张量运算
功能介绍
使用Vision SDK张量运算功能,给定已赋值的输入张量并给输出张量分配好内存,调用张量运算接口执行相应运算并将计算结果值赋给输出张量。
接口调用流程
调用张量运算接口前,先创建好输入、输出张量,并分配好内存,同时,输入张量需要赋值。
输入输出数据类型必须保持一致。
对于四则运算和位运算,需保持输入、输出张量形状完全一致;对于张量转置、旋转、通道拆分、通道合并、裁剪和扩展接口,输入输出张量形状遵循相应的计算规范。
具体接口功能请参见“TensorOperations”章节。
以Add为例,张量运算调用流程参考如下:
图1 张量方法接口调用流程
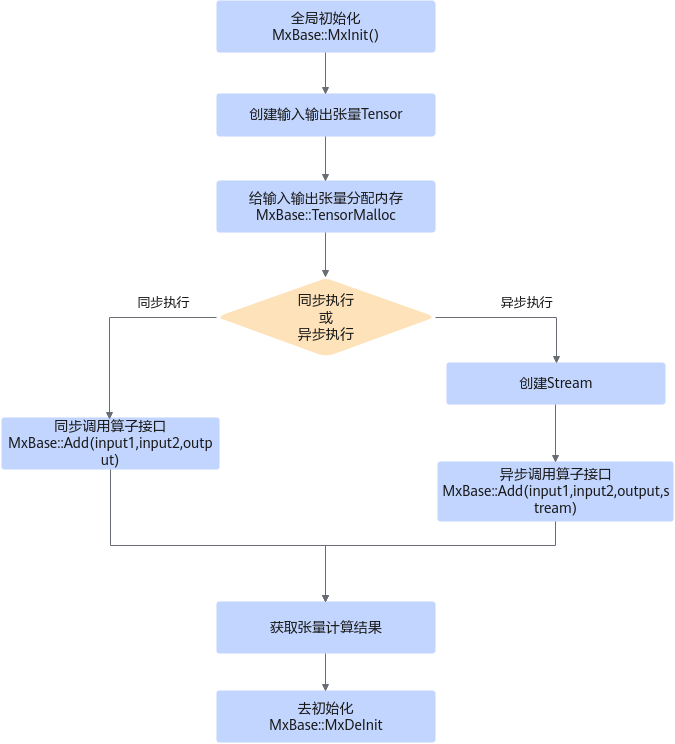
关键步骤说明如下:
- 调用MxInit()接口进行全局初始化。
- 张量初始化和内存分配,用户需对输入输出进行初始化和内存分配。
- 对于输入张量,需要创建好张量的数据,并传入张量形状、类型进行初始化,也可同时指定张量所在Device。
- 对于输出张量,传入张量形状、类型进行初始化,也可同时指定张量所在Device,并调用Tensor.Malloc()接口给张量分配内存。
- 对于未在初始化时指定Device的张量,需在初始化后使用ToDevice(int DeviceId)方法将张量放在指定Device侧进行运算。
- 选择执行方式进行张量计算,请根据实际业务选择同步调用算子接口或异步调用算子接口。
- 同步执行。
- 不创建Stream,将输入张量传入Add方法,获取张量相加计算结果。
- 异步执行。
- 创建Stream,具体请参见异步调用。
- 将输入张量、已创建的Stream及其他参数传入Add方法,获取张量相加计算结果。
- 同步执行。
- 调用MxDeInit()接口对初始化的全局资源进行去初始化。
示例代码
以下为以张量加法接口为例的功能特性关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
- 同步调用。
//初始化 MxBase::MxInit(); { // 1. 张量初始化 // 1.1 用户创建输入张量的数据 uint8_t input1[1][3][16][16]; uint8_t input2[1][3][16][16]; for (int i = 0; i < 1; i++) { for (int j = 0; j < 3; j++) { for (int k = 0; k < 16; k++) { for (int l = 0; l < 16; l++) { input1[i][j][k][l] = 8; input2[i][j][k][l] = 2; } } } } // 1.2 用户指定张量形状 std::vector<uint32_t> shape{1, 3, 16, 16}; // 1.3 用户创建输入输出张量对象 MxBase::Tensor tensor1(&input1[0][0][0][0], shape, MxBase::TensorDType::UINT8); MxBase::Tensor tensor2(&input2[0][0][0][0], shape, MxBase::TensorDType::UINT8); MxBase::Tensor tensor3(shape, MxBase::TensorDType::UINT8); tensor3.Malloc(); tensor1.ToDevice(device_id); tensor2.ToDevice(device_id); tensor3.ToDevice(device_id); // 2. 调用算子接口,tensor3即为算子计算输出结果 APP_ERROR ret = MxBase::Add(tensor1, tensor2, tensor3) } //去初始化 MxBase::MxDeInit(); - 异步调用。
//初始化 MxBase::MxInit(); { // 1. 创建流及线程注册 // 1.1 创建流 MxBase::AscendStream stream = AscendStream(deviceId); // 1.2 流的线程注册 stream.CreateAscendStream(); // 2. 张量初始化 // 2.1 用户创建输入张量的数据 uint8_t input1[1][3][16][16]; uint8_t input2[1][3][16][16]; for (int i = 0; i < 1; i++) { for (int j = 0; j < 3; j++) { for (int k = 0; k < 16; k++) { for (int l = 0; l < 16; l++) { input1[i][j][k][l] = 8; input2[i][j][k][l] = 2; } } } } // 2.2 用户指定张量形状 std::vector<uint32_t> shape{1, 3, 16, 16}; // 2.3 用户创建输入输出张量对象 MxBase::Tensor tensor1(&input1[0][0][0][0], shape, MxBase::TensorDType::UINT8); MxBase::Tensor tensor2(&input2[0][0][0][0], shape, MxBase::TensorDType::UINT8); MxBase::Tensor tensor3(shape, MxBase::TensorDType::UINT8); tensor3.Malloc(); tensor1.ToDevice(device_id); tensor2.ToDevice(device_id); tensor3.ToDevice(device_id); // 3. 调用算子接口,tensor3即为算子计算输出结果 APP_ERROR ret = MxBase::Add(tensor1, tensor2, tensor3, stream) // 4. 流的同步,获取计算结果 stream.Synchronize(); // 5. 流的销毁 stream.DestroyAscendStream(); } //去初始化 MxBase::MxDeInit();
父主题: 通过张量方法进行图像处理(Tensor)