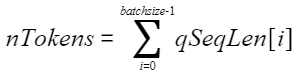RopeGradOperation
功能
旋转位置编码处理的反向。
算子功能实现描述(Python)
训练算子,实现对于旋转位置编码(RoPE)的梯度反向计算,计算流程如下:
def RopeGradCalc(self, in_tensors):
cos_list = [in_tensors[2][:x, :] for x in OP_PARAM['qSeqLen']]
sin_list = [in_tensors[3][:x, :] for x in OP_PARAM['qSeqLen']]
cos = torch.cat(cos_list, dim=0)
sin = torch.cat(sin_list, dim=0)
sin1 = sin[:,:64]
sin2 = sin[:,64:]
rohqgsin = torch.cat((sin2, -sin1), dim=-1)
q_grad = torch.zeros_like(in_tensors[0])
bs = int(in_tensors[0].shape[1] / 128)
for i in range(bs):
q_grad[:, i * 128:(i + 1) * 128] = in_tensors[0][:, i * 128:(i + 1) * 128] * (cos + rohqgsin)
k_grad = torch.zeros_like(in_tensors[1])
for i in range(bs):
k_grad[:,i * 128:(i + 1) * 128] = in_tensors[1][:, i * 128:(i + 1) * 128] *(cos + rohqgsin)
return [q_grad, k_grad]
定义
struct RopeGradParam {
std::vector<int32_t> qSeqLen;
};
参数列表
成员名称 |
类型 |
默认值 |
描述 |
|---|---|---|---|
qSeqLen |
std::vector< int32_t > |
- |
存储unpad场景下每个batch实际seqlen的值。size不能为0。 |
unpad场景:输入序列长度(seq length)是动态的场景下,如果对所有输入序列都按最大长度计算,存在大量冗余计算。Unpad方案是decoder过程序列长度不再按照最大长度计算,而是根据实际的长度进行计算,减少计算量。
输入
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
ropeQ_grad1 |
[nTokens, hiddenSize] |
float16 |
ND |
ropeQ_grad矩阵。 |
ropeQ_grad2 |
[nTokens, hiddenSize] |
float16 |
ND |
ropeQ_grad矩阵。 |
cos |
[maxSeqLen, headDim] |
float16 |
ND |
cos矩阵,maxSeqLen为qSeqLen中的最大元素,headDim为128。 |
sin |
[maxSeqLen, headDim] |
float16 |
ND |
sin矩阵。 |
输出
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
q_grad |
[nTokens, hiddenSize] |
float16 |
ND |
q_grad矩阵。 |
k_grad |
[nTokens, hiddenSize] |
float16 |
ND |
k_grad矩阵。 |