'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
分析结果展示
维度一:分析向量运算
通过分析仿真dump文件:
- 算子Vector执行效率偏低时,找出执行效率低的Vector向量指令。
- mte2搬运粒度较低导致Vector计算的输入数据较少。
- 是否使能多核资源。
- 多核场景下,核之间的Vector计算量是否分配均衡。
分析结果如下:

在Vector Bound展示结果任意一行右键可选择跳转到“TIK Code”或“CCE Code”中算子对应的位置;当算子为非TIK算子时,无“TIK Code”跳转功能;另外“CCE Code”代码跳转功能依赖于.cce和.asm文件,当工程目录(默认为out>bin>kernel_meta)下这两个文件缺少任意一个,无跳转功能。如图2所示。.asm文件在执行算子UT测试后自动生成,.cce文件的生成请参见设置代码跳转功能进行配置。

字段 |
说明 |
|---|---|
Vector Bound |
分析向量运算。 |
Instruction |
指令名称。 |
First PC |
指令地址,根据取值仿真dump文件中可搜索到对应的重复向量指令。 |
Execution Times |
向量指令被重复执行的次数。 |
Repeat |
即repeat_times参数,表示一条向量指令的重复迭代次数,取值范围为(0,255]。 |
Mask |
向量内参与计算的元素,取值范围为[1,128],单位为bits。每一个bit位用来表示vector的每个元素是否参与操作,bit位的值为1表示参与计算,0表示不参与计算。 |
有关该算子优化分析的具体参数应用请参见《算子开发指南》中的“接口参考>TBE TIK API>矢量计算>单目”章节。
优化建议:
- Try to optimize vector instructions.
- Try to optimize out->ub data move instructions.
- Try to use multi-core resources.
- Try to reallocate vector calculations to these cores: 0 1.
优化Vector指令可以通过修改向量指令参数mask和repeat_times,替代重复执行的向量指令。
根据字段First PC的值从仿真dump文件中可搜索到对应的重复向量指令,如上图所示Execution Times取值为64,Repeat取值为1,Mask取值为64,则该指令被重复执行了10次,而一次执行只进行了一次迭代计算,每次只计算了该向量中的一位元素。那么为了提高该指令的执行效率,可以通过修改算子代码中的repeat_times参数值为10,最后根据向量位数以及实际需求修改mask的值,修改后该指令只需执行一次即可完成10次迭代计算并且每次计算都完成向量在场景下要求计算的所有元素,从而提升该条指令执行的效率。
维度二:分析流水打断
根据仿真dump文件,针对占比最大的流水进行分析,主要从三个维度进行:
- 其它流水导致的流水不连续。
- 指令入队列导致的流水不连续。
- pipe_barrier(PIPE_ALL)导致的流水打断。
根据分析的结果,对上述三个维度造成影响的周期数进行排序,结果展示如下:
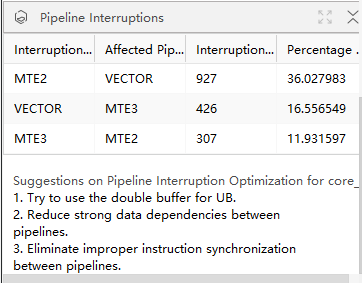
字段 |
说明 |
|---|---|
Pipeline Interruption |
分析流水打断。 |
Interruption Factor |
流水打断因素。 |
Affected Pipeline |
受影响的流水。 |
Interruption Cycles |
流水打断的周期数。 |
Percentage to Total |
打断周期数占总周期数的百分比。 |
优化建议:
维度三:分析标量运算
根据仿真dump文件,统计Scalar标量指令执行次数和总的执行周期,按总的执行周期的大小进行排序,选出Top5个Scalar标量指令,分析结果如下:

字段 |
说明 |
|---|---|
Scalar Bound |
分析标量运算。 |
Instruction |
指令名称。 |
Execution Times |
标量指令被重复执行的次数。 |
Execution Cycles |
标量指令的总执行周期。 |
优化建议:
- Try to adjust tiling policy.
- Try to optimize the implementation solution.
- Try to replace instructions with poor performance.
维度四:Memory bound
通过分析仿真dump文件,找出内存搬运类性能瓶颈:
- 小包搬运:在算子一次运算内若没有达到OUT->UB/UB->OUT/L1->UB通道阈值,则判定为小包搬运。
OUT->UB/UB->OUT/L1->UB通道阈值为:Vector最大一次运算可以计算两个128长度的fp16类型向量相加或相乘,即128 * 2 * 2B = 512B。
- 冗余搬运:计算冗余度 = 搬运量 / 计算量,冗余度大于1.2则存在冗余搬运。
搬运量为OUT->UB搬运量,计算量为VECTOR计算量。
- 带宽抢占:分析OUT->UB/OUT->L1搬运指令的运行时间是否存在重合,找出可能存在的mte2带宽抢占。
分析结果如下:
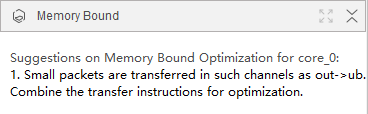
优化建议:
- Small packets are transferred in such channels as out->ub. Combine the transfer instructions for optimization.
- Redundant transfer exists. Optimize the data transfer policy.
- Bandwidth preemption exists. Adjust the transfer instruction sequence.
