切片数据搬运
函数功能
切片数据搬运,主要适用于非连续vector数据搬运。
函数原型
- 源操作数为GlobalTensor,目的操作数为LocalTensor
1 2
template <typename T> __aicore__ inline void DataCopy(const LocalTensor<T>& dstLocal, const GlobalTensor<T>& srcGlobal, const SliceInfo dstSliceInfo[], const SliceInfo srcSliceInfo[], const uint32_t dimValue = 1)
该原型接口支持的数据通路和数据类型如下所示:
表1 数据通路和数据类型(源操作数为GlobalTensor,目的操作数为LocalTensor) 支持型号
数据通路
源操作数和目的操作数的数据类型 (两者保持一致)
Atlas推理系列产品AI Core
GM -> VECIN
int8_t / uint8_t / int16_t / uint16_t / int32_t / uint32_t / half / float
Atlas A2训练系列产品/Atlas 800I A2推理产品
GM -> VECIN
int8_t / uint8_t / int16_t / uint16_t / int32_t / uint32_t / half / bfloat16_t / float
- 源操作数为LocalTensor,目的操作数为GlobalTensor
1 2
template <typename T> __aicore__ inline void DataCopy(const GlobalTensor<T> &dstGlobal, const LocalTensor<T> &srcLocal, const SliceInfo dstSliceInfo[], const SliceInfo srcSliceInfo[], const uint32_t dimValue = 1)
该原型接口支持的数据通路和数据类型如下所示:
表2 数据通路和数据类型(源操作数为LocalTensor,目的操作数为GlobalTensor) 支持型号
数据通路
源操作数和目的操作数的数据类型 (两者保持一致)
Atlas推理系列产品AI Core
VECOUT -> GM
int8_t / uint8_t / int16_t / uint16_t / int32_t / uint32_t / half / float
Atlas推理系列产品AI Core
CO2 -> GM
int8_t / uint8_t / int16_t / uint16_t / int32_t / uint32_t / half / float
Atlas A2训练系列产品/Atlas 800I A2推理产品
VECOUT -> GM
int8_t / uint8_t / int16_t / uint16_t / int32_t / uint32_t / half / bfloat16_t / float
参数说明
参数名称 |
输入/输出 |
含义 |
|---|---|---|
dstLocal, dstGlobal |
输出 |
目的操作数,类型为LocalTensor或GlobalTensor。支持的数据类型为:half/int16_t/uint16_t/float/int32_t/uint32_t/int8_t/uint8_t。 |
srcLocal, srcGlobal |
输入 |
源操作数,类型为LocalTensor或GlobalTensor。支持的数据类型为:half/int16_t/uint16_t/float/int32_t/uint32_t/int8_t/uint8_t。 |
srcSliceInfo/dstSliceInfo |
输入 |
目的操作数/源操作数切片信息,SliceInfo类型,SliceInfo具体参数请参考表4。 |
dimValue |
输入 |
操作数维度信息,默认值为1。 |
参数名称 |
含义 |
|---|---|
startIndex |
切片的起始元素位置。 |
endIndex |
切片的终止元素位置。 |
stride |
切片的间隔元素个数。 |
burstLen |
横向切片,每一片数据的长度,仅在维度为1时生效,超出1维的情况下,必须配置为1,不支持配置成其他值。单位为datablock(32B)。比如,srcSliceInfo的List为 {{16, 70, 7, 3, 87}, {0, 2, 1, 1, 3}},{16, 70, 7, 3, 87}表示第一维的切片信息,burstLen设置为3,表示一个切片数据段大小为3个datablock; {0, 2, 1, 1, 3}为第二维的切片信息,burstLen仅能设置为1。 |
shapeValue |
当前维度的原始长度。单位为元素个数。 |
通过具体的示例对上述参数进行解析,示意图如下:
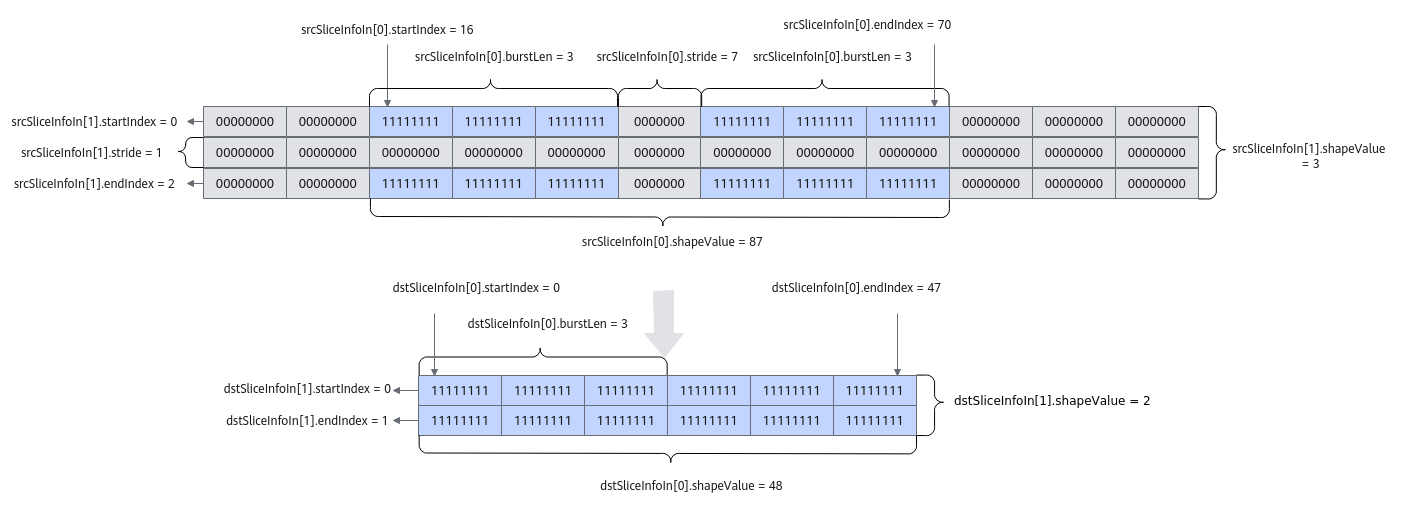
- dimValue为2,表示操作数有2维。
- srcSliceInfo为 {{16, 70, 7, 3, 87}, {0, 2, 1, 1, 3}}
- {16, 70, 7, 3, 87}是针对单独一行, 即从一维的角度来配置,每个元素代表一个数:
startIndex = 16,表示有效数据段从第16个数开始;
endIndex = 70,表示有效数据段到第70个数结束;
stride = 7, 单位为元素个数,表示相邻的2个切片数据段间隔的元素个数,为7个0的间距;
burstLen = 3,单位为32B,表示在这一个有效数据段中,一个切片数据段大小为3个datablock;
shapeValue = 87,表示单独一行的长度,单位为元素个数,即 8 * 10 + 7 = 87个元素。
- {0, 2, 1, 1, 3}是针对多行,即从二维的角度来配置,每个元素代表一行:
endIndex = 2,表示有效数据段到第2行结束;
stride = 1,表示相邻的2个切片数据段中间隔元素为1行;
burstLen = 1,在dimValue > 1时必须填为1;
shapeValue = 3,表明一共有3行。
- {16, 70, 7, 3, 87}是针对单独一行, 即从一维的角度来配置,每个元素代表一个数:
- dstSliceInfo为{{0, 47, 0, 3, 48}, {0, 1, 0, 1, 2}}
- {0, 47, 0, 3, 48}是针对单独一行, 即从一维的角度来配置,每个元素代表一个数:
startIndex = 0,表示有效数据段从第0个数开始;
endIndex = 47,表示有效数据段到第47个数结束;
stride = 0, 单位为元素个数,表示相邻的2个切片数据段间隔的元素个数,为0表示两个切片数据段没有间距;
burstLen = 3,单位为32B,表示在这一个有效数据段中,一个切片数据段大小为3个datablock;
shapeValue = 48,表示单独一行的长度,单位为元素个数,即8 * 6 = 48个元素。
- {0, 1, 0, 1, 2} 是针对多行,即从二维的角度来配置,每个元素代表1行:
endIndex = 1,表示有效数据段到第1行结束;
stride = 0,表示相邻的2个切片数据段没有间隔;
burstLen = 1,在dimValue > 1时必须填为1;
shapeValue = 2,表示一共有2行。
- {0, 47, 0, 3, 48}是针对单独一行, 即从一维的角度来配置,每个元素代表一个数:
支持的型号
Atlas推理系列产品AI Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
注意事项
- 切片数据搬运中的横向burstLen大小设置,需要用户自己通过计算:横向切片元素个数* sizeof(T)/32byte。横向切片元素个数* sizeof(T)的大小必须是32byte的倍数。
- 切片数据搬运中的SliceInfo结构体数组大小和dimValue需要保持一致,并且不超过8。
- 切片数据搬运中的srcSliceInfo数组大小的和dstSliceInfo的大小需要保持一致,两者的结构体中的burstLen需要相等(srcSliceInfo[i].burstLen = dstSliceInfo[i].burstLen)。
- 切片数据搬运对参数有一定要求,建议使用者参考调用示例,并在CPU上仿真结果无误后,再到NPU侧执行。
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | #include "kernel_operator.h" // 本样例中tensor数据类型为float template <typename T> class KernelDataCopySliceGM2UB { public: __aicore__ inline KernelDataCopySliceGM2UB() {} __aicore__ inline void Init(__gm__ uint8_t* dstGm, __gm__ uint8_t* srcGm) { AscendC::SliceInfo srcSliceInfoIn[] = {{16, 70, 7, 3, 87}, {0, 2, 1, 1, 3}};// 如输入数据示例:startIndex为16,endIndex为70,burstLen为3,stride为7, shapeValue为87。 AscendC::SliceInfo dstSliceInfoIn[] = {{0, 47, 0, 3, 48}, {0, 1, 0, 1, 2}};// UB空间相对紧张,建议设置stride为0。 uint32_t dimValueIn = 2; uint32_t dstDataSize = 96; uint32_t srcDataSize = 261; dimValue = dimValueIn; for (uint32_t i = 0; i < dimValueIn; i++) { srcSliceInfo[i].startIndex = srcSliceInfoIn[i].startIndex; srcSliceInfo[i].endIndex = srcSliceInfoIn[i].endIndex; srcSliceInfo[i].stride = srcSliceInfoIn[i].stride; srcSliceInfo[i].burstLen = srcSliceInfoIn[i].burstLen; srcSliceInfo[i].shapeValue = srcSliceInfoIn[i].shapeValue; dstSliceInfo[i].startIndex = dstSliceInfoIn[i].startIndex; dstSliceInfo[i].endIndex = dstSliceInfoIn[i].endIndex; dstSliceInfo[i].stride = dstSliceInfoIn[i].stride; dstSliceInfo[i].burstLen = dstSliceInfoIn[i].burstLen; dstSliceInfo[i].shapeValue = dstSliceInfoIn[i].shapeValue; } srcGlobal.SetGlobalBuffer((__gm__ T *)srcGm); dstGlobal.SetGlobalBuffer((__gm__ T *)dstGm); pipe.InitBuffer(inQueueSrcVecIn, 1, dstDataSize * sizeof(T)); } __aicore__ inline void Process() { CopyIn(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<T> srcLocal = inQueueSrcVecIn.AllocTensor<T>(); AscendC::DataCopy(srcLocal, srcGlobal, dstSliceInfo, srcSliceInfo, dimValue); inQueueSrcVecIn.EnQue(srcLocal); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<T> srcOutLocal = inQueueSrcVecIn.DeQue<T>(); AscendC::DataCopy(dstGlobal, srcOutLocal, dstSliceInfo, dstSliceInfo, dimValue); inQueueSrcVecIn.FreeTensor(srcOutLocal); } private: AscendC::TPipe pipe; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueSrcVecIn; AscendC::GlobalTensor<T> srcGlobal; AscendC::GlobalTensor<T> dstGlobal; AscendC::SliceInfo dstSliceInfo[K_MAX_DIM]; AscendC::SliceInfo srcSliceInfo[K_MAX_DIM]; // K_MAX_DIM = 8 uint32_t dimValue; }; extern "C" __global__ __aicore__ void kernel_data_copy_slice_out2ub(__gm__ uint8_t* src_gm, __gm__ uint8_t* dst_gm) { KernelDataCopySliceGM2UB<TYPE> op; op.Init(dst_gm, src_gm); op.Process(); } |
结果示例请参考图1。