接口调用介绍
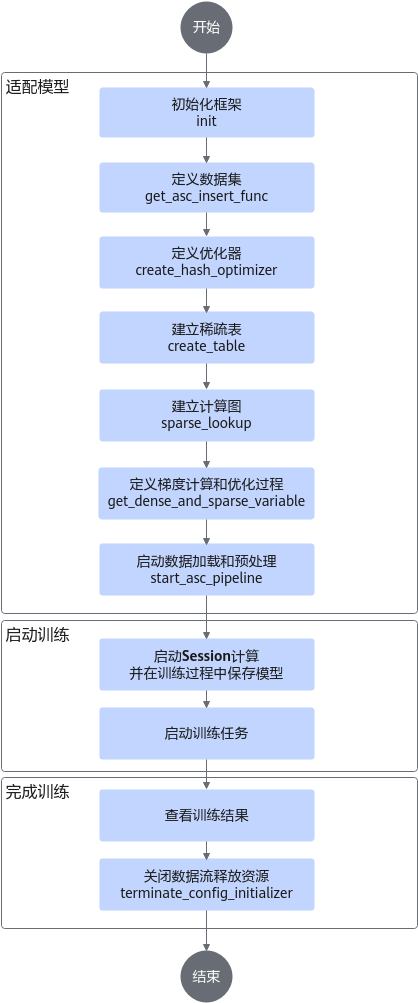
- 初始化框架。在main.py中调用init接口,传入初始化框架需要的相关参数。相关参数请参见init。
# nbatch function needs to be used together with the prefetch and host_vocabulary_size != 0 init(max_steps=max_steps, train_steps=TRAIN_steps, eval_steps=EVAL_STEPS, save_steps=SAVE_STEPS, use_dynamic=use_dynamic, use_dynamic_expansion=use_dynamic_expansion) - 定义数据集。在main.py中调用get_asc_insert_func接口,创建数据集并对数据集进行预处理。相关参数请参见参数说明。
if not MODIFY_GRAPH_FLAG: insert_fn = get_asc_insert_func(tgt_key_specs=feature_spec_list, is_training=is_training, dump_graph=dump_graph) dataset = dataset.map(insert_fn) dataset = dataset.prefetch(100) iterator = dataset.make_initializable_iterator() batch = iterator.get_next() return batch, iterator - 定义优化器。在optimizer.py中定义优化器,支持的优化器类型和相关参数请参见优化器。
# coding: UTF-8 import logging import tensorflow as tf from mx_rec.optimizers.lazy_adam import create_hash_optimizer from mx_rec.optimizers.lazy_adam_by_addr import create_hash_optimizer_by_address from mx_rec.util.initialize import get_use_dynamic_expansion def get_dense_and_sparse_optimizer(cfg): dense_optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=cfg.learning_rate) use_dynamic_expansion = get_use_dynamic_expansion() if use_dynamic_expansion: sparse_optimizer = create_hash_optimizer_by_address(learning_rate=cfg.learning_rate) logging.info("optimizer lazy_adam_by_addr") else: sparse_optimizer = create_hash_optimizer(learning_rate=cfg.learning_rate) logging.info("optimizer lazy_adam") return dense_optimizer, sparse_optimizer - 建立稀疏表。在main.py中调用create_table接口,建立稀疏表,创建稀疏网络层。相关参数请参见参数说明。
user_hashtable = create_table(key_dtype=tf.int64, dim=tf.TensorShape([cfg.user_hashtable_dim]), name='user_table', emb_initializer=tf.compat.v1.truncated_normal_initializer(), device_vocabulary_size=cfg.user_vocab_size * 10, host_vocabulary_size=0) # cfg.user_vocab_size * 100, # for h2d test item_hashtable = create_table(key_dtype=tf.int64, dim=tf.TensorShape([cfg.item_hashtable_dim]), name='item_table', emb_initializer=tf.compat.v1.truncated_normal_initializer(), device_vocabulary_size=cfg.item_vocab_size * 10, host_vocabulary_size=0) # cfg.user_vocab_size * 100, # for h2d test - 建立计算图。传入稀疏网络层和特征列表,创建模型计算图,在计算图中调用sparse_lookup进行特征查询和误差计算。相关参数请参见参数说明。
def model_forward(input_list, batch, is_train, modify_graph, config_dict=None): embedding_list = [] feature_list, hash_table_list, send_count_list = input_list for feature, hash_table, send_count in zip(feature_list, hash_table_list, send_count_list): access_and_evict_config = None if isinstance(config_dict, dict): access_and_evict_config = config_dict.get(hash_table.table_name) embedding = sparse_lookup(hash_table, feature, send_count, is_train=is_train, access_and_evict_config=access_and_evict_config, name=hash_table.table_name + "_lookup", modify_graph=modify_graph, batch=batch) reduced_embedding = tf.reduce_sum(embedding, axis=1, keepdims=False) embedding_list.append(reduced_embedding) my_model = MyModel() my_model(embedding_list, batch["label_0"], batch["label_1"]) return my_model - 定义梯度计算和优化过程。在main.py中调用get_dense_and_sparse_variable接口,得到密集网络层和稀疏网络层的参数,通过优化器计算梯度并执行优化。接口说明请参见get_dense_and_sparse_variable。
train_iterator, train_model = build_graph([user_hashtable, item_hashtable], is_train=True, feature_spec_list=train_feature_spec_list, config_dict=ACCESS_AND_EVICT, batch_number=cfg.batch_number) eval_iterator, eval_model = build_graph([user_hashtable, item_hashtable], is_train=False, feature_spec_list=eval_feature_spec_list, config_dict=ACCESS_AND_EVICT, batch_number=cfg.batch_number) dense_variables, sparse_variables = get_dense_and_sparse_variable() - 启动数据加载和预处理。在main.py中调用modify_graph_and_start_emb_cache(改图模式)/start_asc_pipeline(非改图模式)接口,启动数据流水线(示例代码中使用if判断配置文件中的MODIFY_GRAPH_FLAG来控制是否使用改图模式)。接口说明请参见modify_graph_and_start_emb_cache。
saver = tf.compat.v1.train.Saver() if MODIFY_GRAPH_FLAG: logging.info("start to modifying graph") modify_graph_and_start_emb_cache(dump_graph=True) else: start_asc_pipeline() with tf.compat.v1.Session(config=sess_config(dump_data=False)) as sess: if MODIFY_GRAPH_FLAG: sess.run(get_initializer(True)) else: sess.run(train_iterator.initializer) sess.run(tf.compat.v1.global_variables_initializer()) EPOCH = 0 if os.path.exists(f"./saved-model/sparse-model-{rank_id}-%d" % 0): saver.restore(sess, f"./saved-model/model-{rank_id}-%d" % 0) else: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=0) for i in range(1, 201): logging.info(f"################ training at step {i} ################") try: sess.run([train_ops, train_model.loss_list]) except tf.errors.OutOfRangeError: logging.info(f"Encounter the end of Sequence for training.") break else: if i % TRAIN_INTERVAL == 0: EPOCH += 1 evaluate() if i % SAVING_INTERVAL == 0: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) - 启动Session计算并在训练过程中保存模型。在main.py中调用saver接口,启动Session计算并在训练过程中保存模型。
saver = tf.compat.v1.train.Saver() if MODIFY_GRAPH_FLAG: logging.info("start to modifying graph") modify_graph_and_start_emb_cache(dump_graph=True) else: start_asc_pipeline() with tf.compat.v1.Session(config=sess_config(dump_data=False)) as sess: if MODIFY_GRAPH_FLAG: sess.run(get_initializer(True)) else: sess.run(train_iterator.initializer) sess.run(tf.compat.v1.global_variables_initializer()) EPOCH = 0 if os.path.exists(f"./saved-model/sparse-model-{rank_id}-%d" % 0): saver.restore(sess, f"./saved-model/model-{rank_id}-%d" % 0) else: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=0) for i in range(1, 201): logging.info(f"################ training at step {i} ################") try: sess.run([train_ops, train_model.loss_list]) except tf.errors.OutOfRangeError: logging.info(f"Encounter the end of Sequence for training.") break else: if i % TRAIN_INTERVAL == 0: EPOCH += 1 evaluate() if i % SAVING_INTERVAL == 0: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) - 关闭数据流释放资源。在main.py中调用terminate_config_initializer,关闭数据流释放资源。接口说明请参见terminate_config_initializer。
terminate_config_initializer() logging.info("Demo done!")
父主题: 快速入门