TensorFlow训练/在线推理场景性能分析
TensorFlow训练/在线推理场景下,推荐通过TensorFlow Adapter提供的接口使能性能数据采集,然后将结果文件上传到安装有Ascend-cann-toolkit开发套件包的开发环境进行数据解析,进而分析性能瓶颈。
前提条件
- 请确保完成使用前准备。
- 训练脚本在昇腾AI处理器上执行成功。
采集、解析并导出性能数据
- 修改训练脚本,开启性能数据采集开关。
以TensorFlow 1.15 session_run模式的脚本为例。
通过session配置项profiling_mode、profiling_options开启Profiling数据采集,代码示例如下:custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["use_off_line"].b = True # 开启性能数据采集 custom_op.parameter_map["profiling_mode"].b = True # 性能数据采集项 # output为采集结果输出路径 # task_trace:是否采集任务轨迹数据 # training_trace:是否采集迭代轨迹数据,采集迭代轨迹数据依赖fp_point(训练网络迭代轨迹正向算子的开始位置)和bp_point(反向算子的结束位置),可直接配置为空,由系统自动获取,采集异常时需要手工配置。 custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes('{"output":"/home/HwHiAiUser/profiling_output","training_trace":"on","task_trace":"on","fp_point":"","bp_point":"","aic_metrics":"PipeUtilization"}') config.graph_options.rewrite_options.remapping = RewriterConfig.OFF #关闭remap开关 with tf.Session(config=config) as sess: sess.run()
- 以上为最基本的采集项,如有其他采集需求,请参见使用TensorFlow框架接口采集。
- Estimator和Keras脚本修改方式略有不同,手工迁移脚本和自动迁移脚本修改方式也略有不同,请参见使用TensorFlow框架接口采集。
- 重新执行训练脚本,将在训练过程中采集性能数据。
训练结束后,在output参数指定的目录下生成PROF_XXX文件夹用于存放采集到的原始性能数据,该数据需要经过msprof解析工具的解析才可查看。
- 执行msprof命令解析并导出性能数据。
msprof --export=on --output=/home/HwHiAiUser/profiling_output/PROF_XXX
其中“--output”为采集性能数据时设置的存储Profiling数据文件的路径。
命令执行完成后,在output指定的目录下生成PROF_XXX目录,存放采集并自动解析后的性能数据,目录结构如下所示(仅展示性能数据)。
├── device_{id} │ └── data └── mindstudio_profiler_output ├── msprof_{timestamp}.json ├── step_trace_{timestamp}.json ├── xx_*.csv ... └── README.txt - 进入mindstudio_profiler_output目录,查看性能数据文件。
默认情况下采集到的文件如表1所示。
表1 msprof默认配置采集的性能数据文件 文件名
说明
msprof_*.json
timeline数据总表。
step_trace_*.json
迭代轨迹数据,每轮迭代的耗时。单算子场景下无此性能数据文件。
op_summary_*.csv
AI Core和AI CPU算子数据。
op_statistic _*.csv
AI Core和AI CPU算子调用次数及耗时统计。
step_trace_*.csv
迭代轨迹数据。单算子场景下无此性能数据文件。
task_time_*.csv
Task Scheduler任务调度信息。
fusion_op_*.csv
模型中算子融合前后信息。单算子场景下无此性能数据文件。
api_statistic_*.csv
用于统计CANN层的API执行耗时信息。
prof_rule_0_*.json
调优建议。
注:“*”表示{timestamp}时间戳。

性能分析
从上文我们可以看到,性能数据文件较多,分析方法也较灵活,以下介绍几个重要文件及分析方法。
- 通过step_trace_*.csv文件分析迭代轨迹数据信息,该文件记录了每轮迭代的耗时时间。
主要字段为:
- Iteration Time:一轮迭代的计算时间,主要包含FP/BP和Grad Refresh两个阶段的时间。
- FP to BP Time:网络正向传播和反向传播的计算时间。
- Grad Refresh Bound:梯度更新时间。
- Data Aug Bound:两个相邻Iteration Time的间隔时间。
- 通过op_statistic_*.csv文件分析各类算子的调用总时间、总次数等,排查是否某类算子总耗时较长,进而分析这类算子是否有优化空间。
图3 op_statistic_*.csv文件示例
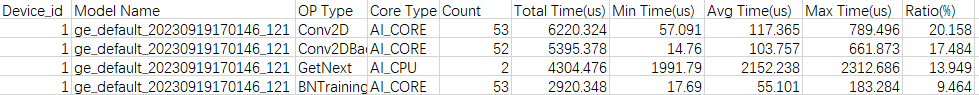
可以按照Total Time排序,找出哪类算子耗时较长。
- 通过op_summary_*.csv文件分析具体某个算子的信息和耗时情况,从而找出高耗时算子,进而分析该算子是否有优化空间。
图4 op_summary*.csv文件示例

Task Duration字段为算子耗时信息,可以按照Task Duration排序,找出高耗时算子;也可以按照Task Type排序,查看不同核(AI CORE和AI CPU等)上运行的高耗时算子。
