迁移操作
PyTorch GPU2Ascend提供脚本分析和迁移功能,帮助用户在执行分析迁移操作中,分析PyTorch训练脚本的算子和API支持情况,并将其迁移为基于NPU可运行的脚本。
迁移步骤
- 通过以下任一方式启动脚本迁移任务。
- 在工具栏选择。
- 单击工具栏中
 图标。
图标。 - 右键单击训练工程,然后选择“PyTorch GPU2Ascend”。
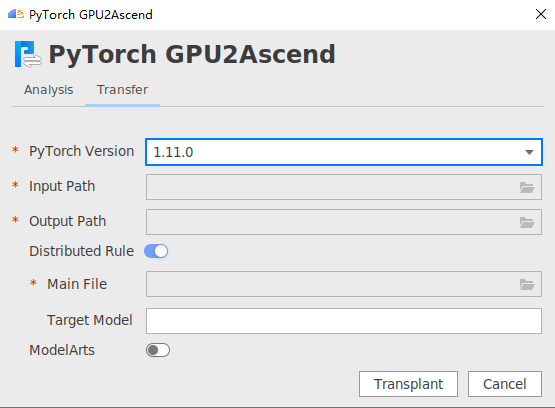
- 单击“Transfer”页签,进入迁移任务界面。
- 参数配置。
表1 Transfer参数配置 参数
参数说明
PyTorch Version
待迁移脚本的PyTorch版本。目前支持PyTorch1.11.0、2.1.0。
必选,默认为1.11.0。
Input Path
待迁移脚本文件所在目录。单击文件夹图标选择目录。必选。
Output Path
脚本迁移结果文件输出路径。单击文件夹图标选择目录。必选。
- 不开启“Distributed Rule”即迁移至单卡脚本场景下,输出目录名为xxx_msft。
- 开启“Distributed Rule”即迁移至多卡脚本场景下,输出目录名为xxx_msft_multi。
xxx为原始脚本所在文件夹名称。
Distributed Rule
将GPU单卡脚本迁移为NPU多卡脚本,此参数仅支持使用torch.utils.data.DataLoader方式加载数据的场景。可选。
开启后,需配置如下参数:
Main File:必选,单击文件夹图标选择训练脚本的入口Python文件。
Target Model:可选,待迁移脚本中的实例化模型变量名,默认为“model”。
如果变量名不为"model"时,则需要配置此参数,例如"my_model = Model()",需要配置为-t my_model。
- 单击“Transplant”,执行迁移任务。
完成后,Output Path输出目录下查看结果文件。
├── xxx_msft/xxx_msft_multi // 脚本迁移结果输出目录 │ ├── 生成脚本文件 // 与迁移前的脚本文件目录结构一致 │ ├── transplant_result_file //存放迁移结果文件 │ │ ├── msFmkTranspltlog.txt // 脚本迁移过程日志文件,日志文件限制大小为1M,若超过限制将分多个文件进行存储,最多不会超过10个 │ │ ├── cuda_op_list.csv //分析出的cuda算子列表 │ │ ├── unknown_api.csv //支持情况存疑的API列表 │ │ ├── unsupported_api.csv //不支持的API列表 │ │ ├── api_precision_advice.csv //API精度调优的专家建议 │ │ ├── api_performance_advice.csv //API性能调优的专家建议 │ │ ├── change_list.csv // 修改记录文件 │ ├── run_distributed_npu.sh // 多卡启动shell脚本
后续操作
- 为了提升模型运行速度,建议开启使用二进制算子,参考《CANN 软件安装指南》安装二进制算子包后,参考如下方式开启:
- 单卡场景下,修改训练入口文件例如main.py文件,在import torch_npu下方添加加粗字体信息。
import torch import torch_npu torch.npu.set_compile(jit_compile=False) ......
- 多卡场景下,如果拉起多卡训练的方式为mp.spawn,则torch.npu.set_compile(jit_compile=False)必须加在进程拉起的主函数中才能使能二进制,否则使能方式与单卡场景相同。
if is_distributed: mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args)) else: main_worker(args.gpu, ngpus_per_node, args) def main_worker(gpu, ngpus_per_node, args): # 加在进程拉起的主函数中 torch.npu.set_compile(jit_compile=False) ......
- 单卡场景下,修改训练入口文件例如main.py文件,在import torch_npu下方添加加粗字体信息。
- 如果启用了Distributed Rule参数,迁移后会生成如下run_distributed_npu.sh文件,在执行迁移后的模型之前需要把文件中的“please input your shell script here”语句替换成模型原来的训练shell脚本。执行run_distributed_npu.sh文件后会生成指定NPU的log日志。
export MASTER_ADDR=127.0.0.1 export MASTER_PORT=29688 export HCCL_WHITELIST_DISABLE=1 NPUS=($(seq 0 7)) export RANK_SIZE=${#NPUS[@]} rank=0 for i in ${NPUS[@]} do export DEVICE_ID=${i} export RANK_ID=${rank} echo run process ${rank} please input your shell script here > output_npu_${i}.log 2>&1 & let rank++ done表2 参数说明 参数
说明
MASTER_ADDR
指定训练服务器的IP
MASTER_PORT
指定训练服务器的端口号
HCCL_WHITELIST_DISABLE
hccl后端环境
NPUS
指定在特定NPU上运行
RANK_SIZE
指定调用卡的数量
DEVICE_ID
指定使用的device_id
RANK_ID
指定调用卡的逻辑ID
- 若用户训练脚本中包含昇腾NPU平台不支持的amp_C模块,需要用户手动删除后再进行训练。
- 若用户训练脚本中包含昇腾NPU平台不支持的torch.nn.DataParallel接口,需要手动修改成torch.nn.parallel.DistributedDataParallel接口执行多卡训练,参考迁移单卡脚本为多卡脚本进行修改。
- 若用户训练脚本中包含昇腾NPU平台不支持的torch.cuda.default_generators接口,需要手动修改为torch_npu.npu.default_generators接口。
- 若用户训练脚本中包含torch.cuda.get_device_capability接口,迁移后在昇腾AI处理器上运行时,会返回“None”值,如遇报错,需要用户将“None”值手动修改为固定值。torch.cuda.get_device_properties接口迁移后在昇腾AI处理器上运行时,返回值不包含minor和major属性,建议用户注释掉调用minor和major属性的代码。
- 分析迁移后可以参考模型训练进行训练。
父主题: PyTorch GPU2Ascend