Pytorch框架
本节将介绍自定义算子开发完成后,如何通过适配开发,从而在Pytorch框架中可以调用到该算子。
背景知识
通过Pytorch框架进行模型的训练、推理时,会调用到很多算子进行计算,目前Pytorch提供了常用的算子接口和接口的注册分发机制,可以将算子映射到不同的底层硬件设备。Pytorch适配框架对此功能进行扩展,提供将Pytorch算子映射到昇腾AI处理器的功能。Pytorch适配框架架构图如图1所示。
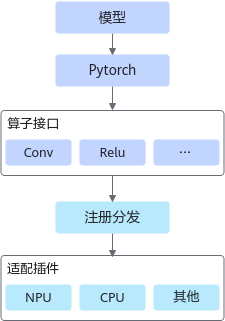
从上图可以看出,Pytorch的适配流程,主要包括两个步骤:算子注册分发和适配插件实现。下文以PyTorch1.11.0及以上官方版本为例,介绍Pytorch的适配流程。
单击LINK并解压,可以获取到Pytorch适配框架的源码包。

- 使用Pytorch框架完成自定义算子的调用,需要先完成算子的编译部署。
- 编译部署时需要开启算子的二进制编译功能:修改算子工程中的编译配置项文件CMakePresets.json,将ENABLE_BINARY_PACKAGE设置为True。编译部署时可将算子的二进制部署到当前环境,便于后续算子的调用。
"ENABLE_BINARY_PACKAGE": { "type": "BOOL", "value": "True" }, - 编译部署后,执行pytorch脚本前,需要将算子接口库的路径设置到共享库的查找路径中。下面示例仅作为参考,请根据实际情况进行设置。
export LD_LIBRARY_PATH=$ASCEND_OPP_PATH/vendors/customize/op_api/lib/:$LD_LIBRARY_PATH
算子注册分发
对于自定义算子,由于没有具体的算子定义,我们需要在npu_native_functions.yaml文件中给出定义,以便对算子进行结构化解析从而实现自动化注册和Python接口绑定。
npu_native_functions.yaml文件介绍如下,您可以参考npu_native_functions.yaml文件介绍,在文件中添加对应类型需要适配的算子信息。npu_native_functions.yaml文件具体存放路径为:Pytorch适配框架的源码包目录下的torch_npu/csrc/aten/npu_native_functions.yaml。
backend: NPU # Backend类型
cpp_namespace: at_npu::native # 插件中开发算子的命名空间
supported: # 已支持的和PyTorch Native Functions对齐的算子
- add.Tensor
- add.Scalar
- slow_conv3d.out
- slow_conv3d_forward.output
- slow_conv3d_forward
- convolution
- _convolution
- _convolution_nogroup
- addcdiv
- addcdiv_
- addcdiv.out
autograd: # 已支持的和PyTorch Native Functions对齐的继承自Function的具有前反向操作的算子
- maxpool2d
custom: # 自定义算子,需要提供算子格式定义
- func: npu_dtype_cast(Tensor self, ScalarType dtype) -> Tensor
variants: function, method
- func: npu_dtype_cast_(Tensor(a!) self, Tensor src) -> Tensor(a!)
variants: method
- func: npu_alloc_float_status(Tensor self) -> Tensor
variants: function, method
- func: npu_get_float_status(Tensor self) -> Tensor
variants: function, method
custom_autograd: # 自定义继承自Function的自定义算子
- func: npu_convolution(Tensor input, Tensor weight, Tensor? bias, ...) -> Tensor
适配插件开发
下面介绍开发Pytorch适配的具体过程。用户通过开发算子适配插件,实现PyTorch原生算子的输入参数、输出参数和属性的格式转换,使转换后的格式与自定义算子的输入参数、输出参数和属性的格式相同。
- 创建适配插件文件。
Ascend C算子适配文件保存在torch_npu/csrc/aten/ops/op_api目录下,命名风格采用大驼峰,命名格式:<算子名> + <KernelNpu>.cpp,如:AddCustomKernelNpu.cpp。
- 引入依赖头文件。
适配昇腾AI处理器的PyTorch源代码在torch_npu/csrc/framework/utils中提供适配常用的工具供用户使用。

工具的功能和使用方法,请查看头文件和.cpp源码。
- 定义实现算子适配主体函数。
实现算子适配主体函数,根据Ascend C算子原型构造得到对应的input、output、attr。
- 重编译PyTorch框架或插件。
请重新编译生成torch_npu插件安装包并安装。
参考样例
下文以自定义Add算子为例,介绍PyTorch1.11.0框架下,注册算子开发过程以及算子适配开发过程。参考样例的完整代码请单击链接Link获取。为了方便您的使用,样例中将下文的步骤统一封装在一个运行脚本中,您可以执行脚本run.sh一键式运行。
- 参考算子开发(进阶篇)完成自定义算子工程创建、算子开发、编译部署流程。
- 编译部署时需要开启算子的二进制编译功能:修改算子工程中的编译配置项文件CMakePresets.json,将ENABLE_BINARY_PACKAGE设置为True。编译部署时可将算子的二进制部署到当前环境,便于后续算子的调用。
"ENABLE_BINARY_PACKAGE": { "type": "BOOL", "value": "True" }, - 编译部署后,执行pytorch脚本前,需要将算子接口库的路径设置到共享库的查找路径中。下面示例仅作为参考,请根据实际情况进行设置。
export LD_LIBRARY_PATH=$ASCEND_OPP_PATH/vendors/customize/op_api/lib/:$LD_LIBRARY_PATH
- 编译部署时需要开启算子的二进制编译功能:修改算子工程中的编译配置项文件CMakePresets.json,将ENABLE_BINARY_PACKAGE设置为True。编译部署时可将算子的二进制部署到当前环境,便于后续算子的调用。
- 单击LINK,获取PTA源码包,并解压。
unzip -o -q pytorch-v1.11.0.zip
- 进行PTA自定义算子注册。
- 打开npu_native_functions.yaml文件
vi pytorch-v1.11.0/torch_npu/csrc/aten/npu_native_functions.yaml
- 将如下信息拷贝至npu_native_functions.yaml中的custom:节点下
- func: npu_add_custom(Tensor x, Tensor y) -> Tensor
拷贝后的示意代码如下:
custom: - func: npu_add_custom(Tensor x, Tensor y) -> Tensor
- 打开npu_native_functions.yaml文件
- 在pytorch-v1.11.0/torch_npu/csrc/aten/ops/op_api目录下,创建AddCustomKernelNpu.cpp文件并实现算子适配主体函数npu_add_custom。其核心逻辑为调用EXEC_NPU_CMD接口,完成输出结果的计算,EXEC_NPU_CMD第一个入参格式为aclnn+Optype(算子类型),之后的参数分别为输入输出。完整的AddCustomKernelNpu.cpp文件内容如下:
#include <torch/csrc/autograd/custom_function.h> #include "torch_npu/csrc/framework/utils/OpAdapter.h" #include "torch_npu/csrc/aten/NPUNativeFunctions.h" #include "torch_npu/csrc/aten/ops/op_api/op_api_common.h" namespace at_npu { namespace native { using torch::autograd::Function; using torch::autograd::AutogradContext; at::Tensor NPUNativeFunctions::npu_add_custom(const at::Tensor& x, const at::Tensor& y) { // 构造输出tensor at::Tensor result = OpPreparation::ApplyTensor(x); // 调用EXEC_NPU_CMD接口,完成输出结果的计算 // 第一个入参格式为aclnn+Optype,之后的参数分别为输入输出 EXEC_NPU_CMD(aclnnAddCustom, x, y, result); return result; } } // namespace native } // namespace at_npu - 编译PTA插件并安装。命令中的python版本请根据实际情况进行设置。
cd pytorch-v1.11.0 bash ci/build.sh --python=3.7 pip3 install dist/*.whl --force-reinstall
上述开发过程完成后,您可以调用如下的脚本,测试torch_npu.npu_add_custom()的功能,测试脚本如下:
import torch
import torch_npu
from torch_npu.testing.testcase import TestCase, run_tests
torch.npu.config.allow_internal_format=False
class TestCustomAdd(TestCase):
def test_add_custom(self):
length = [8, 2048]
x = torch.rand(length, device='cpu', dtype=torch.float16)
y = torch.rand(length, device='cpu', dtype=torch.float16)
print(x, '\n', y)
prof_path = "./prof_total"
with torch.npu.profile(prof_path) as prof:
torch.npu.synchronize()
output = torch_npu.npu_add_custom(x.npu(), y.npu()).cpu()
torch.npu.synchronize()
print(output)
self.assertRtolEqual(output, x + y)
if __name__ == "__main__":
run_tests()
执行命令如下:
python3 test_ops_custom.py
输出如下打印,说明执行正确:
tensor([[0.1152, 0.9385, 0.7095, ..., 0.7500, 0.3130, 0.0044],
[0.2759, 0.1240, 0.3550, ..., 0.7183, 0.3540, 0.5127],
[0.6475, 0.8037, 0.6343, ..., 0.0840, 0.3560, 0.8677],
...,
[0.7900, 0.2070, 0.7319, ..., 0.2363, 0.2803, 0.2510],
[0.2993, 0.3140, 0.4355, ..., 0.8130, 0.3618, 0.5693],
[0.3540, 0.7471, 0.9448, ..., 0.8877, 0.8691, 0.0869]],
dtype=torch.float16)
tensor([[0.6689, 0.2119, 0.3105, ..., 0.6313, 0.9546, 0.7935],
[0.0757, 0.8447, 0.2329, ..., 0.7256, 0.9160, 0.3975],
[0.1968, 0.6567, 0.5322, ..., 0.3071, 0.8501, 0.0947],
...,
[0.6748, 0.4189, 0.7202, ..., 0.0103, 0.6133, 0.3706],
[0.1079, 0.3457, 0.7505, ..., 0.5947, 0.4390, 0.4434],
[0.4102, 0.1792, 0.9648, ..., 0.6333, 0.5381, 0.6646]],
dtype=torch.float16)
tensor([[0.7842, 1.1504, 1.0195, ..., 1.3809, 1.2676, 0.7979],
[0.3516, 0.9688, 0.5879, ..., 1.4434, 1.2695, 0.9102],
[0.8442, 1.4609, 1.1660, ..., 0.3911, 1.2061, 0.9624],
...,
[1.4648, 0.6260, 1.4521, ..., 0.2466, 0.8936, 0.6216],
[0.4072, 0.6597, 1.1855, ..., 1.4082, 0.8008, 1.0127],
[0.7642, 0.9263, 1.9102, ..., 1.5215, 1.4072, 0.7515]],
dtype=torch.float16)
.
----------------------------------------------------------------------
Ran 1 test in 0.669s
OK
