'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
子模型导出与比对
概述
在使用昇腾AI处理器的推理功能时,可能存在推理结果和原始模型推理结果不一致的情况,使用精度比对工具可以定位到某个或者某些非用户自定义层出现精度下降的问题,此时需要用户将怀疑有问题的局部网络的相关数据截取出来进行局部结构精度比对,在该背景下,MindStudio提供Caffe和TensorFlow原始网络模型的子模型导出功能方便用户获取数据,导出原理如图1所示。

导出入口
在MindStudio界面,依次单击菜单栏,进入子模型导出界面。
导出步骤
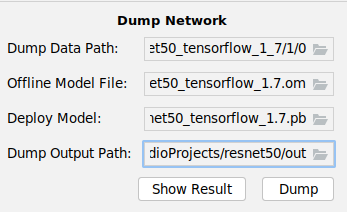
- 在MindStudio界面菜单栏选择进入子模型导出界面,如图2所示。
表1 界面参数以及按钮说明 参数
说明
Dump Data Path
精度比对界面“NPU Dump”中配置的离线模型对应的dump数据。单击右侧的
 选择dump目录。
选择dump目录。Offline Model File
精度比对界面“Model File”中配置的离线模型文件。单击右侧的
 选择离线模型文件。
选择离线模型文件。Deploy Model
- 原始网络模型文件,单击右侧的
 选择MindStudio安装服务器相应文件。
选择MindStudio安装服务器相应文件。 - 如果为昇腾模型压缩工具量化后的模型文件,则此处需要选择量化后可在昇腾AI处理器部署的模型文件。
Deploy Weight
- 原始网络模型权重文件,若模型文件与权重文件在MindStudio安装服务器相同位置,选择模型文件后,权重文件会自动填充,否则需要用户单击右侧的
 自行选择。
自行选择。 - 如果为昇腾模型压缩工具量化后的权重文件,则此处需要选择量化后可在昇腾AI处理器部署的权重文件。
说明:
只有原始网络模型文件为Caffe模型时,才会显示并需要添加Caffe模型权重文件(*.caffemodel)。
Dump Output Path
子模型导出目录,单击右侧的
 选择导出目录,若没有目录,请先自行创建。
选择导出目录,若没有目录,请先自行创建。Show Result
单击该按钮,会解析原始模型文件,并将解析后的结果以图的形式呈现在右侧空白区域。
Dump
子模型导出按钮。
- 原始网络模型文件,单击右侧的
- 配置好参数后,单击“Show Result”,解析原始网络模型。
如果模型转换后导出的.om模型文件中的原模型“Model Name”取值与Caffe原始网络模型文件(*.prototxt)或者TensorFlow原始网络模型文件(*.pb)中的“Model Name”取值不同时,解析网络模型时会弹出如图3所示界面。
- 单击“Yes”继续解析,进入图4。
- 单击“No”,返回子模型导出界面。
解析成功的原始网络模型如图4所示。其中:- 查看算子信息
单击图4中间区域框下方相关参数左侧的展开按钮
 ,查看参数的详细信息;单击
,查看参数的详细信息;单击 折叠所有的算子信息。
折叠所有的算子信息。 - 查看算子输出shape信息
图4还展示了每一层算子输出的维度和shape信息,如每一层算子连接线中间的NCHW,1,3,224,224等信息。
- 搜索算子
在图4所示界面,中间下方为搜索区域。
搜索区域中给出了该模型所用到的所有算子,您可以在搜索区域对话框中输入算子名称,下方搜索区域会列出相关的算子。选择其中一个算子,左侧网络拓扑结构中相应算子会显示绿色选中框,中间区域框上方会展示该层算子的详细信息,包括算子名称、算子输入、输出等信息。
图5 搜索算子内部信息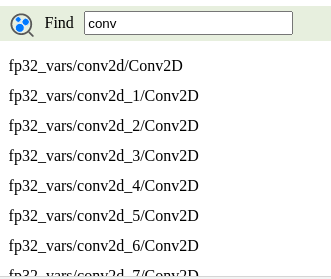
- 搜索算子内部信息
在图4中的
 输入框输入想要查询的信息,之后单击
输入框输入想要查询的信息,之后单击 即可逐个查找。
即可逐个查找。
- 选中怀疑有问题的局部网络模型第一个节点(输入节点),右键选择;选中最后一个节点(输出节点)右击选择,与中间的节点则为蓝色选中状态。
- 选中了输入和输出节点后,如果想更换输入或输出节点,则在新的节点上右击选择相应的属性即可,新的节点颜色随之变化,原有节点恢复原始颜色。
- 如果在某个节点选择,并在该节点上方节点选择,则无法选择。
- 确定输入节点和输出节点后,单击“Dump”导出子模型。
MindStudio后台会在原始网络模型中寻找子模型,然后将子模型导出。界面右下角会有导出进度提示,单击该进度条可以查看详细进度。
若出现图6所示信息,则说明导出成功。


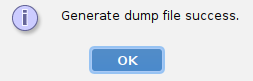
查看导出成功后结果
- 进入MindStudio安装服务器“Dump Output Path”所在目录可以看到以时间戳命名的文件夹dump_result_xxxx_xx_xx_xx_xx_xx,其中:
- dump.prototxt:导出的Caffe子模型文件。
- dump.pb:导出的TensorFlow子模型文件。
- dump.caffemodel:导出的子模型权重文件(Caffe模型特有)。
- dump_data:选中的与中间,子模型所包括的所有算子的dump数据信息。
该文件夹中不仅包括导出子模型所包括的所有算子的dump信息,还包括子模型层的输入数据,用于子模型推理时作为输入数据使用。
- MindStudio界面“Output”窗口可以看到导出日志(如下日志中的所有数据都为样例数据,请以实际导出模型为准):
//导出过程中会为子模型添加输入信息 2020-05-22 16:27:57 Add Layer Into Prototxt: name: "pool1_input_0" type: "Input" top: "conv1" input_param { shape { dim: 1 dim: 64 dim: 112 dim: 112 } } //导出子模型的所有算子的dump数据信息 2020-05-22 16:27:57 Output Dump Path:/home/username/dumpdate/dumpresult/ir6/dump_result_2020_05_22_16_27_44/dump_data //Start Layer与End Layer中间某层算子的dump信息,其中Output File表示Dump Layer层算子对应离线模型中相应算子的输出dump数据,Input File表示Dump Layer层算子对应的离线模型中相应算子的输入dump数据 2020-05-22 16:27:58 Dump Layer:[res2a_branch2c, bn2a_branch2c, scale2a_branch2c] Output File:Conv2D.res2a_branch2cres2ares2a_relu.151.1585884515795667 Input File:Conv2D.res2a_branch2bres2a_branch2b_relu.149.1585884515771632 ... //Start Layer与End Layer中间所有算子的dump信息 2020-05-22 16:27:58 Export Layer:pool1,res2a_branch1,bn2a_branch1,scale2a_branch1,res2a_branch2a,bn2a_branch2a,scale2a_branch2a,res2a_branch2a_relu,res2a_branch2b,bn2a_branch2b,scale2a_branch2b,res2a_branch2b_relu,res2a_branch2c,bn2a_branch2c,scale2a_branch2c,res2a,res2a_relu - 用户可以将导出的子模型再次进行精度比对,如果问题解决则进入下一步导出子模型重新执行推理验证。
导出子模型重新执行推理
- 将1导出的子模型,参见模型转换和调优转换成.om离线模型文件。
如果导出的子模型不包括输入的data层节点,则转换.om离线模型时,请关闭AIPP预处理参数。
- 将1导出的子模型“start”层的输入数据,转换成bin格式,用户执行推理时,作为离线模型的输入数据使用。
- 查找“start”层的输入数据。
输入数据为子模型导出时“Dump Layer”为“start”层算子对应的Input File文件,根据此信息,在MindStudio安装服务器“dump_data”目录下查找同名Input File文件,即为“start”层的输入数据。
- pb格式输入数据转成numpy格式。
进入MindStudio安装服务器,切换到Ascend-cann-toolkit安装目录/ascend-toolkit/latest/tools/operator_cmp/compare路径,执行如下命令将pb格式的输入数据转换成numpy格式:
python3 shape_conversion.py -i pb格式输入数据绝对路径 -format NCHW -o 转换为numpy格式数据的存放路径
上述命令中的路径请根据实际情况进行替换,转换完成后,可以在numpy格式数据的存放路径看到.npy格式的输入数据。
- numpy格式输入数据转成bin格式。
将如下脚本中的数据路径替换为实际路径,然后将脚本另存为.py格式,例如submodeldataprocess.py。
import numpy as np # 将numpy二进制格式转换为原始二进制格式 conv1_relu_0 = np.load( "/home/username/dumpdate/subModelData/xxx.npy") # .npy格式的输入数据的绝对路径 conv1_relu_0 = conv1_relu_0.astype(np.float16) conv1_relu_0.tofile( "/home/username/dumpdate/subModelData/xxx.bin") # 转换为bin格式数据的存放路径将submodeldataprocess.py脚本上传到MindStudio安装服务器任意路径,然后执行如下命令将.npy格式的输入数据转换成bin格式:
python3 submodeldataprocess.py
进入bin格式数据的存放路径,可以看到.npy格式的输入数据已经转换成bin格式。
- 查找“start”层的输入数据。
- 将导出的原始网络子模型在原始环境中执行推理业务,然后将1和2中的离线模型和输入数据在昇腾AI处理器执行推理业务,查看两者推理结果是否有差异。如果仍有差异,则参见精度比对使用1中导出的原始网络子模型与1原始网络子模型转换后的离线模型重新和原始模型标杆数据进行精度比对。
- 重复执行子模型导出与子模型精度比对,把问题定位到最小模型,针对最小模型进行优化。
