Hccl模板参数
功能说明
创建Hccl对象时需要传入模板参数HcclServerType 。
函数原型
Hccl类定义如下,模板参数HcclServerType说明见表1。
1 2 |
template <HcclServerType serverType = HcclServerType::HCCL_SERVER_TYPE_AICPU> class Hccl; |
参数说明
返回值
无
支持的型号
约束说明
无
调用示例
- 示例1
本示例使用标准C++语法定义TilingData结构体的开发方式,具体请参考使用标准C++语法定义TilingData。在使用Hccl高阶API自定义开发时,推荐使用该方式。
- host侧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92
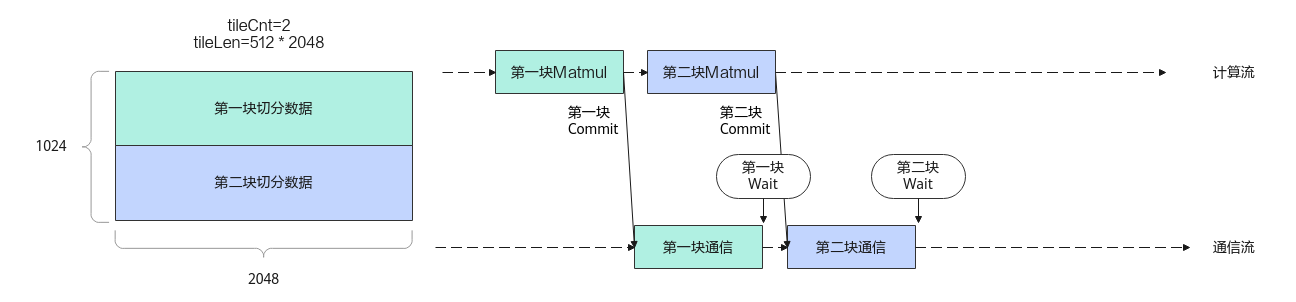
// matmul_all_reduce_custom.cpp static ge::graphStatus MatmulAllReduceCustomTilingFunc(gert::TilingContext *context) { // 对参数进行校验 if (ParamsCheck(context) != ge::GRAPH_SUCCESS) { ERROR_LOG("Param check failed"); return ge::GRAPH_FAILED; } uint32_t index = 0U; auto group = context->GetAttrs()->GetAttrPointer<char>(index++); auto reduceOp = context->GetAttrs()->GetAttrPointer<char>(index++); auto isTransA = context->GetAttrs()->GetAttrPointer<bool>(index++); auto isTransB = context->GetAttrs()->GetAttrPointer<bool>(index++); auto commTurn = context->GetAttrs()->GetAttrPointer<int>(index++); auto antiQuantSize = context->GetAttrs()->GetAttrPointer<int>(index++); uint64_t M = context->GetInputShape(0)->GetStorageShape().GetDim(0); uint64_t K = context->GetInputShape(0)->GetStorageShape().GetDim(1); uint64_t N = *isTransB ? context->GetInputShape(1)->GetStorageShape().GetDim(0) : context->GetInputShape(1)->GetStorageShape().GetDim(1); auto aTensorDesc = context->GetInputDesc(0); auto aType = aTensorDesc->GetDataType(); auto ascendcPlatform = platform_ascendc::PlatformAscendC(context->GetPlatformInfo()); const auto aicNum = ascendcPlatform.GetCoreNumAic(); context->SetBlockDim(aicNum); context->SetTilingKey(CUSTOM_TILING_KEY); size_t workspaceSize = ascendcPlatform.GetLibApiWorkSpaceSize() + M * N * 2; size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = workspaceSize; uint8_t tileNum = M / TILE_M; uint64_t tailM = M % TILE_M; uint8_t tailNum = (tailM == 0) ? 0 : 1; // Kernel注册到框架中的结构体,通过GetTilingData在tiling侧获取 MatmulAllReduceCustomTilingData *tiling = context->GetTilingData<MatmulAllReduceCustomTilingData>(); // 可以通过C++的方式设置tiling tiling->param.rankDim = RANK_NUM; tiling->param.rankM = M; tiling->param.rankN = N; tiling->param.rankK = K; tiling->param.isTransposeA = (*isTransA ? 1 : 0); tiling->param.isTransposeB = (*isTransB ? 1 : 0); tiling->param.determinism = 0; tiling->param.tileCnt = tileNum; tiling->param.tailM = tailM; tiling->param.tailCnt = tailNum; tiling->param.dataType = 3; // 3: FP16,目前只支持 FP16 // matmul tiling func auto matmulTilingFunc = [&] (int64_t m, int64_t n, int64_t k, TCubeTiling &cubeTiling) -> bool { matmul_tiling::MultiCoreMatmulTiling mmTiling; mmTiling.SetAType(matmul_tiling::TPosition::GM, matmul_tiling::CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT16, *isTransA); mmTiling.SetBType(matmul_tiling::TPosition::GM, matmul_tiling::CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT16, *isTransB); mmTiling.SetCType(matmul_tiling::TPosition::GM, matmul_tiling::CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT16); mmTiling.SetBias(false); mmTiling.SetDim(aicNum); mmTiling.SetShape(m, n, k); mmTiling.SetOrgShape(m, n, k); mmTiling.SetBufferSpace(L1_BUFFER_SIZE, -1, -1); int32_t fixCoreM = -1; int32_t fixCoreK = -1; int32_t fixCoreN = -1; mmTiling.SetSingleShape(fixCoreM, fixCoreN, fixCoreK); if (mmTiling.GetTiling(cubeTiling) != 0) { return false; } return true; }; // matmul tile tiling if (tileNum > 0){ if (!matmulTilingFunc(TILE_M, N, K, tiling->matmulTiling)) { ERROR_LOG("Get tile matmul tiling failed"); return ge::GRAPH_FAILED; } } // matmul tail tiling if (tailNum > 0) { if (!matmulTilingFunc(tailM, N, K, tiling->tailTiling)) { ERROR_LOG("Get tail matmul tiling failed"); return ge::GRAPH_FAILED; } } // allGather=6, allReduce=2, reduceScatter=7, allToAll=10, allToAllV=8 uint32_t opType = 2; std::string algConfig = "AllGather=level0:doublering"; // sum=0, prod=1, max=2, min=3, reserved=4 uint32_t reduceType = 0; AscendC::Mc2CcTilingConfig mc2CcTilingConfig(group, opType, algConfig, reduceType); // 如果需要配置,需要在GetTiling之前 mc2CcTilingConfig.GetTiling(tiling->mc2InitTiling); mc2CcTilingConfig.GetTiling(tiling->mc2CcTiling); return ge::GRAPH_SUCCESS; }
- kernel侧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
// matmul_all_reduce_custom_tiling.h #include "kernel_tiling/kernel_tiling.h" struct AllReduceRCSTiling { uint32_t rankDim; uint64_t rankM; uint64_t rankN; uint64_t rankK; uint32_t isTransposeA; uint32_t isTransposeB; uint8_t determinism; uint8_t tileCnt; uint64_t tailM; uint8_t tailCnt; uint32_t dataType; }; // 用户可自定义结构体 class MatmulAllReduceCustomTilingData { public: Mc2InitTiling mc2InitTiling; Mc2CcTiling mc2CcTiling; TCubeTiling matmulTiling; TCubeTiling tailTiling; AllReduceRCSTiling param; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130
// matmul_all_reduce_custom.cpp // @brief Matmul+AllReduce融合算子kernel // @param [in] aGM: Matmul计算的第一个输入对应的GM内存 // @param [in] bGM: Matmul计算的第二个输入对应的GM内存 // @param [in] biasGM: Matmul计算的第三个输入对应的GM内存 // @param [in] addGM: Matmul计算的第四个输入对应的GM内存 // @param [in] antiquantScaleGM: Matmul计算的第五个输入对应的GM内存 // @param [in] antiquantOffsetGM: Matmul计算的第六个输入对应的GM内存 // @param [in] dequantGM: Matmul计算的第七个输入对应的GM内存 // @param [out] cGM: add+allreduce+mul融合计算的输出GM内存 // @param [in] workspaceGM 用于存储中间计算结果的GM内存 // @param [in] tilingGM 存放TilingData的GM内存 extern "C" __global__ __aicore__ void matmul_all_reduce_custom(GM_ADDR aGM, GM_ADDR bGM, GM_ADDR biasGM, GM_ADDR addGM, GM_ADDR antiquantScaleGM, GM_ADDR antiquantOffsetGM, GM_ADDR dequantGM, GM_ADDR cGM, GM_ADDR workspaceGM, GM_ADDR tilingGM) { if (AscendC::g_coreType == AIV){ return; } if (workspaceGM == nullptr) { return; } GM_ADDR userWS = GetUserWorkspace(workspaceGM); if (userWS == nullptr) { return; } // 将用户自定义的接口结构注册到tiling中 REGISTER_TILING_DEFAULT(MatmulAllReduceCustomTilingData); auto tilingData = (__gm__ MatmulAllReduceCustomTilingData*)tilingGM; __gm__ void *mc2InitTiling = (__gm__ void *)(&(tilingData->mc2InitTiling)); // 取出InitTiling地址 __gm__ void *mc2CcTiling = (__gm__ void *)(&(tilingData->mc2CcTiling)); // 取出CcOpTiling地址 GET_TILING_DATA(tilingData, tilingGM); auto &&cfg = tilingData.param; auto &&tiling = tilingData.matmulTiling; auto &&tailTiling = tilingData.tailTiling; Hccl hccl; GM_ADDR context = AscendC::GetHcclContext<0>(); // step1. 用户创建Hccl客户端对象的创建+初始化 hccl.Init(context, mc2InitTiling); // Init接口用传入initTiling地址的方式 // step2. 设置AllReduce算法对应的ccTilng地址 hccl.SetCcTiling(mc2CcTiling); KERNEL_TASK_TYPE_DEFAULT(KERNEL_TYPE_MIX_AIC_1_2); // 设置CV核比例AIC:AIV 1:2 if (TILING_KEY_IS(1000UL)) { using aType = MatmulType<AscendC::TPosition::GM, CubeFormat::ND, DTYPE_X1>; using bType = MatmulType<AscendC::TPosition::GM, CubeFormat::ND, DTYPE_X2>; using cType = MatmulType<AscendC::TPosition::GM, CubeFormat::ND, DTYPE_Y>; using biasType = MatmulType<AscendC::TPosition::GM, CubeFormat::ND, half>; GM_ADDR aAddr = aGM; GM_ADDR cAddr = cGM; GM_ADDR computeResAddrGM = cGM; // 计算结果存放位置 GM_ADDR computeResAddr = computeResAddrGM; // tile 首块处理 AscendC::HcclHandle handleId = -1; if (cfg.tileCnt > 0){ auto tileLen = tiling.M * tiling.N; // Step3. Prepare数据 handleId = hccl.AllReduce<false>(computeResAddr, cAddr, tileLen, AscendC::HCCL_DATA_TYPE_FP16, AscendC::HCCL_REDUCE_SUM, cfg.tileCnt); // Step4. Matmul计算,在每一块Matmul计算完成后,调用Commit进行通信 AscendC::MatMulKernelAllReduce<aType, bType, cType, biasType>(aAddr, bGM, cAddr, computeResAddr, biasGM, tiling, cfg, hccl, cfg.tileCnt, handleId); } // 如果存在尾块,需要单独处理 aAddr = GetTailA(aGM, tiling, cfg.tileCnt); cAddr = GetTailC(cGM, tiling, cfg.tileCnt); computeResAddr = GetTailC(computeResAddrGM, tiling, cfg.tileCnt); auto tailLen = tailTiling.M * tailTiling.N; AscendC::HcclHandle handleIdTail = -1; if (cfg.tailM) { AscendC::HcclHandle handleIdTail = hccl.AllReduce<false>(computeResAddr, cAddr, tailLen, AscendC::HCCL_DATA_TYPE_FP16, AscendC::HCCL_REDUCE_SUM, cfg.tailCnt); MatMulKernelAllReduce<aType, bType, cType, biasType>(aAddr, bGM, cAddr, computeResAddr, biasGM, tailTiling, cfg, hccl, cfg.tailCnt, handleIdTail); } // Step5. 等待通信完成 for (uint32_t i = 0; i < cfg.tilelCnt; i++) { hccl.Wait(handleId); } for (uint32_t i = 0; i < cfg.tailCnt; i++) { hccl.Wait(handleIdTail); } } // Step6. C核同步,等待其他核计算+通信完成再一起退出 AscendC::CrossCoreSetF1ag<0x1, PIPE_FIX>(SYNC_AIC_FLAG); AscendC::CrossCoreWaitF1ag(SYNC_AIC_FLAG); // Step7. 后续无通信任务编排,用户调用Finalize接口通知服务端执行完通信任务后即可退出 hccl.Finalize(); } template <class A_TYPE, class B_TYPE, class C_TYPE, class BIAS_TYPE> __aicore__ inline void MatMulKernelAllReduce(GM_ADDR aAddr, GM_ADDR bGM, GM_ADDR cAddr, GM_ADDR computeResAddr, GM_ADDR biasGM, TCubeTiling &tiling, AllReduceRCSTiling &cfg, AscendC::Hccl<AscendC::HCCL_SERVER_TYPE_AICPU> &hccl, uint32_t tileCnt, AscendC::HcclHandle &handleId) { if (AscendC::g_coreType == AIV) { return; } if (AscendC::GetBlockIdx() >= tiling.usedCoreNum) { for (int i = 0; i < tileCnt; i++) { AscendC::CrossCoreSetF1ag<0x1, PIPE_FIX>(SYNC_AIC_FLAG); AscendC::CrossCoreWaitF1ag(SYNC_AIC_FLAG); } return; } using A_T = typename A_TYPE::T; using B_T = typename B_TYPE::T; using C_T = typename C_TYPE::T; using BiasT = typename BIAS_TYPE::T; auto aOffset = tiling.M * tiling.Ka * sizeof(A_T); auto cOffset = tiling.M * tiling.N * sizeof(C_T); // AllReduce 需要提前计算一次 C 矩阵的 Offset 地址 MatmulCompute<A_TYPE, B_TYPE, C_TYPE, BIAS_TYPE> mm; mm.Init(tiling, cfg); mm.InitGlobalBTensor(bGM, biasGM); for (int i = 0; i < tileCnt; i++) { mm.InitGlobalATensor(aAddr, aOffset, computeResAddr, cOffset); // 一次计算 mm.Compute(); // C核同步 AscendC::CrossCoreSetF1ag<0x1, PIPE_FIX>(SYNC_AIC_FLAG); AscendC::CrossCoreWaitF1ag(SYNC_AIC_FLAG); // 提交通信 hccl.Commit(handleId); aAddr += aOffset; cAddr += cOffset; computeResAddr += cOffset; } mm.End(); }
- host侧:
- 示例2
以Add计算+AllReduce通信+Mul计算的任务编排方式为例,辅以代码片段,对本通信API在计算和通信融合的场景下的使用进行说明:
图2 Add计算+AllReduce通信+Mul计算任务编排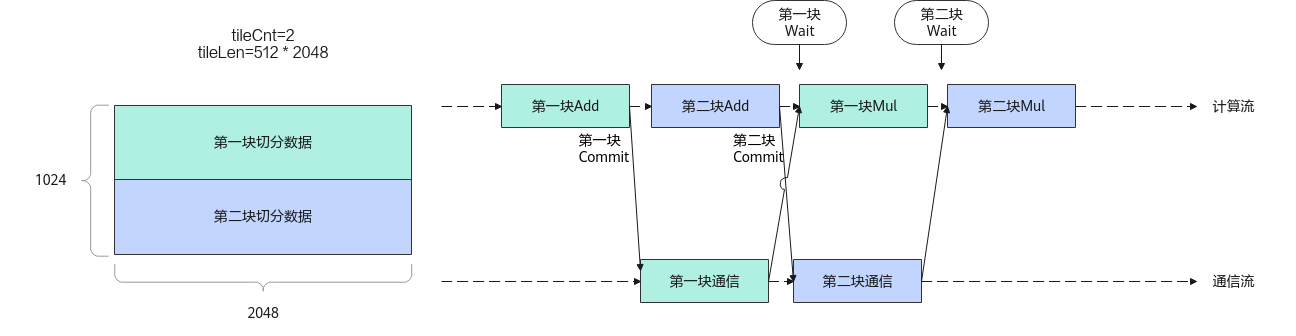
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70
// @brief add+allreduce+mul融合算子kernel, // 任务编排为先进行Add计算,然后将其计算结果作为AllReduce的输入进行ReduceSum操作, // 最后将AllReduce的结果作为Mul计算的第一个输入,与Mul的第二个输入进行element-wise mul计算,将结果写到cGM输出内存中。 // @param [in] aGM: Add计算的第一个输入对应的GM内存 // @param [in] bGM: Add计算的第二个输入对应的GM内存 // @param [in] mulGM: Mul计算的第二个输入对应的GM内存 // @param [out] cGM: add+allreduce+mul融合计算的输出GM内存 // @param [in] workspaceGM 用于存储中间计算结果的GM内存 // @param [in] tilingGM 存放TilingData的GM内存 extern "C" __global__ __aicore__ void add_all_reduce_mul( GM_ADDR aGM, GM_ADDR bGM, GM_ADDR mulGM, GM_ADDR cGM, GM_ADDR workspaceGM, GM_ADDR tilingGM) { KERNEL_TASK_TYPE_DEFAULT(KERNEL_TYPE_MIX_AIC_1_2); // 设置CV核比例AIC:AIV 1:2 // 从tilingGM中获取预先准备好的Tiling数据 // 此处假设Add和Mul计算的切分策略一致,即共用一个tiling数据 GET_TILING_DATA(tiling_data, tilingGM); int tileCnt = tiling_data.tileCnt; // 将1个输入数据切分为tileCnt轮进行计算 int tileLen = tiling_data.tileLen; // 每次计算的数据个数tileLen // Add计算API的初始化 KernelAdd add_op; add_op.Init(tileLen, 2); // step1. 用户创建Hccl客户端对象的创建+初始化 Hccl<HCCL_SERVER_TYPE_AICPU> hccl; auto contextGM = AscendC::GetHcclContext<0>(); // AscendC自定义算子框架提供的获取通信上下文的能力,对应的数据结构为:HcclCombinOpParam hccl.Init(contextGM); auto aAddr = aGM; // 每次切分计算,Add计算第一个输入参与计算的地址 auto bAddr = bGM; // 每次切分计算,Add计算第二个输入参与计算的地址 auto computeResAddr = workspaceGM; // workspaceGM用来临时存放Add计算的结果,同时作为通信任务的输入地址 auto cAddr = cGM; // cGM先用来存放AllReduce的通信结果,同时作为Mul计算的第一个输入 constexpr uint32_t kSizeOfFloat16 = 2U; auto aOffset = tileLen * kSizeOfFloat16; // 每次切分计算,Add计算第一个输入参与计算的数据size auto bOffset = tileLen * kSizeOfFloat16; // 每次切分计算,Add计算第二个输入参与计算的数据size auto cOffset = tileLen * kSizeOfFloat16; // 每次切分计算,Add计算结果得到的数据size HcclHandle hanleIdList[tileCnt]; for (int i = 0; i < tileCnt; i++) { // step2. 用户调用AllReduce接口,提前通知服务端完成通信任务的组装和下发,该接口返回该通信任务的标识handleId给用户 // 注意: 可以将这个通信任务下发在计算开始前生成,这样其任务组装会在计算流水中被掩盖 auto handleId = hccl.AllReduce(computeResAddr, cAddr, tileLen, HCCL_DATA_TYPE_FP16, HCCL_REDUCE_SUM); hanleIdList[i] = handleId; // step3 用户开始调用Add计算Api的初始化和计算,并调用SyncAll等待该计算完成 add_op.UpdateAddress(aAddr, bAddr, computeResAddr); add_op.Process(); // 等待计算任务在所有block上执行完成 SyncAll(); // step4. 当每份切分数据的Add计算完成后,用户即可调用Commit接口通知通信侧可以执行handleId对应的通信任务(异步接口) hccl.Commit(handleId); // 更新下一份切分数据的地址 aAddr += aOffset; bAddr += bOffset; computeResAddr += cOffset; cAddr += cOffset; } // Mul计算Api对象的创建 KernelMul mul_op; for (int i = 0; i < tileCnt; i++) { // step5. 用户在进行mul计算前,需要调用Wait阻塞接口确保对应切分数据的通信执行完毕,即确保mul的第一个输入的数据ready hccl.Wait(hanleIdList[i]); AscendC::SyncAll(); // 核间同步 // mul计算的参数设置,参数分别为:第一个输入的地址、第二个输入的地址、计算结果的地址,一次mul计算的数据个数 mul_op.InitAddress(cAddr, mulAddr, cAddr, tileLen, 1); // step6. mul计算执行 mul_op.Process(); // 更新下一份切分数据的地址 mulAddr += cOffset; cAddr += cOffset; } // step7. 后续无通信任务编排,用户调用Finalize接口通知服务端执行完通信任务后即可退出 hccl.Finalize(); }
父主题: Hccl