基础API通用说明
- Repeat times(迭代的次数)
- Block stride(单次迭代内不同block间地址步长)
- Repeat stride(相邻迭代间相同block的地址步长)
- Mask(用于控制参与运算的计算单元)

以上Repeat times、Block stride、Repeat stride、Mask为通用描述,其命名不一定与具体指令中的参数命名完全对应。
比如,单次迭代内不同block间地址步长Block stride参数,在单目指令中,对应为dstBlkStride、srcBlkStride参数;在双目指令中,对应为dstBlkStride、src0BlkStride、src1BlkStride参数。
您可以在具体接口的参数说明中,找到参数含义的描述。
重复迭代次数-Repeat times
矢量计算单元,每次读取连续的8个block(每个block32 Bytes,共256 Bytes)数据进行计算,为完成对输入数据的处理,必须通过多次迭代(repeat)才能完成所有数据的读取与计算。Repeat times表示迭代的次数。
如下图所示,待处理数据大小为16个block(512Bytes),每次迭代处理8个block(256Bytes),需要两次迭代完成计算,Repeat times应设置为2。

相邻迭代间相同datablock的地址步长
当Repeat times大于1,需要多次迭代完成矢量计算时,您可以根据不同的使用场景合理设置相邻迭代间相同block的地址步长Repeat stride的值。
- 连续计算场景:假设定义一个Tensor供目的操作数和源操作数同时使用(即地址重叠),Repeat stride取值为8。此时,矢量计算单元第一次迭代读取连续8个block,第二轮迭代读取下一个连续的8个block,通过多次迭代即可完成所有输入数据的计算。

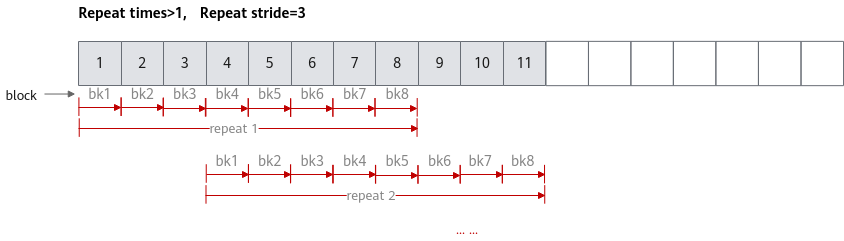
- 非连续计算场景:Repeat stride取值大于8(如取10)时,则相邻迭代间矢量计算单元读取的数据在地址上不连续,出现2个block的间隔。

- 反复计算场景:Repeat stride取值为0时,矢量计算单元会对首个连续的8个block进行反复读取和计算。
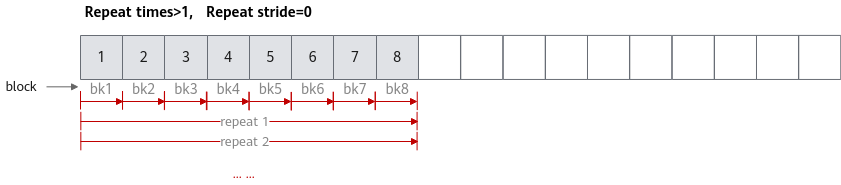
- 部分重复计算:Repeat stride取值大于0且小于8时,相邻迭代间部分数据会被矢量计算单元重复读取和计算,此种情形一般场景不涉及。
同一迭代内不同datablock的地址步长
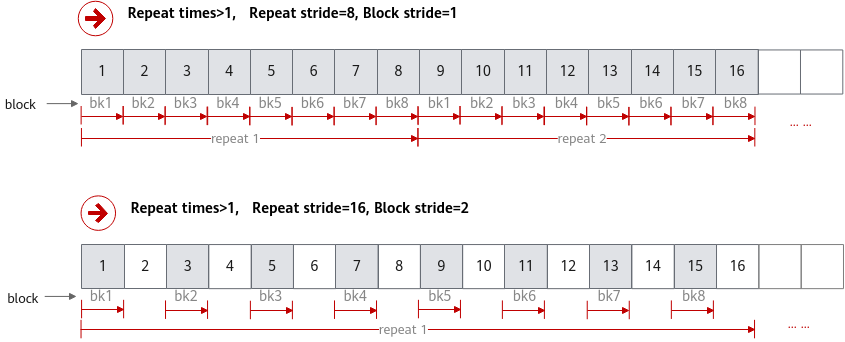
如果需要控制单次迭代内,数据处理的步长,可以通过设置同一迭代内不同block的地址步长Block stride来实现。
- 连续计算,Block stride 设置为1,对同一迭代内的8个block数据连续进行处理。
- 非连续计算,Block stride值大于1(如取2),同一迭代内不同block之间在读取数据时出现一个block的间隔,如下图所示。
图1 Block stride不同取值举例
Mask参数
mask用于控制每次迭代内参与计算的元素。可通过连续模式和逐比特模式两种方式进行设置。
- 连续模式:表示前面连续的多少个元素参与计算。数据类型为uint64_t。取值范围和操作数的数据类型有关,数据类型不同,每次迭代内能够处理的元素个数最大值不同(当前数据类型单次迭代时能处理的元素个数最大值为:256 / sizeof(数据类型))。当操作数的数据类型占比特位16位时(如half,uint16_t),mask∈[1, 128];当操作数为32位时(如float, int32_t),mask∈[1, 64]。
具体样例如下:
// int16_t数据类型单次迭代能处理的元素个数最大值为256/sizeof(int16_t) = 128,mask = 64,mask∈[1, 128],所以是合法输入 // repeatTimes = 1, 共128个元素,单次迭代能处理128个元素,故repeatTimes = 1 // dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据 // dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入 uint64_t mask = 64; Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 }); 结果示例如下: 输入数据(src0Local): [1 2 3 ... 64 ...128] 输入数据(src1Local): [1 2 3 ... 64 ...128] 输出数据(dstLocal): [2 4 6 ... 128 undefined...undefined]// int32_t数据类型单次迭代能处理的元素个数最大值为256/sizeof(int32_t) = 64,mask = 64,mask∈[1, 64],所以是合法输入 // repeatTimes = 1, 共64个元素,单次迭代能处理64个元素,故repeatTimes = 1 // dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据 // dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入 uint64_t mask = 64; Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 }); 结果示例如下: 输入数据(src0Local): [1 2 3 ... 64] 输入数据(src1Local): [1 2 3 ... 64] 输出数据(dstLocal): [2 4 6 ... 128]
- 逐bit模式:可以按位控制哪些元素参与计算,bit位的值为1表示参与计算,0表示不参与。参数类型为长度为2的uint64_t类型数组。
参数取值范围和操作数的数据类型有关,数据类型不同,每次迭代内能够处理的元素个数最大值不同。当操作数为16位时,mask[0]、mask[1]∈[0, 264-1],且mask[0]和mask[1]不可同时为0;当dst/src为32位时,mask[1]为0,mask[0]∈(0, 264-1]。
具体样例如下:
// 数据类型为int16_t uint64_t mask[2] = {6148914691236517205, 6148914691236517205}; // repeatTimes = 1, 共128个元素,单次迭代能处理128个元素,故repeatTimes = 1。 // dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据。 // dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入。 Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 }); 结果示例如下: 输入数据(src0Local): [1 2 3 ... 64 ...127 128] 输入数据(src1Local): [1 2 3 ... 64 ...127 128] 输出数据(dstLocal): [2 un 6 ... un ...254 undefined]mask过程如下:
mask={6148914691236517205, 6148914691236517205}(注:6,148,914,691,236,517,205表示64位二进制数0b010101....01)

// 数据类型为int32_t uint64_t mask[2] = {6148914691236517205, 0}; // repeatTimes = 1, 共64个元素,单次迭代能处理64个元素,故repeatTimes = 1。 // dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据。 // dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入。 Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 }); 结果示例如下: 输入数据(src0Local): [1 2 3 ... 63 64] 输入数据(src1Local): [1 2 3 ... 63 64] 输出数据(dstLocal): [2 un 6 ... 126 undefined]mask过程如下:
mask={6148914691236517205, 0}(注:6,148,914,691,236,517,205表示64位二进制数0b010101....01)

