核函数
从SPMD模型可以得知,使用Ascend C进行编程时,我们编写一份算子实现代码,算子被调用时,将启动N个运行示例,在N个核上运行。本节将介绍算子实现的入口函数。
核函数(Kernel Function)是Ascend C算子设备侧实现的入口。在核函数中,需要为在一个核上执行的代码规定要进行的数据访问和计算操作,当核函数被调用时,多个核都执行相同的核函数代码,具有相同的参数,并行执行。
Ascend C允许用户使用核函数这种C/C++函数的语法扩展来管理设备端的运行代码,用户在核函数中进行算子类对象的创建和其成员函数的调用,由此实现该算子的所有功能。核函数是主机端和设备端连接的桥梁,本章将具体介绍核函数的用法。
核函数定义
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z);
以上是一个核函数声明的例子,编写核函数时需要遵循以下规则。
- 使用函数类型限定符
除了需要按照C/C++函数声明的方式定义核函数之外,还要为核函数加上额外的函数类型限定符,包含__global__和__aicore__。
使用__global__函数类型限定符来标识它是一个核函数,可以被<<<...>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端AI Core上执行:
__global__ __aicore__ void kernel_name(argument list);
编程中使用到的函数可以分为三类:核函数(device侧执行)、host侧执行函数、device侧执行函数(除核函数之外的)。三者的调用关系如下图所示:
- host侧执行函数可以调用同类的host执行函数,也就是通用C/C++编程中的函数调用;也可以通过<<<>>>调用核函数。
- device侧执行函数(除核函数之外的)可以调用同类的device执行函数。
- 核函数可以调用device侧执行函数(除核函数之外的)。
图1 核函数(device侧执行)、host侧执行函数、device侧执行函数(除核函数之外的)调用关系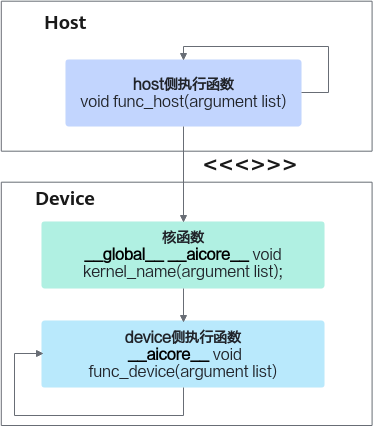
- 使用变量类型限定符
指针入参变量需要增加变量类型限定符__gm__。表明该指针变量指向Global Memory上某处内存地址。
- 其他规则或建议
- 规则:核函数必须具有void返回类型。
- 规则:仅支持入参为指针或C/C++内置数据类型(Primitive data types),如:half* s0、float* s1、int32_t c。
- 建议:为了统一表达,建议使用GM_ADDR宏来修饰入参,GM_ADDR宏定义如下:
#define GM_ADDR __gm__ uint8_t* __restrict__
使用GM_ADDR修饰入参的样例如下:
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
这里统一使用uint8_t类型的指针,在后续的使用中需要将其转化为实际的指针类型。
核函数调用
核函数的调用语句是C/C++函数调用语句的一种扩展。
常见的函数调用方式是如下的形式:
function_name(argument list);
核函数使用内核调用符<<<...>>>这种语法形式,来规定核函数的执行配置:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
内核调用符仅可在NPU侧编译时调用,CPU侧编译无法识别该符号。
- blockDim,规定了核函数将会在几个核上执行。每个执行该核函数的核会被分配一个逻辑ID,即block_idx,可以在核函数的实现中调用GetBlockIdx来获取block_idx;
- l2ctrl,保留参数,暂时设置为固定值nullptr,开发者无需关注;
- stream,类型为aclrtStream,stream是一个任务队列,应用程序通过stream来管理任务的并行。stream的定义和用法具体可参考《应用软件开发指南(C&C++)》“AscendCL API参考”章节。
考虑名为add_custom的核函数调用的例子,该函数实现两个矢量的相加:
// blockDim设置为8表示在8个核上调用了add_custom核函数,每个核都会独立且并行地执行该核函数,该核函数的参数列表为x,y,z。 add_custom<<<8, nullptr, stream>>>(x, y, z);
核函数的调用是异步的,核函数的调用结束后,控制权立刻返回给主机端,可以调用以下函数来强制主机端程序等待所有核函数执行完毕。
aclError aclrtSynchronizeStream(aclrtStream stream);
aclrtSynchronizeStream的具体用法参考《应用软件开发指南(C&C++)》“AscendCL API参考 > 同步等待 > aclrtSynchronizeStream”章节。
核函数示例
下面提供核函数实现和调用的样例代码片段,完整样例请参考Add算子示例。
// 实现核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 初始化算子类,算子类提供算子初始化和核心处理等方法
KernelAdd op;
// 初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作
op.Init(x, y, z);
// 核心处理函数,完成算子的数据搬运与计算等核心逻辑
op.Process();
}
// 调用核函数
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z)
{
add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
