'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
动态扩容模式
TensorFlow对Embedding的支持是通过变量实现的,用户需要预估每个表的大小,再通过create_table接口创建变量。Embedding表的大小在一开始就确认,后期无法扩大或者减小,这可能会导致显存的浪费或者空间不足。在推荐场景下,多个稀疏表的大小无法预估,为更好的适配用户场景及需求,增加HBM稀疏表自动扩容功能,即显存随着模型训练增长。
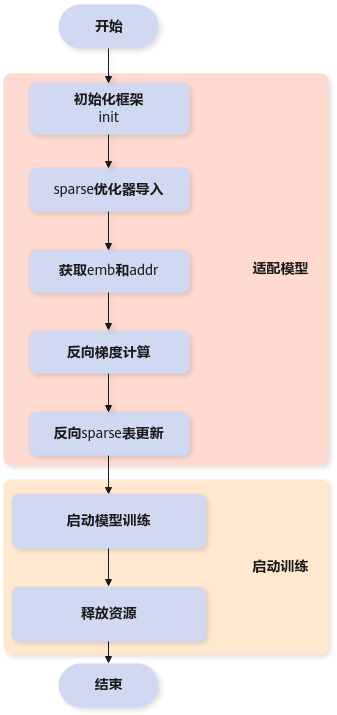
适配模型
关键步骤操作参考如下。
- 初始化框架。
调用init接口,设置参数use_dynamic_expansion = True表示启用动态扩容功能,该参数默认为“False”。
- 稀疏优化器导入。
调用mx_rec.optimizers包中对应优化器的create_hash_optimizer_by_address接口来创建稀疏表sparse_optimizer。具体可用优化器参考如下。
- 获取嵌入表示结果(emb)和映射地址(addr)。
使用tf.get_collection("ASCEND_SPARSE_LOOKUP_LOCAL_EMB")接口获取训练用的嵌入表示结果,使用tf.get_collection("ASCEND_SPARSE_LOOKUP_ID_OFFSET")接口获取训练用的映射地址。
- 反向梯度计算。
使用tf.gradients(loss, emb)接口对3获取的嵌入表示结果求导,得到梯度(grad)。
- 反向稀疏表更新。
使用2.sparse优化器导入。创建的sparse_optimizer.apply_gradients([grad, addr])接口对映射地址地址对应位置的稀疏表进行更新。
示例代码
- 初始化框架。
use_dynamic_expansion = bool(int(os.getenv("USE_DYNAMIC_EXPANSION", 0))) init(use_mpi, train_steps=args.train_steps, eval_steps=args.eval_steps, use_dynamic_expansion=use_dynamic_expansion) - 稀疏优化器导入。
def get_dense_and_sparse_optimizer(cfg): dense_optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=cfg.learning_rate) use_dynamic_expansion = get_use_dynamic_expansion() if use_dynamic_expansion: sparse_optimizer = create_hash_optimizer_by_address(learning_rate=cfg.learning_rate) logging.info("optimizer lazy_adam_by_addr") else: sparse_optimizer = create_hash_optimizer(learning_rate=cfg.learning_rate) logging.info("optimizer lazy_adam") return dense_optimizer, sparse_optimizer - 获取嵌入表示结果和映射地。
train_emb_list = tf.compat.v1.get_collection(ASCEND_SPARSE_LOOKUP_LOCAL_EMB) train_address_list = tf.compat.v1.get_collection(ASCEND_SPARSE_LOOKUP_ID_OFFSET)
- 反向梯度计算。
local_grads = tf.gradients(loss, train_emb_list) # local_embedding
- 反向稀疏表更新。
grads_and_vars = [(grad, address) for grad, address in zip(local_grads, train_address_list)] train_ops.append(sparse_optimizer.apply_gradients(grads_and_vars))
父主题: 训练功能特性流程
