加速库通信算子介绍
加速库通信算子集成了高性能集合通信库HCCL(Huawei Collective Communication Library)、小包通信机制作为通信后端,提供单机多卡、多机多卡集合通信原语。HCCL相关文档可以参考《集合通信接口参考》,其中小包通信机制,在小包通信(通信数据量<512k)、开发便捷度、下发开销、同步开销等多个方面展现了巨大优势。
加速库主要支持以下四种通信算子:
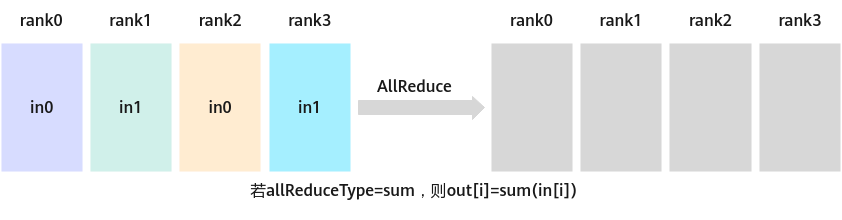
- AllReduceOperation:将多个通信卡上的数据进行计算,支持相加、取最大、最小、相乘四种计算,然后发送到每张卡上。
图1 AllReduce
- BroadcastOperation:将通信主卡上的数据广播到其他每张卡上, 该算子不支持推理系列产品(配置
Atlas 推理系列产品 )。图2 Broadcast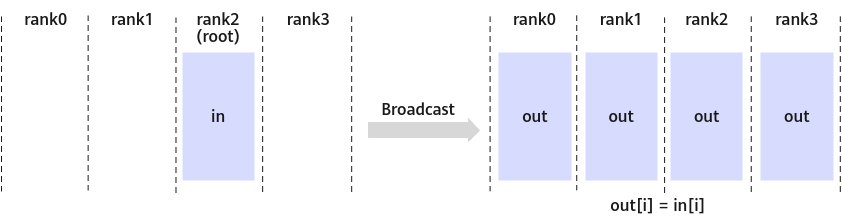
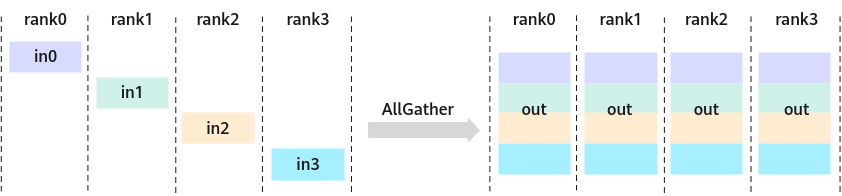
- AllGatherOperation:将多个通信卡上的数据按所属rank号的顺序在第一维进行聚合,然后发送到每张卡上。
图3 AllGather
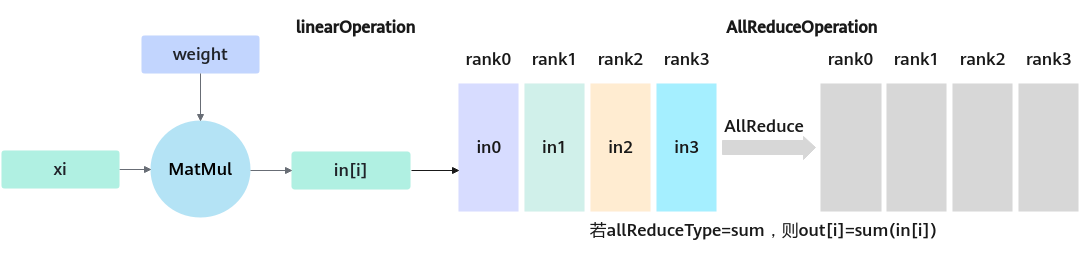
- LinearParallelOperation:典型的张量并行策略会在计算流中插入有依赖的通信任务,使得计算通信任务在调度时必须串行执行,表现为执行通信任务时计算资源闲置(因此被称为“不可掩盖通信”),加速库中计算通信并行LinearParallelOperation集成了通信计算融合算子,通过合理的任务调度和并行执行,使得大部分通信时间都可以被计算任务所掩盖,从而实现了高效的计算与通信并行处理。该算子功能为LinearOperation和通信算子Operation组合,支持三种通信组合,linear+AllReduce,linear+reduce_scatter,AllGather+linear。
图4 LinearParallel linear+AllReduce
加速库通信算子使用流程
加速库的通信算子实现多卡、多机通信主要有两个步骤:初始化通信域(参考《集合通信接口参考》的“通信域管理”章节)和执行通信算子。
通信域是指发生通信的范围,例如想做一次AllReduce,需要在哪些卡之间做,这就是一个通信域。初始化通信域方式主要有两种:
- 加速库内部为用户初始化通信域,每张卡获得各自的通信域句柄去执行算子。
- 用户通过配置“ALLReduceParam”中的“HcclComm”来传入对应通信卡的通信句柄,当用户传入后,加速库内部不会再初始化,“HcclComm”具体含义参考《集合通信接口参考》。
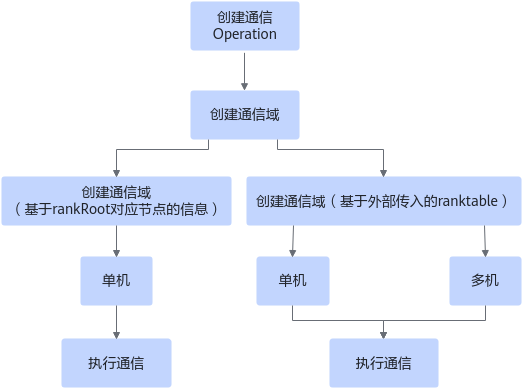
一般来说,主要是由加速库内部为用户初始化通信域,如图5所示有两种方式:
- 基于rankRoot节点的信息创建通信域仅适用于单机场景。
- 基于rankTableFile创建通信域同时适用于单机和多机通信。
用户通过配置不同的Operation Param来创建Operation,就可以通过不同的方式来初始化通信域,初始化通信域成功后,会执行对应的通信算子接口,实现通信。
- 加速库单机二卡多进程通信计算并行用例:以下demo运行方式都与算子使用指导相同。
#include <acl/acl.h> #include <atb/atb_infer.h> #include <iostream> #include <unistd.h> #include <sys/wait.h> void LinearallreduceSample(int rank, int worldsize) { int ret = aclInit(nullptr); //1、设置每个进程对应的deviceId,后续通信算子在该device上执行 int deviceId = rank; aclError status = aclrtSetDevice(deviceId); //2、LinearParallelOperation参数配置,对于多卡多进程通信,需要配置每个进程中算子参数的rank号,按照从0到ranksize-1的顺序为每个算子配置 atb::infer::LinearParallelParam param; param.rank = rank; param.rankRoot = 0; param.rankSize = worldsize; param.commMode = atb::infer::CommMode::COMM_MULTI_PROCESS; param.backend = "hccl"; param.transWeight = false; param.type = atb::infer::LinearParallelParam::ParallelType::LINEAR_ALL_REDUCE; atb::Operation *op = nullptr; atb::Status st = atb::CreateOperation(param, &op); //3、构造其输入输出 atb::Tensor input; input.desc.dtype = ACL_FLOAT16; input.desc.format = ACL_FORMAT_ND; input.desc.shape.dimNum = 2; input.desc.shape.dims[0] = 3; input.desc.shape.dims[1] = 32; input.dataSize = atb::Utils::GetTensorSize(input); status = aclrtMalloc(&input.deviceData, input.dataSize, ACL_MEM_MALLOC_HUGE_FIRST); atb::Tensor weight; weight.desc.dtype = ACL_FLOAT16; weight.desc.format = ACL_FORMAT_ND; weight.desc.shape.dimNum = 2; weight.desc.shape.dims[0] = 32; weight.desc.shape.dims[1] = 5; weight.dataSize = atb::Utils::GetTensorSize(weight); status = aclrtMalloc(&weight.deviceData, weight.dataSize, ACL_MEM_MALLOC_HUGE_FIRST); atb::Tensor output; output.desc.dtype = ACL_FLOAT16; output.desc.format = ACL_FORMAT_ND; output.desc.shape.dimNum = 2; output.desc.shape.dims[0] = 3; output.desc.shape.dims[1] = 5; output.dataSize = atb::Utils::GetTensorSize(output); status = aclrtMalloc(&output.deviceData, output.dataSize, ACL_MEM_MALLOC_HUGE_FIRST); atb::VariantPack variantPack; variantPack.inTensors = { input, weight }; variantPack.outTensors = { output }; // 4、算子准备与执行,与单算子准备执行流程相同,区别在于通信算子需要初始化通信域成功才会执行。 atb::Context *context = nullptr; st = atb::CreateContext(&context); aclrtStream stream = nullptr; status = aclrtCreateStream(&stream); context->SetExecuteStream(stream); uint64_t workspaceSize = 0; st = op->Setup(variantPack, workspaceSize, context); void *workspace = nullptr; if (workspaceSize > 0) { status = aclrtMalloc(&workspace, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST); } st = op->Execute(variantPack, (uint8_t *)workspace, workspaceSize, context); std::cout << "rank: " << rank << " executed END." << std::endl; //5、资源释放,下面用例均相同 status = aclrtDestroyStream(stream); // 销毁stream status = aclrtFree(workspace); // 销毁workspace st = atb::DestroyOperation(op); // 销毁op对象 st = atb::DestroyContext(context); // 销毁context // 下面代码为释放Tensor的示例代码,实际使用时需释放VariantPack中的所有 Tensor status = aclrtFree(tensor.deviceData); tensor.deviceData = nullptr; tensor.dataSize = 0; aclFinalize(); } int main(int argc, const char *argv[]) { // 多进程两卡通信 const int worldsize = 2; for (int i = 0; i < worldsize; ++i) { pid_t pid = fork(); if (pid == 0) { LinearallreduceSample(i, worldsize); return 0; } else if (pid < 0) { std::cerr << "Failed to create child process." << std::endl; return 1; } } for (int i = 0; i < worldsize; ++i) { wait(NULL); } std::cout << "The communication operator is successfully executed. Parent process exits." << std::endl; return 0; } - 加速库多机通信,以两机四卡为例:
对于多机通信,需要配置rankTableFile(当前只支持通信backend为“hccl”),rankTableFile是一个用于描述参与集合通信集群信息的json文件,包括通信Server,Device等的IP、ID信息,每张卡的rank号由用户传入的rankTableFile中rank_id标识,详细配置参考以下代码。
{ "status":"completed", // ranktable可用标识,completed为可用 "version":"1.0", // ranktable模板版本信息,当前必须为"1.0" "server_count":"2", // AI Server数目,此例中为2机通信 "server_list": [ { "device":[ // AI Server中的Device列表 { "device_id":"0", // 处理器HDC通道号 "device_ip":"192.168.1.8", // 处理器真实网卡IP "rank_id":"0" // rank的标识,rankID从0开始 }, { "device_id":"1", "device_ip":"192.168.1.9", "rank_id":"1" } ], "server_id":"10.0.0.10" //AI Server标识,以点分十进制表示IP字符串 }, { "device": [ { "device_id": "0", "device_ip": "192.168.1.10", "rank_id": "2" }, { "device_id": "1", "device_ip": "192.168.1.11", "rank_id": "3" } ], "server_id": "10.0.0.11" } ] }加速库通信算子多机使用流程与单机使用流程基本相同,只需要在通信的机器中都开启多个进程,以下只给出与加速库单机二卡多进程通信计算并行用例中第一点和第二点的配置区别描述:
//1、根据配置的ranktable中的device_id设置每个进程对应的deviceId int deviceId = rank; aclError status = aclrtSetDevice(deviceId);
//2、用户传入配置好的rankTableFile文件路径,根据ranktable的rank_id来设置多机不同进程的rank号 atb::infer::LinearParallelParam param; param.rankTableFile = "/demo/ranktable.json"; param.rank = rank; param.commMode = atb::infer::CommMode::COMM_MULTI_PROCESS; param.backend = "hccl"; param.transWeight = true; param.type = atb::infer::LinearParallelParam::ParallelType::LINEAR_ALL_REDUCE; atb::Operation *op = nullptr; atb::Status st = atb::CreateOperation(param, &op);
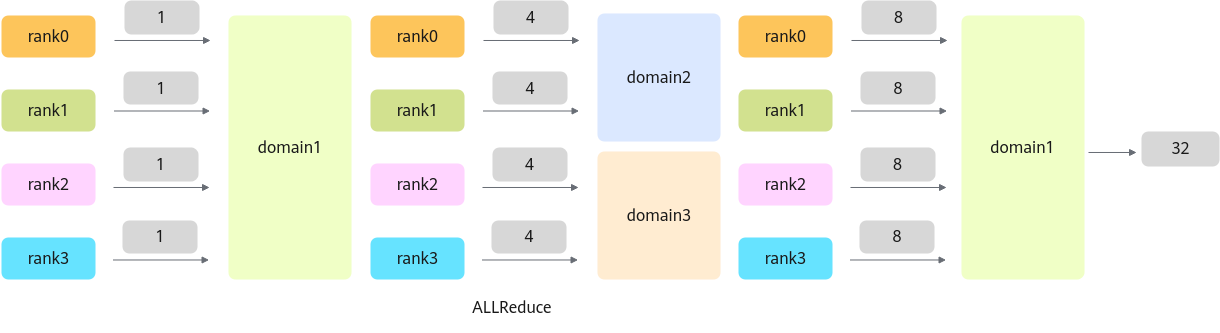
调用通信算子的时候会指定在哪个通信域进行通信,commDomain是通信域名标识,如果构造AllReduceOperation参数使用默认值,则通信算子初始化通信域一次后,后续执行多次通信算子都只在同一个通信域进行通信;如果用户创建多个AllReduceOperation并给不同的AllReduceOperation参数配置不同的commDomain通信域名就可以让通信算子分别处于不同的通信域中并行通信,多个通信域后续也可以复用。
图6是在三个通信域内四卡做三次Allreduce的样例,输入为1,输出结果为32。
/*
* Copyright (c) Huawei Technologies Co., Ltd. 2020-2020. All rights reserved.
*/
#include <acl/acl.h>
#include <atb/atb_infer.h>
#include <iostream>
#include <unistd.h>
#include <sys/wait.h>
void ExcuteImpl(atb::Operation *op, atb::VariantPack variantPack, atb::Context *context)
{
uint64_t workspaceSize = 0;
atb::Status st = op->Setup(variantPack, workspaceSize, context);
void *workspace = nullptr;
if (workspaceSize > 0) {
aclError status = aclrtMalloc(&workspace, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
}
st = op->Execute(variantPack, (uint8_t *)workspace, workspaceSize, context);
if (workspace) {
st = aclrtFree(workspace); // 销毁workspace
}
}
void AllReduceSample(int rank, int worldsize)
{
int ret = aclInit(nullptr);
int deviceId = rank;
aclError status = aclrtSetDevice(deviceId);
atb::Context *context = nullptr;
atb::Status st = atb::CreateContext(&context);
aclrtStream stream = nullptr;
status = aclrtCreateStream(&stream);
context->SetExecuteStream(stream);
atb::Tensor input;
input.desc.dtype = ACL_FLOAT16;
input.desc.format = ACL_FORMAT_ND;
input.desc.shape.dimNum = 2;
input.desc.shape.dims[0] = 3;
input.desc.shape.dims[1] = 5;
input.dataSize = atb::Utils::GetTensorSize(input);
status = aclrtMalloc(&input.deviceData, input.dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
atb::SVector<atb::Tensor> outputlist;
for (int i = 0; i < 3; i++) {
atb::Tensor output;
output.desc.dtype = ACL_FLOAT16;
output.desc.format = ACL_FORMAT_ND;
output.desc.shape.dimNum = 2;
output.desc.shape.dims[0] = 3;
output.desc.shape.dims[1] = 5;
output.dataSize = atb::Utils::GetTensorSize(output);
status = aclrtMalloc(&output.deviceData, output.dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
outputlist.push_back(output);
}
// 1、rank 0,1,2,3在通信域atb1,,ranksize为4
atb::infer::AllReduceParam param;
param.rank = rank;
param.rankRoot = 0;
param.rankSize = worldsize;
param.backend = "hccl";
param.commDomain = "atb1";
atb::Operation *op1 = nullptr;
st = atb::CreateOperation(param, &op1);
atb::VariantPack variantPack1;
variantPack1.inTensors = { input };
variantPack1.outTensors = { outputlist[0] };
ExcuteImpl(op1, variantPack1, context);
std::cout << "rank: " << rank << " executed END." << std::endl;
atb::VariantPack variantPack2;
variantPack2.inTensors = { outputlist[0] };
variantPack2.outTensors = { outputlist[1] };
// 2、rank 0,1在通信域atb2,ranksize为2
if (rank == 0 || rank == 1) {
param.rank = rank;
param.rankSize = 2;
param.commDomain = "atb2";
atb::Operation *op2 = nullptr;
atb::Status st = atb::CreateOperation(param, &op2);
ExcuteImpl(op2, variantPack2, context);
std::cout << "rank: " << rank << " executed END." << std::endl;
} // 3、rank 2,3在通信域atb3,ranksize为2
else if (rank == 2 || rank == 3) {
param.rank = rank - 2;
param.rankSize = 2;
param.commDomain = "atb3";
atb::Operation *op2 = nullptr;
atb::Status st = atb::CreateOperation(param, &op2);
ExcuteImpl(op2, variantPack2, context);
std::cout << "rank: " << rank << " executed END." << std::endl;
}
// 4、rank 0,1,2,3在通信域atb1
param.rank = rank;
param.rankSize = 4;
param.commDomain = "atb1";
atb::VariantPack variantPack3;
variantPack3.inTensors = { outputlist[1] };
variantPack3.outTensors = { outputlist[2] };
ExcuteImpl(op1, variantPack3, context);
std::cout << "rank: " << rank << " executed END." << std::endl;
//5、资源释放
status = aclrtDestroyStream(stream); // 销毁stream
st = atb::DestroyOperation(op1); // 销毁op对象
st = atb::DestroyOperation(op2); // 销毁op对象
st = atb::DestroyContext(context); // 销毁context
aclFinalize();
}
int main(int argc, const char *argv[])
{
// 多进程两卡通信
const int worldsize = 4;
for (int i = 0; i < worldsize; ++i) {
pid_t pid = fork();
if (pid == 0) {
AllReduceSample(i, worldsize);
return 0;
} else if (pid < 0) {
std::cerr << "Failed to create child process." << std::endl;
return 1;
}
}
for (int i = 0; i < worldsize; ++i) {
wait(NULL);
}
std::cout << "The communication operator is successfully executed. Parent process exits." << std::endl;
return 0;
}