基本介绍
使用前须知
使用场景
对于纯静态shape网络或者shape变化较少的动态shape网络,如果您想快速提升网络模型执行性能,可以在网络部署时通过算子编译工具(op_compiler)编译生成静态Kernel包来提升算子调用性能。
调优原理
静态Kernel编译是指在编译时指定算子shape大小,运行时不需要指定shape大小。算子编译工具根据输入的算子信息统计文件,得到确定的shape信息,针对每一个shape都编译出一个算子二进制,从而实现提升算子执行效率和性能的目的。
静态Kernel编译的优势如下:
- 编译时已知所有tensor的大小,存储空间利用率高。
- 编译时可以针对实际的shape大小做针对性优化。
- AI处理器擅长并行指令运行,不擅长逻辑计算,如果有太多的Scalar操作可能会打断并行指令的运行,从而导致性能下降。静态编译可以在编译时完成标量的计算,一定程度上可以提升性能。
- 编译工具在编译时知道确切的操作数据大小,不会额外插入同步,不会导致并行执行多个指令变成串行执行,一定程度上可以提升性能。
整体流程
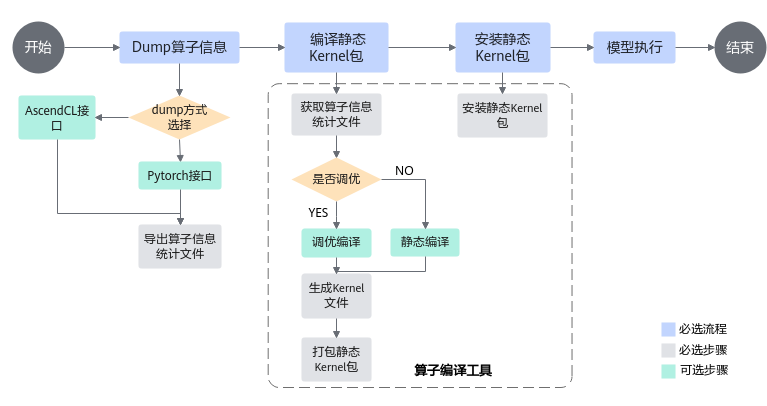
通过编译静态Kernel提升网络模型中算子执行性能的基本流程如图1所示,整个调优步骤如下:

父主题: 使用静态Kernel提升模型执行性能