均匀量化
如果均匀量化后的模型精度无法满足要求,则需要进行量化感知训练或基于精度的自动量化或手工调优。
均匀量化支持量化的层以及约束如下,量化示例请参见获取更多样例。
量化方式 |
支持的层类型 |
约束 |
|---|---|---|
均匀量化 |
InnerProduct:全连接层 |
transpose属性为false,axis为1 |
Convolution:卷积层 |
filter维度为4 |
|
Deconvolution:反卷积层 |
dilation为1、filter维度为4 |
|
Pooling:平均下采样层 |
下采样方式为AVE,且非global pooling |
接口调用流程
均匀量化接口调用流程如图1所示,均匀量化不支持多个GPU同时运行。

- 用户首先构造Caffe的原始模型,然后使用create_quant_config生成量化配置文件。
- 根据Caffe模型和量化配置文件,调用init接口,初始化工具,配置量化因子存储文件,将模型解析为图结构graph。
- 调用quantize_model接口对原始Caffe模型的图结构graph进行优化,修改后的图中插入数据量化、权重量化等相关算子,用于计算量化相关参数。
- 用户使用3输出的修改后的模型,借助AMCT提供的数据集和校准集,在Caffe环境中进行inference,可以得到量化因子。
其中数据集用于在Caffe环境中对模型进行推理时,测试量化数据的精度;校准集用来产生量化因子,保证精度。
- 最后用户可以调用save_model接口,插入AscendQuant、AscendDequant等量化算子,保存量化模型:包括可在Caffe环境中进行精度仿真的模型文件和权重文件,以及可部署在昇腾AI处理器的模型文件和权重文件。
- 精度仿真模型文件:文件名中包含fake_quant,模型可在Caffe环境下做推理实现量化精度仿真。
fake_quant模型主要用于验证量化后模型的精度,可以在Caffe框架下运行。进行前向推理的计算过程中,在fake_quant模型中对卷积层等的输入数据和权重进行了量化反量化的操作,来模拟量化后的计算结果,从而快速验证量化后模型的精度。如下图所示,Quant层、Convolution卷积层和DeQuant层之间的数据都是Float32数据类型的,其中Quant层将数据量化到INT8又反量化为Float32,权重也是量化到INT8又反量化为Float32,实际卷积层的计算是基于Float32数据类型的,该模型用于在Caffe框架验证量化后模型的精度,不能够用于ATC工具转换成om模型。图2 fake_quant模型

- 部署模型文件:文件名中包含deploy,模型经过ATC工具转换后可部署到昇腾AI处理器上。
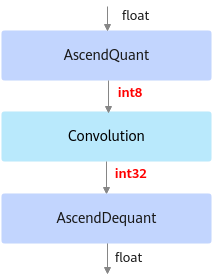
deploy模型由于已经将权重等转换成为了INT8, INT32类型, 因此不能在Caffe框架上执行推理计算。如下图所示,deploy模型的AscendQuant层将Float32的输入数据量化为INT8,作为卷积层的输入,权重也是使用INT8数据类型作为计算,在deploy模型中的卷积层的计算是基于INT8,INT32数据类型的,输出为INT32数据类型经过AscendDequant层转换成Float32数据类型传输给下一个网络层。图3 deploy模型
- 精度仿真模型文件:文件名中包含fake_quant,模型可在Caffe环境下做推理实现量化精度仿真。
调用示例
本章节详细给出训练后量化的模板代码解析说明,通过解读该代码,用户可以详细了解AMCT的工作流程以及原理,方便用户基于已有模板代码进行修改,以便适配其他网络模型的量化。
用户可以参见resnet50>执行均匀量化获取本章节的sample示例代码。训练后量化主要包括如下几个步骤:
- 准备训练好的模型和数据集。
- 在原始Caffe环境中验证模型精度以及环境是否正常。
- 编写训练后量化脚本调用AMCTAPI。
- 执行训练后量化脚本。
- 在原始Caffe环境中验证量化后仿真模型精度。
如下流程详细演示如何编写脚本调用AMCTAPI进行模型量化。

- 如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
- 如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
- 导入AMCT包,并通过环境变量设置日志级别。
1import amct_caffe as amct
- 设置运行设备模式。
AMCT支持CPU或GPU运行模式,所使用的API分别是set_cpu_mode和set_gpu_mode,其中GPU模式与Caffe框架相关,在此模式下,多GPU device的选择是通过Caffe的API caffe.set_mode_gpu()和caffe.set_device(args.gpu_id)来实现的,因此需要先配置Caffe的运行设备模式,再配置AMCT的设备模式。另外因为此处已经指定了运行设备,模型推理函数中无需再次配置运行设备,代码样例如下:
1 2 3 4 5 6
if args.gpu_id is not None and not args.cpu_mode: caffe.set_mode_gpu() caffe.set_device(args.gpu_id) amct.set_gpu_mode() else: caffe.set_mode_cpu()
- (可选,由用户补充处理)在Caffe原始环境中验证推理脚本及环境。建议首先运行下Caffe框架下原始模型推理,验证推理脚本及环境是否正常:
1 2 3 4 5
# Run original model without quantize test if args.pre_test: run_caffe_model(args.model_file, args.weights_file, args.iterations) print('[INFO]Run %s without quantize success!' %(args.model_name)) return
- 调用AMCT,量化模型。
- 解析用户模型,生成全量量化配置文件。
有两种方法生成量化配置文件:
- 通过简易配置文件生成,则需要指定config_defination参数的输入,其余入参将无效,可以不用输入。
- 使用API入参指定量化参数skip_layers、batch_num,activation_offset来生成量化配置文件,默认为API方式。代码样例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Generate quantize configurations config_json_file = 'tmp/config.json' batch_num = 2 if args.cfg_define is not None: amct.create_quant_config(config_json_file, args.model_file, args.weights_file, config_defination=args.cfg_define) else: skip_layers = [] amct.create_quant_config(config_json_file, args.model_file, args.weights_file, skip_layers, batch_num)
- 初始化AMCT,读取用户全量量化配置文件、解析用户模型文件、生成用户内部修改模型的Graph IR。
1 2 3 4 5 6
# Phase0: Init amct task scale_offset_record_file = 'tmp/scale_offset_record.txt' graph = amct.init(config_json_file, args.model_file, args.weights_file, scale_offset_record_file)
- 执行图融合、执行权重离线量化以及插入数据量化层得到校准模型,从而在后续calibration推理过程中执行数据量化动作。
1 2 3 4 5
# Phase1: Do conv+bn+scale fusion, weights calibration and fake # quantize, insert data-quantize layer modified_model_file = 'tmp/modified_model.prototxt' modified_weights_file = 'tmp/modified_model.caffemodel' amct.quantize_model(graph, modified_model_file, modified_weights_file)
- (由用户补充处理)执行校准模型推理,完成数据量化。
该步骤所需要的推理iterations数量需要大于等于设置用于数据量化的batch_num参数。
1 2
# Phase2: run caffe model to do activation calibration run_caffe_model(modified_model_file, modified_weights_file, batch_num)
校准执行过程中提示“IfmrQuantWithOffset scale is illegal",则请参见校准执行过程中提示“IfmrQuantCalibration with offset scale is illegal"或“ IfmrQuantCalibration without offset scale is illegal”处理。
- 保存量化模型。
根据量化因子以及修改后的图结构,调用save_model接口,插入AscendQuant、AscendDequant等算子,并保存得到最终的量化部署模型(deploy)和量化仿真模型(fake_quant)。
1 2 3 4
# Phase3: save final model, one for caffe do fake quant test, one # deploy model for ATC result_path = 'results/%s' %(args.model_name) amct.save_model(graph, 'Both', result_path)
如果保存模型时,提示Error: Cannot find scale_d of layer '**' in record file信息,则请参见量化执行过程中提示“Check scale and offset record file ***_record.txt failed”处理。
- 解析用户模型,生成全量量化配置文件。
- (可选,由用户补充处理)执行量化仿真模型(fake_quant)推理,测试量化后模型精度。
1 2 3 4 5
# Phase4: if need test quantized model, uncomment to do final fake quant # model test. fake_quant_model = 'results/{0}_fake_quant_model.prototxt'.format(args.model_name) fake_quant_weights = 'results/{0}_fake_quant_weights.caffemodel'.format(args.model_name) run_caffe_model(fake_quant_model, fake_quant_weights, args.iterations)
如果用户想借助上述sample代码,量化自己的模型,则需要参见如下步骤修改部分代码:
- 修改执行入参代码。
用于传入AMCT所使用的的执行入参(该步骤非必须,用户可使用任意方式实现类似功能,也可以直接将参数写到sample样例代码里面)。代码样例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
class Args(object): """struct for Args""" def __init__(self): self.model_name = '' # Caffe model name as prefix to save model self.model_file = '' # user caffe model txt define file self.weights_file = '' # user caffe model binary weights file self.cpu = True # If True, force to CPU mode, else set to False self.gpu_id = 0 # Set the gpu id to use self.pre_test = False # Set true to run original model test, set # False to run quantize with amct_caffe tool self.iterations = 5 # Iteration to run caffe model self.cfg_define = None # If None use args = Args() #############################user modified start######################### """User set basic info to use amct_caffe tool """ # e.g. args.model_name = 'ResNet50' args.model_file = 'pre_model/ResNet-50-deploy.prototxt' args.weights_file = 'pre_model/ResNet-50-model.caffemodel' args.cpu = True args.gpu_id = None args.pre_test = False args.iterations = 5 args.cfg_define = None #############################user modified end###########################
- 修改执行Caffe模型推理的代码:
代码样例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
def run_caffe_model(model_file, weights_file, iterations): """run caffe model forward""" net = caffe.Net(model_file, weights_file, caffe.TEST) #############################user modified start######################### """User modified to execute caffe model forward """ # # e.g. # for iter_num in range(iterations): # data = get_data() # forward_kwargs = {'data': data} # blobs_out = net.forward(**forward_kwargs) # # if have label and need check network forward result # post_process(blobs_out) # return #############################user modified end###########################
代码解析如下,需要用户根据具体业务网络实现对传入模型的推理工作:
- 加载传入模型文件,得到Caffe Net示例(推理时设置phase为caffe.TEST):
1net = caffe.Net(model_file, weights_file, caffe.TEST)
- 根据入参的iterations来循环执行指定次数推理。
- 获取每次推理所需要的网络数据,需要根据具体业务网络完成数据预处理操作(例如ResNet50,一般需要将YUV图片转换为RGB,然后缩放到224尺寸,再减去各通道均值);然后通过字典的形式,根据网络输入的blob名称来构建相应的输入,如果有多个输入,则分别按照key(blob名称):value(numpy数组)的格式构建相应输入:
1 2
data = get_data() forward_kwargs = {'data': data}
- 执行一次网络的前向推理,并获取网络的输出:
1blobs_out = net.forward(**forward_kwargs)
- Caffe执行Net的输出blobs_out也是以字典格式存储的输出结果,例如{'prob1': blob1, 'prob2':blob2},如果要获取输出,可直接按照指定的blob名称获取对应的blob数据结构。
- (可选)如果用户需要测试网络的输出,可按上述形式获取对应的数据,然后计算分类或者检测结果等;该步骤非AMCT需要,AMCT仅需执行网络推理拿到所有网络中间层数据即可,对于网络的最终计算结果用户可自行选择是否需要进行后处理。
1post_process(blobs_out)
- 加载传入模型文件,得到Caffe Net示例(推理时设置phase为caffe.TEST):
