同步控制简介
TQueSync类提供同步控制接口,开发者可以使用这类API来自行完成同步控制。需要注意的是,通常情况下,开发者基于编程模型中介绍的编程模型和范式进行编程时不需要关注同步,编程模型帮助开发者完成了同步控制;使用编程模型和范式是我们推荐的编程方式,自行同步控制可能会带来一定的编程复杂度,不建议开发者使用。TQueSync类接口和同步控制中提供的同步控制接口的区别在于,同步控制中的接口标注为ISASI类别,不能保证跨硬件版本兼容;TQueSync类接口可以保证跨硬件版本兼容。
同步控制简介
介绍同步控制之前需要先回顾一下图1。
AI Core内部的异步并行计算过程:Scalar计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发射给对应单元的指令队列,向量计算单元、矩阵计算单元、数据搬运单元异步的并行执行接收到的指令。该过程可以参考图1中蓝色箭头所示的指令流。
不同的指令间有可能存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar计算单元也会给对应单元下发同步指令。各单元之间的同步过程可以参考图1中的绿色箭头所示的同步信号流。
AI Core内部数据处理的基本过程:DMA搬入单元把数据搬运到Local Memory,Vector/Cube计算单元完成数据计算,并把计算结果写回Local Memory,DMA搬出单元把处理好的数据搬运回Global Memory。该过程可以参考图1中的红色箭头所示的数据流。
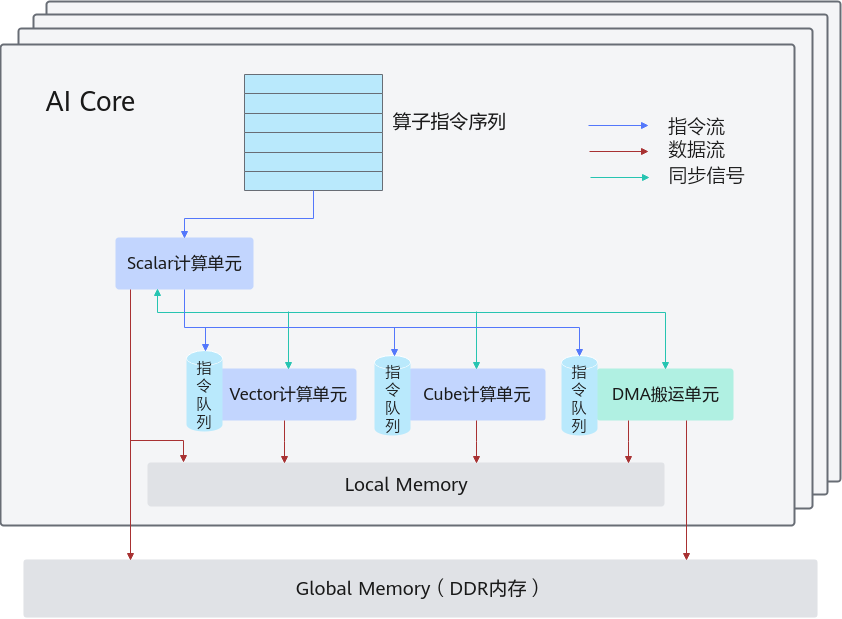
从上图可以了解到AI Core内部的执行单元是异步并行的,在读写Local Memory内存时,可能存在依赖,需要进行同步控制。
下图示例描述了一个常见的Vector计算数据流:先通过DMA执行单元将数据从Global Memory搬入到Local Memory,进行计算,然后再通过DMA执行单元将计算结果从Local Memory搬出到Global Memory。
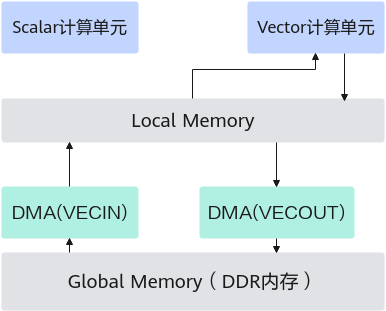
四个执行单元Scalar、Vector、DMA(VECIN)、DMA(VECOUT)并行执行,若访问同一片Local Memory,需要同步机制来控制他们的访问时序:保证先搬入Local Memory后再计算,计算完成后再搬出。
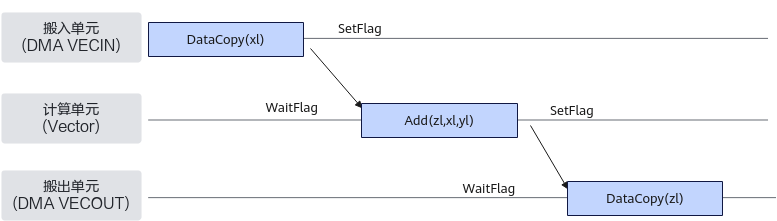
硬件流水类型
什么时候需要开发者手动插入同步
- Vector计算单元
- 单流水同步:PIPE_V由编译器自动完成同步插入, PIPE_MTE2/PIPE_MTE3在搬运地址有重叠的情况下需要开发者插入同步(具体示例请参考注意事项)。
- 多流水同步:PIPE_V、PIPE_MTE2、PIPE_MTE3、PIPE_S之间的多流水同步,都是双向的,如下图所示,黄色线条表示的同步由编译器自动完成同步插入,剩余的同步由Ascend C框架完成。
- Cube计算单元

