基本概念
本节给出模型压缩过程中用到的概念,并介绍了不同压缩方法的原理。
量化
量化是指对模型的权重(weight)和数据(activation)进行低比特处理,让最终生成的网络模型更加轻量化,从而达到节省网络模型存储空间、降低传输时延、提高计算效率,达到性能提升与优化的目标。
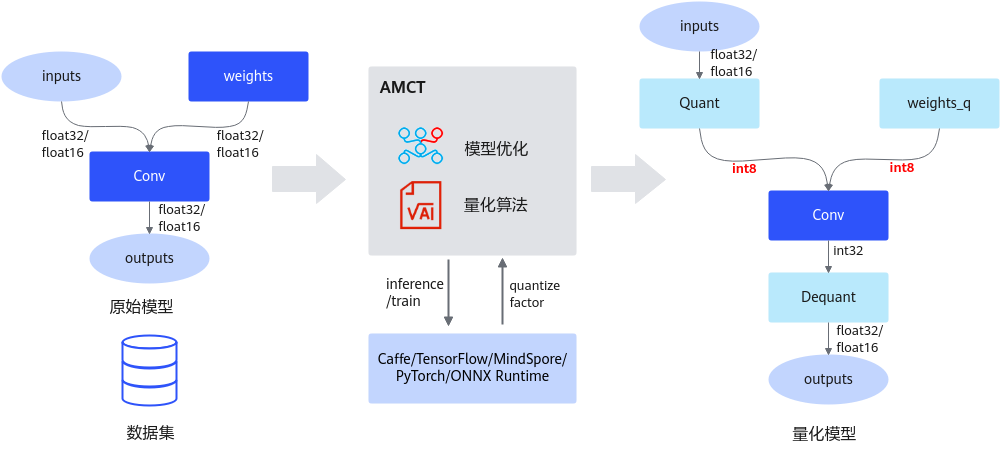
AMCT将量化和模型转换分开,实现对模型中可量化算子的独立量化,并输出量化后的模型。其中量化后的仿真模型可以在CPU或者GPU上运行,完成精度仿真;量化后的部署模型可以部署在昇腾AI处理器上运行,达到提升推理性能的目的。
当前该工具仅支持对float32/float16数据类型的网络模型进行量化(Caffe框架不支持float16类型),以量化到INT8数据类型为例,其运行原理如下图所示。
- 训练后量化
训练后量化是指在模型训练结束之后进行的量化,对训练后模型中的权重由浮点数量化到低比特整数,并通过少量校准数据基于推理过程对数据(activation)进行校准量化,从而尽可能减少量化过程中的精度损失。训练后量化简单易用,只需少量校准数据,适用于追求高易用性和缺乏训练资源的场景。
通常,训练后的模型权重已经确定,因此可以根据权重的数值离线计算得到权重的量化参数。而通常数据是在线输入的,因此无法准确获取数据的数值范围,通常需要一个较小的有代表性的数据集来模拟在线数据的分布,利用该数据集执行前向推理,得到对应的中间浮点结果,并根据这些浮点结果离线计算出数据的量化参数。其原理如下图所示。
图2 训练后量化原理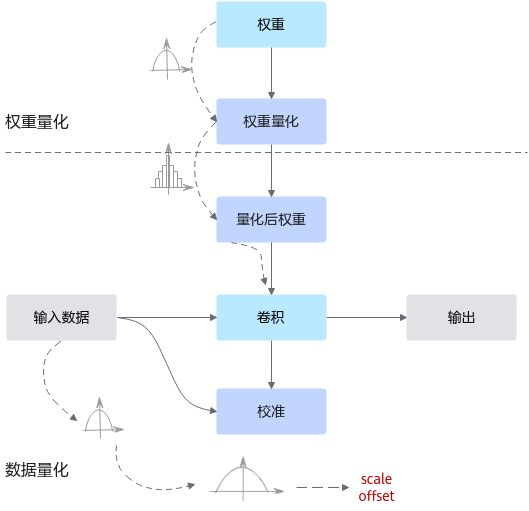
- 量化感知训练
量化感知训练是指在重训练过程中引入量化,通过重训练提高模型对量化效应的能力,从而获得更高的量化模型精度的一种量化方式。量化感知训练借助用户完整训练数据集,在训练过程中引入伪量化的操作(从浮点量化到定点,再还原到浮点的操作),用来模拟前向推理时量化带来的误差,并借助训练让模型权重能更好地适应这种量化的信息损失,从而提升量化精度。
通常,量化感知训练相比训练后量化,精度损失会更小,但主要缺点是整体量化的耗时会更长;此外,量化过程需要的数据会更多,通常是完整训练数据集。
其运行原理如下图所示。
图3 量化感知训练原理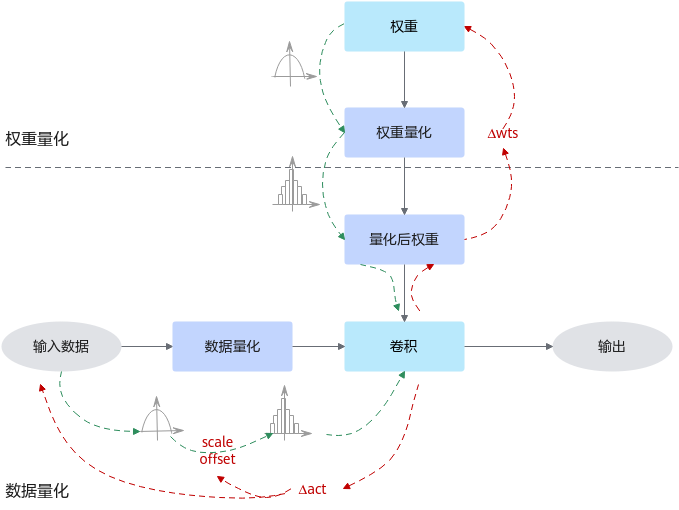
张量分解
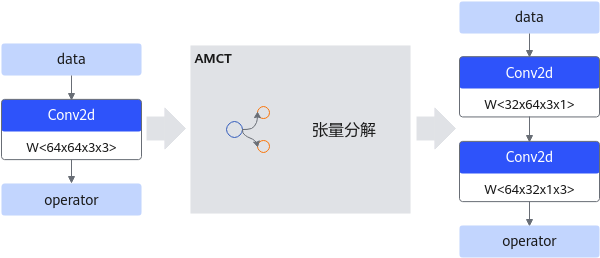
深度学习运算,尤其是CV(计算机视觉)类任务运算,包含大量的卷积运算,而张量分解通过分解卷积核的张量,可以将一个大卷积核分解为两个小卷积核的连乘,即将卷积核分解为低秩的张量,从而降低存储空间和计算量,降低推理开销。
以1个64*64*3*3的卷积分解为32*64*3*1和64*32*1*3的级联卷积为例,可以减少1 - (32*64*3*1 + 64*32*1*3) / 64*64*3*3 = 66.7%的计算量,在计算结果近似的情况下带来更具性价比的性能收益。张量分解运行原理如下图所示(以PyTorch框架为例)。
模型部署优化
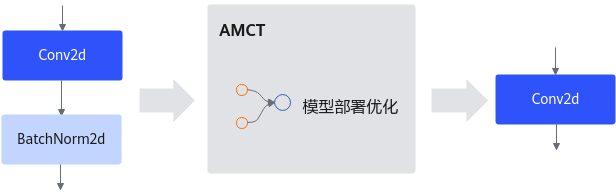
主要为算子融合,是指通过数学等价,将模型中的多个算子运算融合单算子运算,以减少实际前向过程中的运算量,如将卷积层和BN层融合为一个卷积层。
其运行原理如下图所示(以PyTorch框架为例)。
稀疏
稀疏是通过结构剪枝的方式,对模型中的部分算子实现权重的稀疏化,从而得到一个参数量更小、计算量更小的网络模型。AMCT目前有两种稀疏方式:通道稀疏和4选2结构化稀疏。每次只能使能其中一种稀疏方式,即对于同一层可压缩算子,通道稀疏和4选2结构化稀疏不能同时配置。
通道稀疏与4选2结构化稀疏相比,稀疏颗粒度更大,对模型的精度影响也越大,但是能够获取到的性能收益也越大,用户可以根据实际情况选择一种稀疏方式。
- 通道稀疏
通道稀疏基于重训练,通过裁剪网络通道数,在保持网络功能的前提下缩减模型参数量,从而降低整网的计算量。由于通道稀疏本身是依据通道的重要性进行裁剪,会裁剪掉重要性相对较低的通道,但是直接裁剪通道对网络精度影响较大,故裁剪后的模型需要进行重训练,以保证业务精度。通道稀疏的实现通常包括两个步骤:首先是通道选择,需要选择合适的通道组合以保留丰富的信息;然后是重建,需要使用选择的通道对下一层的输出进行重建。通道稀疏原理如下图所示。
图6 通道稀疏详细示意图
- 4选2结构化稀疏
由于硬件约束,Atlas 200/300/500 推理产品、Atlas 推理系列产品、Atlas 训练系列产品不支持4选2结构化稀疏特性:使能后获取不到性能收益。
4选2结构化稀疏基于重训练,在每4个连续的权重中保留2个重要性相对较高的权重,其余权重置0。因为稀疏的粒度较小,因此4选2结构化稀疏可以保留较多重要信息,具有细粒度稀疏的精度优势;同时4选2结构化稀疏在专门设计的硬件上可以降低运算量,具有结构化稀疏的性能优势。与通道稀疏不同的是,4选2稀疏并不改变权重的形状,因此不会影响上层或下层的算子。
原理如下图所示,在cin维度上相邻的4个元素为一组,在每组4个元素中保留绝对值最大的两个元素,如果cin不是4的倍数,填0补齐到4的倍数。
图7 4选2稀疏详细示意图
组合压缩
组合压缩是结合了稀疏和量化的特性,根据配置文件先进行稀疏,然后进行量化;在稀疏时根据相应算法插入稀疏算子,然后量化时,对稀疏后的模型插入数据和权重的量化层和SearchN的层,生成组合压缩模型,以期望得到更高的性能收益。生成组合压缩模型后,对模型进行重训练,保存为既可以进行精度仿真又可以部署的量化模型。
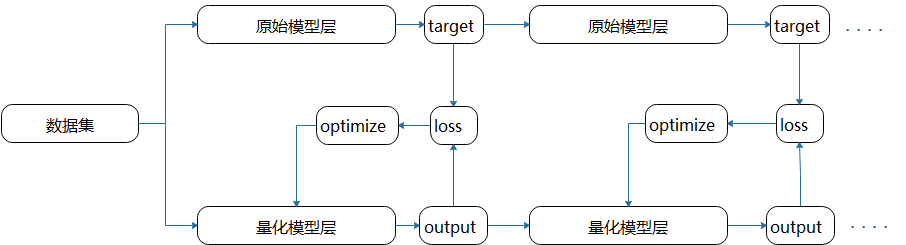
逐层蒸馏
蒸馏量化是模型压缩的一种方法,利用原始模型的监督信息,对量化模型进行训练,以达到更好量化精度的目的。
将预训练好的原始模型作为教师网络,以教师网络层的输出做为目标,对学生网络进行监督训练,通过计算教师网络和学生网络输出预测值的损失,进行梯度更新,最终得到一个更高精度的量化模型。
- 相比训练后量化,知识蒸馏的量化可以取得更好的精度结果。
- 相比量化感知训练,知识蒸馏的量化不需要有标签的数据集,且可以在更短的量化时间内获得不错的量化结果。