GenAttentionMaskOperation
功能
将attentionMask根据每个batch的实际seqlen进行转化,得到结果为一维tensor。
定义
struct GenAttentionMaskParam {
int32_t headNum = 1;
atb::SVector<int32_t> seqLen;
};
参数列表
成员名称 |
类型 |
默认值 |
描述 |
|---|---|---|---|
headNum |
int32_t |
1 |
多头注意力机制的head数。 |
seqLen |
atb::SVector<int32_t> |
- |
存储unpad场景下每个batch实际seqlen的值。元素个数为batchSize,最大为32。 |
输入输出
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
x |
[batchSize, 1, maxSeqLen, maxseqlen] |
float16 |
ND |
输入,用于attentionmask计算的随机矩阵。 |
output |
[nSquareTokens] |
float16 |
ND |
输出,attentionmask计算的结果矩阵。 |
其中nSquareTokens的计算公式为:
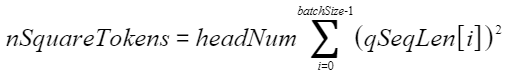
规格约束
- 当前只支持
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 。 - qSeqLen数组长度不超过32,且要求各元素大于0。