概述
开发者完成kernel侧算子实现和host侧tiling实现后,即可通过AscendCL运行时接口,完成算子kernel直调。该方式下tiling开发不受CANN框架的限制,简单直接,多用于算子功能的快速验证。
Kernel直调算子开发流程如下图所示:
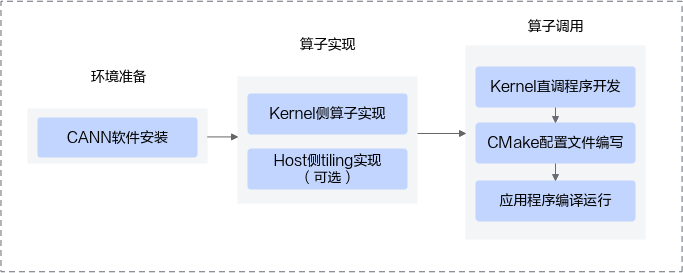
- 环境准备
CANN软件安装请参考环境准备。
- 算子实现
Kernel侧算子实现和host侧tiling实现请参考算子实现。
- 算子调用完成kernel直调程序的开发、CMake配置文件的编写后,按照如下kernel直调工程(如下工程结构仅为示例)组织相关代码文件,最后完成应用程序编译及运行。
|-- cmake // CMake编译文件 |-- CMakeLists.txt // CMake编译配置文件 |-- my_add.cpp // Kernel侧算子实现 |-- main.cpp // Kernel直调程序
Kernel直调分为CPU侧/NPU侧调用两种:
- CPU侧主要通过ICPU_RUN_KF CPU调测宏等CPU调测库提供的接口来完成;
- NPU侧主要通过使用Kernel Launch接口或者<<<>>>内核调用符,以及AscendCL API提供的运行时接口来完成。
CPU侧和NPU侧的kernel直调原理图如下:
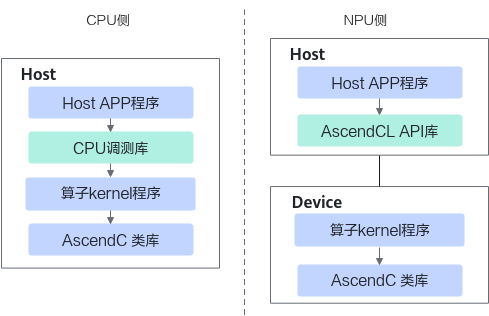
您可以根据下文Kernel直调的介绍来完成基本的运行验证流程,流程中使用到接口请参考:
- CPU侧kernel直调请参考调测接口。
- NPU侧kernel直调分为Kernel Launch方式和内核调用符方式。
- AscendCL API使用方法请参考AscendCL API参考。
基于NPU域算子调用编写的算子程序,通过毕昇编译器编译后运行,可以完成算子NPU域的运行验证;基于CPU域算子的调用接口(ICPU_RUN_KF CPU)编写的算子程序,通过标准的GCC编译器进行编译后运行,可以完成算子CPU域的运行验证。
CPU侧的运行程序,通过GDB通用调试工具进行单步调试,精准验证程序执行流程是否符合预期。如果您想进一步了解CPU侧调试的具体内容,可在完成本节内容的学习后参考CPU域调试。
Kernel Launch方式

当前版本暂不支持获取用户workspace特性。
ACLRT_LAUNCH_KERNEL调用接口的使用方法如下:
1
|
ACLRT_LAUNCH_KERNEL(kernel_name)(blockDim, stream, argument list); |
考虑名为add_custom的核函数调用的例子,该函数实现两个矢量的相加,调用示例如下:
1 2 |
// blockDim设置为8表示在8个核上调用了add_custom核函数,每个核都会独立且并行地执行该核函数,该核函数的参数列表为x,y,z。 ACLRT_LAUNCH_KERNEL(add_custom)(8, stream, x, y, z) |
内核调用符方式
核函数可以使用内核调用符<<<...>>>这种语法形式,来规定核函数的执行配置:
1
|
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list); |
- blockDim,规定了核函数将会在几个核上执行。每个执行该核函数的核会被分配一个逻辑ID,即block_idx,可以在核函数的实现中调用GetBlockIdx来获取block_idx;

blockDim是逻辑核的概念,取值范围为[1,65535]。为了充分利用硬件资源,一般设置为物理核的核数或其倍数。对于耦合架构和分离架构,blockDim在运行时的意义和设置规则有一些区别,具体说明如下:
- 耦合架构:由于其Vector、Cube单元是集成在一起的,blockDim用于设置启动多个AICore核实例执行,不区分Vector、Cube。AI Core的核数可以通过GetCoreNumAiv或者GetCoreNumAic获取。
- 分离架构
- 针对仅包含Vector计算的算子,blockDim用于设置启动多少个Vector(AIV)实例执行,比如某款AI处理器上有40个Vector核,建议设置为40。
- 针对仅包含Cube计算的算子,blockDim用于设置启动多少个Cube(AIC)实例执行,比如某款AI处理器上有20个Cube核,建议设置为20。
- 针对Vector/Cube融合计算的算子,启动时,按照AIV和AIC组合启动,blockDim用于设置启动多少个组合执行,比如某款AI处理器上有40个Vector核和20个Cube核,一个组合是2个Vector核和1个Cube核,建议设置为20,此时会启动20个组合,即40个Vector核和20个Cube核。注意:该场景下,设置的blockDim逻辑核的核数不能超过物理核(2个Vector核和1个Cube核组合为1个物理核)的核数。
- AIC/AIV的核数分别通过GetCoreNumAic和GetCoreNumAiv接口获取。
- l2ctrl,保留参数,暂时设置为固定值nullptr,开发者无需关注;
- stream,类型为aclrtStream,stream用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序在device上执行。stream创建等管理接口请参考Stream管理。
考虑名为add_custom的核函数调用的例子,该函数实现两个矢量的相加,调用示例如下:
1 2 |
// blockDim设置为8表示在8个核上调用了add_custom核函数,每个核都会独立且并行地执行该核函数,该核函数的参数列表为x,y,z。 add_custom<<<8, nullptr, stream>>>(x, y, z); |
内核调用符进行核函数调用的详细示例可参见核函数定义和调用。
核函数的调用是异步的,核函数的调用结束后,控制权立刻返回给主机端,可以调用以下aclrtSynchronizeStream函数来强制主机端程序等待所有核函数执行完毕。
1
|
aclError aclrtSynchronizeStream(aclrtStream stream); |