手动配比调优
手动配比调优操作步骤如下所示。
- 修改MindIE Server的config.json文件的部分参数如下所示配置,更多参数的配置请参见性能调优流程。
- 对于短输入数据集:“maxPrefillBatchSize”可以设置大一些,比如设置为10;
- 对于中长输入数据集:“maxPrefillBatchSize”可以设置为1,以降低首token时延;“maxBatchSize”可以设置的大一些,比如设置为50。
"ModelDeployConfig": { "maxSeqLen" : 9728, "maxInputTokenLen" : 8704, "truncation" : false, "ModelConfig" : [ { "modelInstanceType": "Standard", "modelName" : "llama3_8b", "modelWeightPath" : "/home/data/llama3-8B", "worldSize" : 1, "cpuMemSize" : 40, "npuMemSize" : 11, "backendType": "atb" } ] }, "ScheduleConfig": { "templateType": "Standard", "templateName" : "Standard_LLM", "cacheBlockSize" : 128, "maxPrefillBatchSize" : 1, "maxPrefillTokens" : 9728, "prefillTimeMsPerReq" : 1000, "prefillPolicyType" : 0, "decodeTimeMsPerReq" : 50, "decodePolicyType" : 0, "maxBatchSize" :50, "maxIterTimes" : 1024, "maxPreemptCount" : 0, "supportSelectBatch" : false, "maxQueueDelayMicroseconds" : 5000 } - 配置完成后,用户可使用Linux curl命令、Postman工具、Benchmark工具等方式发送推理请求,此处以MindIE Benchmark命令为例进行说明。
benchmark \ --DatasetPath "/{数据集路径}/GSM8K" \ //数据集路径 --DatasetType "gsm8k" \ //数据集类型 --ModelName LLaMa3-8B \ //模型名称 --ModelPath "/{模型路径}/LLaMa3-8B" \ //模型路径 --TestType client \ //模式选择 --Http https://{ipAddress}:{port} \ //请求url --ManagementHttp https://{managementIpAddress}:{managementPort} \ //管理面url --Concurrency 1000 \ //并发数 --RequestRate 5 //请求频率 --TaskKind stream \ //Client不同推理模式,此处为文本流式推理 --Tokenizer True \ //分词向量化标识 --MaxOutputLen 512 //最大输出长度 - 首先使用PD配比为1:1进行测试,根据测试的Prefill和Decode时延结果,不断调整PD配比达到最优配比即可。
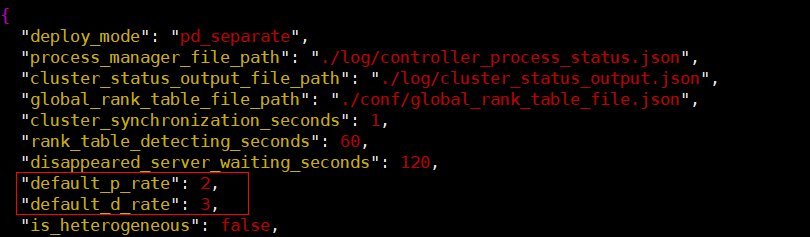
手动调整PD配比需要配置Controller配置文件中的两个参数“default_p_rate”和“default_d_rate”,如果要配置PD配比为2:3,那么相应的“default_p_rate”和“default_d_rate”参数配置如下所示。
 根据首token时延和Decode时延的实际数据,最多出现下面四种情况,根据实际结果调整参数:
根据首token时延和Decode时延的实际数据,最多出现下面四种情况,根据实际结果调整参数:- 首token时延和Decode时延都没超过约束阈值,则加大“RequestRate”的值即可。
- 首token时延和Decode时延都超过约束阈值,则减小RequestRate即可。
- 首token时延超过约束阈值,说明Prefill节点的数量匹配不上Decode节点的数量,可以适当增加Prefill节点的数量以降低首token时延。
- Decode时延超过约束阈值,说明Decode节点的数量匹配不上Prefill节点的数量,可以适当增加Decode节点的数量以降低Decode时延。
- 确定好最佳PD配比后,Prefill和Decode时延理论上可以同时接近时延约束,因此不断调整“requestRate”参数的值获得满足时延约束下的最大吞吐。
首token时延约束1000ms,Decode时延约束50ms的情况下,调优后两者比较理想的数值如下图所示,更多手动PD配比调优示例如表1所示。
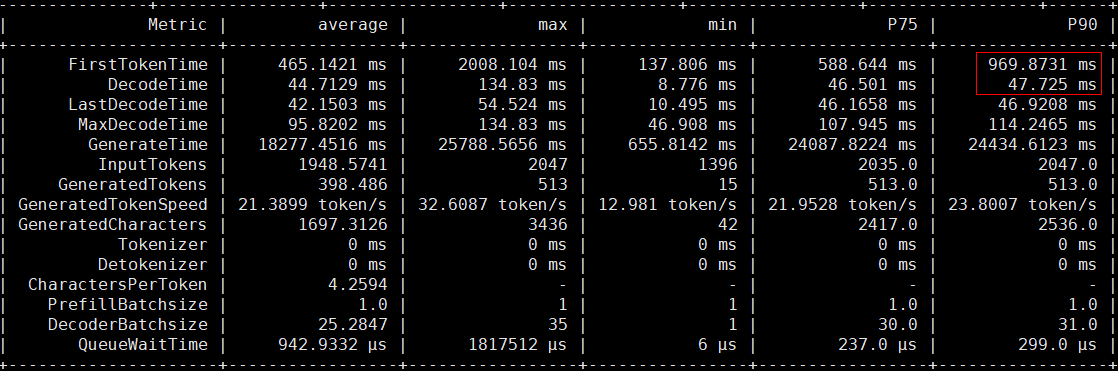
表1 PD配比调优示例 模型
数据类型
平均输入长度
平均输出长度
首token时延约束
Decode时延约束
初始配比
示例调优后配比
llama3-8b
short
258
59
500
50
1:1
2:3
medium1
1995
369
1000
50
1:1
2:3
medium2
957
114
500
50
1:1
1:3
long
6813
932
3000
50
1:1
1:5
llama3-70b
short
258
59
500
50
1:1
1:2
medium1
1995
369
1000
50
1:1
1:2
medium2
957
114
500
50
1:1
1:2
long
6813
932
3000
50
1:1
1:2
父主题: PD配比调优