'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
基于Timeline的AI CPU算子优化分析样例
背景介绍
AI CPU是昇腾AI处理器计算单元,因为该CPU计算处理单位自身瓶颈,导致运行在AI CPU上的算子影响模型的执行时间。AI CPU算子的优化往往是重点关注点和优化对象。本节以MLP模型为例,介绍通过专家系统AI CPU识别功能, 自动识别串行执行AI CPU算子,给出优化建议,提升模型整体性能。
专家系统操作




问题分析
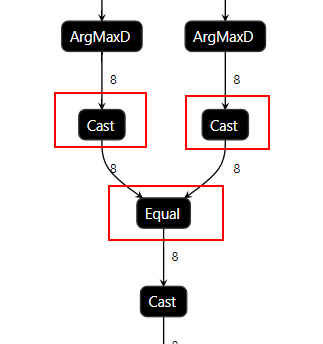
根据专家系统AI CPU算子识别的推荐结果,发现计算图中两个Cast算子和Equal算子都在AI CPU上执行,需要考虑将Cast算子和Equal算子在AI CPU上消除。
由于Cast算子的作用是将算子输出结果进行格式转换,且在AI Core上的运算仅支持32位及以下的数据类型,根据图4,可推测下层的Equal算子数据类型应该在32位以上,所以生成了负责数据格式转换的Cast算子且这两个算子转移到了AI CPU上进行运算。
问题解决
根据图3优化建议“3. Change the model structure, for example, from INT64 to FP16.(更改模型结构,如:INT64转FP16。)”。
可将Equal算子数据类型修改为与上层ArgMaxD算子一样的数据类型,即可消除掉Cast算子并将Equal算子转移回AI Core上运算。
修改Equal算子后再次进行专家系统分析可以发现Cast算子和Equal算子已不在AI CPU算子优化分析结果中,同时还输出UB融合推荐发现还可以对ArgMaxD和Equal算子进行融合,进一步提升效率。相关分析方式请参见UB算子融合推荐分析样例。
结论
通过专家系统工具的分析,可以快速找出AI CPU算子。并根据专家系统的提示,结合实际的网络模型实际特点,对问题分析后得到解决方案。提升了网络性能问题分析效率。
父主题: 专家系统分析样例参考
