快速上手端到端算子开发
本节以一个简单算子为例,带您体验从算子工程创建、代码编写、编译部署到运行验证的开发全流程,让您对算子开发工程有个宏观的认识,此处我们以输入是动态shape的Add算子实现为例,为了与内置Add算子区分,定义算子类型为AddCustom。
工程创建
CANN软件包中提供了工程创建工具msopgen,开发者可以输入算子原型定义文件生成Ascend C算子开发工程。
- 编写AddCustom算子的原型定义json文件。假设AddCustom算子的原型定义文件命名为add_custom.json,存储路径为: $HOME/sample,文件内容如下:
[ { "op": "AddCustom", "language":"cpp", "input_desc": [ { "name": "x", "param_type": "required", "format": [ "ND" ], "type": [ "fp16" ] }, { "name": "y", "param_type": "required", "format": [ "ND" ], "type": [ "fp16" ] } ], "output_desc": [ { "name": "z", "param_type": "required", "format": [ "ND" ], "type": [ "fp16" ] } ] } ] - 使用msopgen工具生成AddCustom算子的开发工程。
${INSTALL_DIR}/python/site-packages/bin/msopgen gen -i $HOME/sample/add_custom.json -c ai_core-<soc_version> -lan cpp -out $HOME/sample/AddCustom
- ${INSTALL_DIR}为CANN软件安装后文件存储路径,请根据实际环境进行替换。
- -i:算子原型定义文件add_custom.json所在路径。
- -c:ai_core-<soc_version>代表算子在AI Core上执行,<soc_version>为昇腾AI处理器的型号,可通过npu-smi info命令进行查询,基于同系列的AI处理器型号创建的算子工程,其基础功能能力通用。
- -lan: 参数cpp代表算子基于Ascend C编程框架,使用C++编程语言开发。
- 命令执行完后,会在$HOME/sample目录下生成算子工程目录AddCustom,工程中包含算子实现的模板文件,编译脚本等,如下所示:
AddCustom ├── build.sh // 编译入口脚本 ├── cmake │ ├── config.cmake │ ├── util // 算子工程编译所需脚本及公共编译文件存放目录 ├── CMakeLists.txt // 算子工程的CMakeLists.txt ├── CMakePresets.json // 编译配置项 ├── framework // 算子插件实现文件目录,单算子模型文件的生成不依赖算子适配插件,无需关注 ├── op_host // host侧实现文件 │ ├── add_custom_tiling.h // 算子tiling定义文件 │ ├── add_custom.cpp // 算子原型注册、shape推导、信息库、tiling实现等内容文件 │ ├── CMakeLists.txt ├── op_kernel // kernel侧实现文件 │ ├── CMakeLists.txt │ ├── add_custom.cpp // 算子核函数实现文件 ├── scripts // 自定义算子工程打包相关脚本所在目录

上述目录结构中的粗体文件为后续算子开发过程中需要修改的文件,其他文件无需修改。
算子核函数实现
在工程存储目录的“AddCustom/op_kernel/add_custom.cpp”文件中实现算子的核函数,完整的样例代码您可以在add_custom.cpp中查看,下面介绍关键实现代码。
算子核函数实现代码的内部调用关系示意图如下:
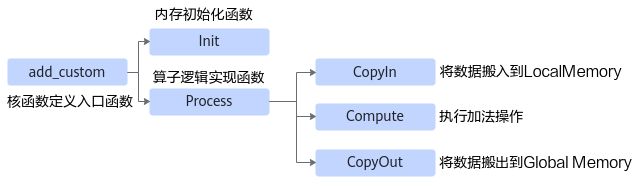
由此可见除了Init函数完成初始化外,Process中完成了对流水任务:“搬入、计算、搬出”的调用,开发者可以重点关注三个流水任务的实现。
- 首先,进行核函数的定义,并在核函数中调用算子类的Init和Process函数。
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling) { // 获取Host侧传入的Tiling参数 GET_TILING_DATA(tilingData, tiling); // 初始化算子类 KernelAdd op; // 算子类的初始化函数,完成内存初始化相关工作 op.Init(x, y, z, tilingData.totalLength, tilingData.tileNum); if (TILING_KEY_IS(1)) { // 完成算子实现的核心逻辑 op.Process(); } } - 定义KernelAdd算子类,其具体成员及成员函数实现如下。
class KernelAdd { public: __aicore__ inline KernelAdd() {} // 初始化函数,完成内存初始化相关操作 __aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileNum) { // 使用获取到的TilingData计算得到singleCoreSize(每个核上总计算数据大小)、tileNum(每个核上分块个数)、singleTileLength(每个分块大小)等变量 ASSERT(GetBlockNum() != 0 && "block dim can not be zero!"); this->blockLength = totalLength / GetBlockNum(); this->tileNum = tileNum; ASSERT(tileNum != 0 && "tile num can not be zero!"); this->tileLength = this->blockLength / tileNum / BUFFER_NUM; // 获取当前核的起始索引 xGm.SetGlobalBuffer((__gm__ DTYPE_X*)x + this->blockLength * GetBlockIdx(), this->blockLength); yGm.SetGlobalBuffer((__gm__ DTYPE_Y*)y + this->blockLength * GetBlockIdx(), this->blockLength); zGm.SetGlobalBuffer((__gm__ DTYPE_Z*)z + this->blockLength * GetBlockIdx(), this->blockLength); // 通过Pipe内存管理对象为输入输出Queue分配内存 pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(DTYPE_X)); pipe.InitBuffer(inQueueY, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Y)); pipe.InitBuffer(outQueueZ, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Z)); } // 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作 __aicore__ inline void Process() { int32_t loopCount = this->tileNum * BUFFER_NUM; for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i); CopyOut(i); } } private: // 搬入函数,完成CopyIn阶段的处理,被核心Process函数调用 __aicore__ inline void CopyIn(int32_t progress) { // 从Queue中分配输入Tensor LocalTensor<DTYPE_X> xLocal = inQueueX.AllocTensor<DTYPE_X>(); LocalTensor<DTYPE_Y> yLocal = inQueueY.AllocTensor<DTYPE_Y>(); // 将GlobalTensor数据拷贝到LocalTensor DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength); DataCopy(yLocal, yGm[progress * this->tileLength], this->tileLength); // 将LocalTesor放入VECIN(代表矢量编程中搬入数据的逻辑存放位置)的Queue中 inQueueX.EnQue(xLocal); inQueueY.EnQue(yLocal); } // 计算函数,完成Compute阶段的处理,被核心Process函数调用 __aicore__ inline void Compute(int32_t progress) { // 将Tensor从队列中取出,用于后续计算 LocalTensor<DTYPE_X> xLocal = inQueueX.DeQue<DTYPE_X>(); LocalTensor<DTYPE_Y> yLocal = inQueueY.DeQue<DTYPE_Y>(); // 从Queue中分配输出Tensor LocalTensor<DTYPE_Z> zLocal = outQueueZ.AllocTensor<DTYPE_Z>(); // 调用Add接口进行计算 Add(zLocal, xLocal, yLocal, this->tileLength); // 将计算结果LocalTensor放入到VecOut的Queue中 outQueueZ.EnQue<DTYPE_Z>(zLocal); // 释放输入Tensor inQueueX.FreeTensor(xLocal); inQueueY.FreeTensor(yLocal); } // 搬出函数,完成CopyOut阶段的处理,被核心Process函数调用 __aicore__ inline void CopyOut(int32_t progress) { // 从VecOut的Queue中取出输出Tensor LocalTensor<DTYPE_Z> zLocal = outQueueZ.DeQue<DTYPE_Z>(); // 将输出Tensor拷贝到GlobalTensor中 DataCopy(zGm[progress * this->tileLength], zLocal, this->tileLength); // 将不再使用的LocalTensor释放 outQueueZ.FreeTensor(zLocal); } private: //Pipe内存管理对象 TPipe pipe; //输入数据Queue队列管理对象,QuePosition为VECIN TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; //输出数据Queue队列管理对象,QuePosition为VECOUT TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; //管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出 GlobalTensor<DTYPE_X> xGm; GlobalTensor<DTYPE_Y> yGm; GlobalTensor<DTYPE_Z> zGm; // 每个核上总计算数据大小 uint32_t blockLength; // 每个核上总计算数据分块个数 uint32_t tileNum; // 每个分块大小 uint32_t tileLength; };
Host侧算子实现
核函数开发并验证完成后,下一步就是进行Host侧的实现,对应“AddCustom/op_host”目录下的add_custom_tiling.h文件与add_custom.cpp文件。下面简要介绍下两个文件的关键实现,完整的样例代码可参见add_custom_tiling.h与add_custom.cpp。
- 修改“add_custom_tiling.h”文件,在此文件中增加粗体部分的代码,进行Tiling参数的定义。
#ifndef ADD_CUSTOM_TILING_H #define ADD_CUSTOM_TILING_H #include "register/tilingdata_base.h" namespace optiling { BEGIN_TILING_DATA_DEF(TilingData) // AddCustom算子使用了2个tiling参数:totalLength与tileNum TILING_DATA_FIELD_DEF(uint32_t, totalLength); // 总计算数据量 TILING_DATA_FIELD_DEF(uint32_t, tileNum); // 每个核上总计算数据分块个数 END_TILING_DATA_DEF; // 注册tiling数据到对应的算子 REGISTER_TILING_DATA_CLASS(AddCustom, TilingData) } #endif // ADD_CUSTOM_TILING_H - 修改“add_custom.cpp”文件,进行Tiling的实现。修改“TilingFunc”函数,实现Tiling上下文的获取,并通过上下文获取输入输出shape信息,并根据shape信息设置TilingData、序列化保存TilingData,并设置TilingKey。
namespace optiling { const uint32_t BLOCK_DIM = 8; const uint32_t TILE_NUM = 8; static ge::graphStatus TilingFunc(gert::TilingContext* context) { TilingData tiling; uint32_t totalLength = context->GetInputTensor(0)->GetShapeSize(); context->SetBlockDim(BLOCK_DIM); tiling.set_totalLength(totalLength); tiling.set_tileNum(TILE_NUM); tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize()); context->SetTilingKey(1); size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0; return ge::GRAPH_SUCCESS; } } // namespace optiling - 在“add_custom.cpp”文件中实现AddCustom算子的shape推导。
Add算子的输出shape等于输入shape,所以直接将输入shape赋給输出shape,当前msopgen工具生成的代码“InferShape”函数无需修改。
- 修改“add_custom.cpp”文件中的算子原型注册,此函数为入口函数。
namespace ops { class AddCustom : public OpDef { public: explicit AddCustom(const char* name) : OpDef(name) { // Add算子的第一个输入 this->Input("x") .ParamType(REQUIRED) // 代表输入必选 .DataType({ ge::DT_FLOAT16, ge::DT_FLOAT, ge::DT_INT32 }) // 输入支持的数据类型 .Format({ ge::FORMAT_ND, ge::FORMAT_ND, ge::FORMAT_ND }) // 输入支持的数据格式 .UnknownShapeFormat({ ge::FORMAT_ND, ge::FORMAT_ND, ge::FORMAT_ND }); // 未知Shape情况下的Format的默认值 // Add算子的第二个输入 this->Input("y") .ParamType(REQUIRED) .DataType({ ge::DT_FLOAT16, ge::DT_FLOAT, ge::DT_INT32 }) .Format({ ge::FORMAT_ND, ge::FORMAT_ND, ge::FORMAT_ND }) .UnknownShapeFormat({ ge::FORMAT_ND, ge::FORMAT_ND, ge::FORMAT_ND }); this->Output("z") .ParamType(REQUIRED) .DataType({ ge::DT_FLOAT16, ge::DT_FLOAT, ge::DT_INT32 }) .Format({ ge::FORMAT_ND, ge::FORMAT_ND, ge::FORMAT_ND }) .UnknownShapeFormat({ ge::FORMAT_ND, ge::FORMAT_ND, ge::FORMAT_ND }); // 关联InferShape函数 this->setinferShape(ge::InferShape); // 关联Tiling函数 this->AICore() .SetTiling(optiling::TilingFunc); // 注册算子支持的AI处理器型号 this->AICore().AddConfig("ascend910"); } }; // 结束算子注册 OP_ADD(AddCustom); } // namespace ops
算子工程编译部署
编译AddCustom工程,生成自定义算子安装包,并将其安装到算子库中。
- 编译自定义算子工程,构建生成自定义算子包。
- 修改CMakePresets.json中ASCEND_CANN_PACKAGE_PATH为CANN软件包安装路径。
{ …… "configurePresets": [ { …… "ASCEND_CANN_PACKAGE_PATH": { "type": "PATH", "value": "/usr/local/Ascend/latest" //请替换为CANN软件包安装后的实际路径 }, …… } ] } - 在算子工程AddCustom目录下执行如下命令,进行算子工程编译。
./build.sh
编译成功后,会在当前目录下创建build_out目录,并在build_out目录下生成自定义算子安装包custom_opp_<target os>_<target architecture>.run,例如“custom_opp_ubuntu_x86_64.run”。
- 修改CMakePresets.json中ASCEND_CANN_PACKAGE_PATH为CANN软件包安装路径。
- 自定义算子安装包部署。
在自定义算子包所在路径下,执行如下命令,安装自定义算子包。
./custom_opp_<target os>_<target architecture>.run
命令执行成功后,自定义算子包中的相关文件将部署至当前环境的OPP算子库的vendors/customize目录中,如果用户部署多个自定义算子包,可通过如下命令指定路径安装:
./custom_opp_<target os>_<target architecture>.run --install-path=<path>
说明:如果部署算子包时通过配置--install-path参数指定了算子包的安装目录,则在使用自定义算子前,需要执行source <path>/vendors/<vendor_name>/bin/set_env.bash命令,set_env.bash脚本中将自定义算子包的安装路径追加到环境变量ASCEND_CUSTOM_OPP_PATH中,使自定义算子在当前环境中生效。
查看部署后的目录结构,如下所示:├── opp // 算子库目录 │ ├── built-in // 内置算子所在目录 │ ├── vendors // 自定义算子所在目录 │ ├── config.ini │ └── vendor_name1 // 自定义算子所在目录,若不指定路径安装,默认为“customize” │ ├── framework //自定义算子插件库 │ ├── op_impl │ │ └── ai_core │ │ └── tbe │ │ ├── config │ │ │ └── ${soc_version} //昇腾AI处理器类型 │ │ │ └── aic-${soc_version}-ops-info.json //自定义算子信息库文件 │ │ ├── vendor_name1_impl //自定义算子实现代码文件 │ │ │ └── dynamic │ │ │ ├── xx.cpp │ │ │ └── xx.py │ │ ├── kernel //自定义算子二进制文件 │ │ │ └── ${soc_version} //昇腾AI处理器类型 │ │ │ └── config │ │ └── op_tiling │ │ ├── lib │ │ └── liboptiling.so │ └── op_proto //自定义算子原型库所在目录 │ ├── inc │ │ └── op_proto.h │ └── lib │ ├── vendor_name2 // 存储厂商vendor_name2部署的自定义算子
算子ST测试
CANN开发套件包中提供了ST测试工具“msopst”,用于生成算子的ST测试用例并在硬件环境中执行。
本节仅以AddCustom算子为例,介绍ST测试工具的关键执行流程。
- 创建算子ST测试用例定义文件“AddCustom_case.json”,例如存储到跟算子工程目录“AddCustom”同级别的“AddCustom_st”路径下。“AddCustom_case.json”文件的样例如下,开发者可基于此文件定制修改。
[ { "case_name": "Test_AddCustom_001", "op": "AddCustom", "input_desc": [ { "format": [ "ND" ], "type": [ "float16" ], "shape": [8,2048], "data_distribute": [ "uniform" ], "value_range": [ [ 0.1, 1.0 ] ], "name": "x" }, { "format": [ "ND" ], "type": [ "float16" ], "shape": [8,2048], "data_distribute": [ "uniform" ], "value_range": [ [ 0.1, 1.0 ] ], "name": "y" } ], "output_desc": [ { "format": [ "ND" ], "type": [ "float16" ], "shape": [8,2048], "name": "z" } ] } ] - 配置ST测试用例执行时依赖的环境变量。
export DDK_PATH=$HOME/Ascend/ascend-toolkit/latest export NPU_HOST_LIB=$HOME/Ascend/ascend-toolkit/latest/runtime/lib64/stub
提示:请根据CANN软件包实际安装路径对以上环境变量进行修改。
- 进入msopst工具所在目录,执行如下命令生成并执行测试用例。
- 进入msopst工具所在目录。
cd $HOME/Ascend/ascend-toolkit/latest/python/site-packages/bin
- 生成测试用例文件并执行。
./msopst run -i $HOME/AddCustom_st/AddCustom_case.json -soc <soc_version> -out $HOME/AddCustom_st- -i:算子测试用例定义文件(*.json)的路径,可配置为绝对路径或者相对路径。
- -soc:昇腾AI处理器的型号,请根据实际环境进行替换。
- -out:生成文件所在路径。
此命令执行完成后,会输出类似如下打屏结果:
------------------------------------------------------------------------ - test case count: 1 - success count: 1 - failed count: 0 ------------------------------------------------------------------------ 2023-08-28 20:20:40 (25058) - [INFO] Process finished! 2023-08-28 20:20:40 (25058) - [INFO] The st report saved in: xxxx/AddCustom_st/20230828202015/st_report.json.
您也可以查看上述屏显信息提示的“st_report.json”文件,查看详细运行结果。
- 进入msopst工具所在目录。
