ATC工具介绍
ATC简介
昇腾张量编译器(Ascend Tensor Compiler,简称ATC)是异构计算架构CANN体系下的模型转换工具, 它可以将开源框架的网络模型以及Ascend IR定义的单算子描述文件(json格式)转换为昇腾AI处理器支持的.om格式离线模型。其功能架构如图1所示。
模型转换过程中,ATC会进行算子调度优化、权重数据重排、内存使用优化等具体操作,对原始的深度学习模型进行进一步的调优,从而满足部署场景下的高性能需求,使其能够高效执行在昇腾AI处理器上。

其中:
- 开源框架网络模型场景:
- 开源框架网络模型经过Parser解析后,转换为中间态IR Graph。
- 中间态IR经过图准备、图拆分、图优化、图编译等一系列操作后,转成适配昇腾AI处理器的离线模型(此处图指网络模型拓扑图)。
- 转换后的离线模型上传到板端环境,通过AscendCL接口加载模型文件实现推理过程,详细流程请参见模型推理。
用户也可以将开源框架网络模型转换后的离线模型转成json文件,方便查看相关参数;也可以直接将开源框架网络模型通过ATC工具转成json文件,查看相关参数。
- 单算子描述文件场景下:
Ascend IR定义的单算子描述文件(json格式)通过ATC工具进行单算子编译后,转成适配昇腾AI处理器的单算子离线模型,然后上传到板端环境,通过AscendCL接口加载单算子模型文件用于验证单算子功能,详细流程请参见单算子调用。
模型转换交互流程
下面以开源框架网络模型转换为.om离线模型为例,详细介绍模型转换过程中与周边模块的交互流程。
根据网络模型中算子计算单元的不同,分为TBE(Tensor Boost Engine)算子、AI CPU算子,TBE算子在AI Core上运行,AI CPU算子在AI CPU上运行。在TBE算子、AI CPU算子的模型转换交互流程中,虽然都涉及图准备、图拆分、图优化、图编译等节点,但由于两者的计算单元不同,因此涉及交互的内部模块也有所不同,请参见下图。关于算子类型、基本概念等详细介绍请参见《TBE&AI CPU算子开发指南》。
- TBE算子模型转换交互流程
图2 TBE算子模型转换交互流程
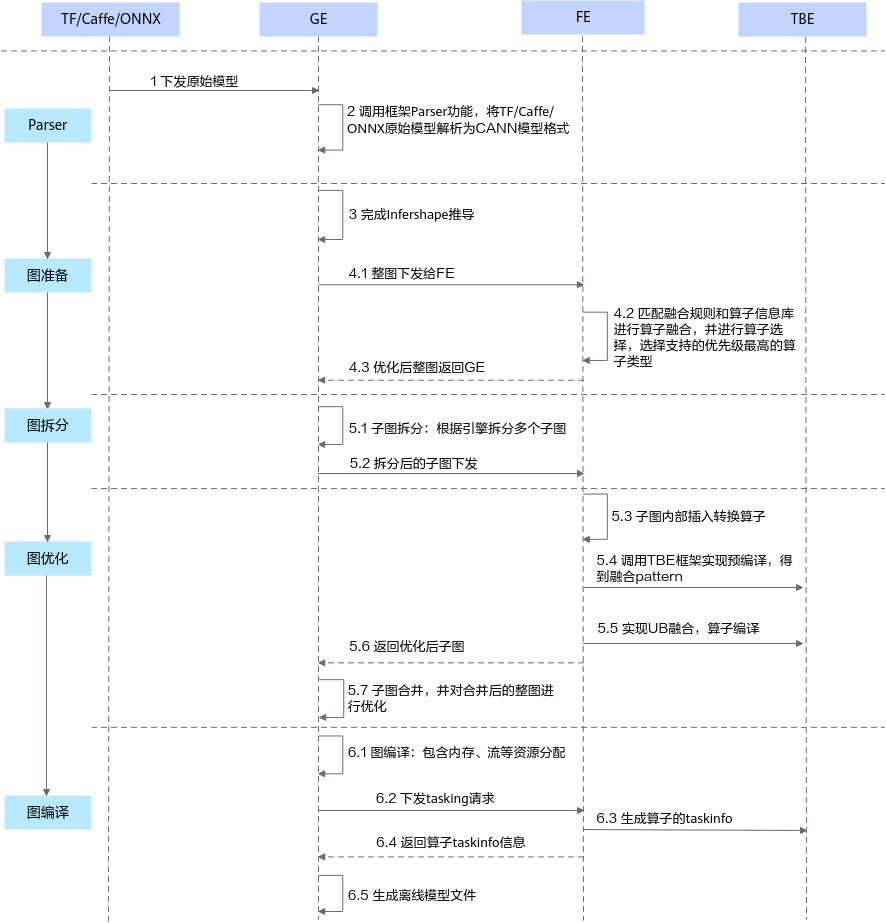
- 调用框架Parser功能,将主流框架的模型格式转换成CANN模型格式。
- 图准备阶段:该阶段会完成原图优化以及Infershape推导(设置算子输出的shape和dtype)等功能。
原图优化时:GE(Graph Engine,基于昇腾AI软件栈对不同的机器学习框架提供统一的IR接口,对接上层网络模型框架,例如Tensorflow、PyTorch等,GE的主要功能包括图准备、图拆分、图优化、图编译、图加载、图执行和图管理等。)向FE发送图优化请求,并将图下发给FE,FE匹配融合规则进行图融合,并进行算子选择,选择优先级最高的算子类型进行算子匹配,最后将优化后的整图返回给GE。
- 图拆分阶段:GE根据图中数据将图拆分为多个子图。
- 图优化阶段:GE将拆分后的子图下发给FE,FE首先在子图内部插入转换算子,然后按照当前子图流程进行TBE算子预编译,对TBE算子进行UB(Unified Buffer)融合,并根据算子信息库中算子信息找到算子实现将其编译成算子kernel(算子的*.o与*.json),最后将优化后子图返回给GE。
优化后的子图合并为整图,再进行整图优化。
- 图编译阶段:GE进行图编译,包含内存分配、流资源分配等,并向FE发送tasking请求,FE返回算子的taskinfo信息给GE,图编译完成之后生成适配昇腾AI处理器的离线模型文件(*.om)。
- AI CPU算子模型转换交互流程
图3 AI CPU算子模型转换交互流程
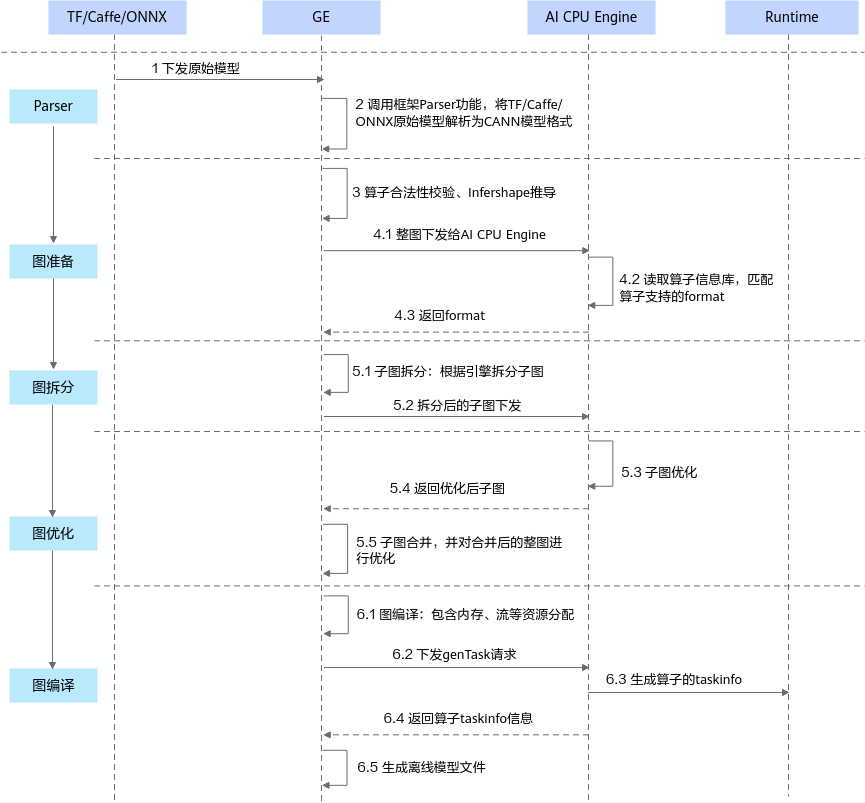
- 调用框架Parser功能,将主流框架的模型格式转换成CANN模型格式。
- 图准备阶段:该阶段会完成算子基本参数校验以及Infershape推导(设置算子输出的shape和dtype)等功能。
另外,GE将整图下发给AI CPU Engine,AI CPU Engine读取算子信息库,匹配算子支持的format,并将format返回给GE。
- 图拆分阶段:GE根据图中数据将图拆分为多个子图。
- 图优化阶段:GE将拆分后的子图下发给AI CPU Engine,AI CPU Engine进行子图优化,并将优化后子图返回给GE。
- 图编译阶段:GE进行图编译,包含内存分配、流资源分配等,并向AI CPU Engine发送genTask请求,AI CPU Engine返回算子的taskinfo信息给GE,图编译完成之后生成适配昇腾AI处理器的离线模型文件(*.om)。