然后将计算的梯度返回给参数服务器,参数服务器聚合从工作服务器传回的梯度,然后更新参数,并将新的参数广播给工作服务器。
下面介绍基于TensorFlow的Python API开发的训练脚本,如何在昇腾AI处理器通过PS-Worker架构进行分布式训练。
配置集群信息

- 在昇腾AI处理器通过PS-Worker架构进行分布式训练当前仅支持NPUEstimator模式。
- 当前仅支持一个worker进程对应在一个device上执行。
- PS-Worker集群场景下,建议用户选择高速率网卡。
PS-Worker架构下通过环境变量TF_CONFIG配置集群信息,TF_CONFIG里包括了两个部分:cluster和task。cluster提供了关于整个集群的信息,也就是集群中的工作服务器和参数服务器。task提供了关于当前任务的信息,详细使用说明请参考TensorFlow官网。
下面以两台Server,每台Server上各1个ps,8个worker为例进行说明。
- 设置TF_CONFIG信息。
1 2 3 4 5 6 7 8 9
os.environ['TF_CONFIG'] = json.dumps({ 'cluster': { #'chief':chief_hosts, # 可不设置 'worker': worker_hosts, 'ps': ps_hosts, 'evaluator':evaluator_hosts, # 不做评估的话,可不设置 }, 'task': {'type': job_name, 'index': task_index} })
- ps_hosts、worker_hosts信息可以采用Flags方式配置,配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
ps_hosts = FLAGS.ps_hosts.split(',') worker_hosts = FLAGS.worker_hosts.split(',') evaluator_hosts = FLAGS.evaluator_hosts.split(',') task_index = FLAGS.task_index job_name = FLAGS.job_name flags.DEFINE_string("ps_hosts", '192.168.1.100:2222,192.168.1.200:2222',) flags.DEFINE_string("worker_hosts", '192.168.1.100:2223, 192.168.1.100:2224, 192.168.1.100:2225, 192.168.1.100:2226,' '192.168.1.100:2227, 192.168.1.100:2228, 192.168.1.100:2229, 192.168.1.100:2230,' '192.168.1.200:2223, 192.168.1.200:2224, 192.168.1.200:2225, 192.168.1.200:2226,' '192.168.1.200:2227, 192.168.1.200:2228, 192.168.1.200:2229, 192.168.1.200:2230',) flags.DEFINE_string("evaluator_hosts", '192.168.1.100:2231',) flags.DEFINE_string("job_name", '', "One of 'ps', 'worker', 'evaluator', chief") flags.DEFINE_integer("task_index", 0, "Index of task within the job")
配置说明:
定义ParameterServerStrategy实例
为支持PS-Worker架构下的分布式训练,需要先定义tf.distribute.experimental.ParameterServerStrategy实例,该策略的更多细节请参考tf.distribute.experimental.ParameterServerStrategy。
1
|
strategy = tf.distribute.experimental.ParameterServerStrategy() |
训练和评估模型
我们需要在NPURunConfig中,通过distribute参数为NPUEstimator指明分布式策略,然后调用tf.estimator.train_and_evaluate训练和评估模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from npu_bridge.npu_init import * run_config = NPURunConfig( model_dir=flags_obj.model_dir, session_config=session_config, keep_checkpoint_max=5, save_summary_steps=1, log_step_count_steps=1, save_checkpoints_steps=100, enable_data_pre_proc=True, mix_compile_mode=True, # PS模式下只能是混合计算模式 iterations_per_loop=1, # 混合计算模式下一定为1。 precision_mode='allow_mix_precision', distribute=strategy) classifier = tf.estimator.NPUEstimator( model_fn=model_fn, model_dir='/tmp/multiworker', config=run_config) tf.estimator.train_and_evaluate( classifier, train_spec=tf.estimator.TrainSpec(input_fn=input_fn), eval_spec=tf.estimator.EvalSpec(input_fn=input_fn)) |
评估进程可以在Device执行,也可以在Host侧的CPU执行,但各有利弊,用户可以根据实际情况使用。
以1机8卡场景举例,一共需要1个ps进程和8个worker进程,其中8个worker进程在Device侧执行。
- 如果在训练的同时进行评估,要求evaluator和worker同时启动的进程数不能超出当前Server上最大的Device数(当前是8),由于Device已经被worker进程占用,因此需要通过Host侧的CPU进行评估,此时虽然能达到训练的同时进行评估的目的,但评估时无法利用昇腾AI处理器的性能优势,但可以与训练并行执行;建议使用此方式评估时,配置checkpoint的保存时长要大于评估的执行时长。
要实现Host侧的评估,需要直接使用TensorFlow的原生Estimator进行评估(不能转成NPUEstimator,否则需要Device资源,会因为已被训练占用而失败)。
- 如果在训练完成后再进行评估,此时用户只需要保证worker训练结束后再执行evaluator,这种情况下,训练和评估进程都可以在Device上执行,可以达到较优的性能。
脚本运行
若按python脚本内的ps_hosts,worker_hosts等信息运行(python脚本内未定义chief):
python resnet50_ps_strategy.py --job_name=ps --task_index=0 python resnet50_ps_strategy.py --job_name=ps --task_index=1 python resnet50_ps_strategy.py --job_name=worker --task_index=0 python resnet50_ps_strategy.py --job_name=worker --task_index=1 python resnet50_ps_strategy.py --job_name=worker --task_index=2 python resnet50_ps_strategy.py --job_name=worker --task_index=3 python resnet50_ps_strategy.py --job_name=worker --task_index=4 python resnet50_ps_strategy.py --job_name=worker --task_index=5 python resnet50_ps_strategy.py --job_name=worker --task_index=6 python resnet50_ps_strategy.py --job_name=worker --task_index=7
若需要重新定义ps_hosts,worker_hosts等信息(python脚本内未定义chief):
python resnet50_ps_strategy.py \
--ps_hosts=192.168.1.79:2222,192.168.1.80:2222 \
--worker_hosts=192.168.1.79:2223,192.168.1.79:2224,192.168.1.79:2225,192.168.1.79:2226,192.168.1.79:2227,192.168.1.79:2228,192.168.1.79:2229,192.168.1.79:2230,192.168.1.80:2223,192.168.1.80:2224,192.168.1.80:2225,192.168.1.80:2226,192.168.1.80:2227,192.168.1.80:2228,192.168.1.80:2229,192.168.1.80:2230 \
--job_name=ps \
--task_index=0
若需运行chief和evaluator,将job_name更改为定义的类型值即可,即:
python resnet50_ps_strategy.py --job_name=chief --task_index=0 python resnet50_ps_strategy.py --job_name=evaluator --task_index=0

